서론
컴퓨터의 역사에 관한 레포트를 쓰기 위해 학교 도서관에 왔다고 가정해봅니다.
많은 책들을 뽑아 책상에 앉아 자료 조사를 하는 도중, 컴퓨터에 대한 많은 내용을 찾았지만, 그 중 EDSAC에 대한 내용을 찾을 수가 없네요.
어쩔 수 없이 다시 서고로 가 EDSAC에 관한 책을 찾아왔습니다.
책상 위에 여러 권을 놓아두면, 한 권씩 가져와 비교하는 것보다는 많은 시간을 절약할 수 있게 된다는 거죠. 그러나 책상의 크기에는 한계가 있기 때문에 도서관에 있는 모든 책을 가져올 수는 없다는 거에요.
이는 메모리에서도 같은 흐름을 가진다는 겁니다.
RAM
- Random Access Memory
- 우리가 흔히 말하는 메모리가 바로 이 RAM을 지칭하는 것으로, 주 기억장치라고 합니다.
- SSD, HDD와 달리 전원이 꺼지면 저장된 데이터는 사라지게 되죠.
흐름
- CPU는 메모리로부터 명령어와 데이터를 가져와 실행하는데, RAM은 그 실행할 대상을 저장하고 있어야 하겠죠. 그런데 이 RAM은 전원이 꺼지면 저장한 내용을 잃어버리기 때문에, 대용량 저장장치로 보조 기억 장치가 있고, 이것이 바로 SSD, HDD입니다.
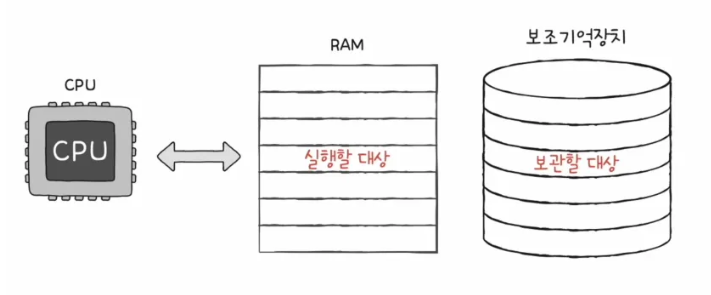
RAM의 용량과 성능
RAM이 크면 컴퓨터 성능에 어떤 영향을 미칠까?
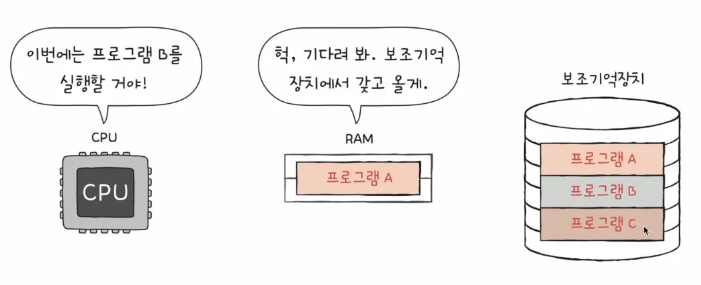
필자는 중학생 때부터 컴퓨터에 관심이 조금 있었기도 했고, 일반 사람들도 RAM은 많을수록 좋다. 일명 다다익램...이라고 한다. 그럼 왜 다다익램이라고 하는지를 이해할 필요가 있으니 한 상황을 가정해봅니다.
RAM의 용량이 작아서 딱 하나의 프로그램만을 불러와 저장할 수 있는 램이 있습니다.
CPU는 어찌됐든 RAM에서 가져와 실행을 해야하죠. 그렇기 때문에 프로그램 B를 실행하고자 한다면, 보조기억장치에서 프로그램 B를 RAM에 올리고, 이를 가져와 실행할 수 밖에 없겠죠. 다시 C를 실행하려면 이 과정을 반복해야하고요.
반대로 극단적으로 저장할 공간이 큰 RAM이 있다고 가정해봅니다.
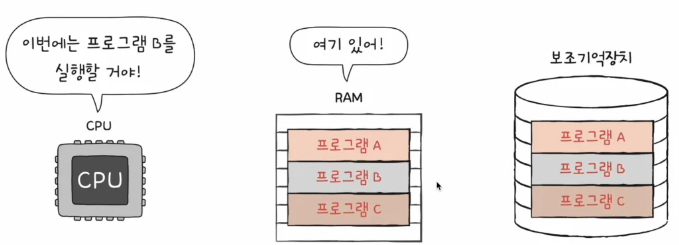
이미 RAM에 프로그램 A, B, C에 올라와 있어서 CPU가 뭘 원하든 보조기억장치까지 갔다올 필요가 없다는 거죠.
CPU가 RAM에서 즉각적으로 가져오냐, 아니면 보조기억장치까지 갔다가 돌아오느냐
| DRAM | SRAM | |
|---|---|---|
| 재충전 | 필요함 | 필요 없음 |
| 속도 | 느림 | 빠름 |
| 가격 | 저렴함 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 소비 전력 | 적음 | 높음 |
| 사용 용도 | 주기억장치(RAM) | 캐시 메모리 |
결국, 다다익램이라는 것은 어찌보면 당연한 소리가 되는거죠. 저장공간이 크니까 안에서 대기하고 있는 애들이 많으니까, 거기서 바로 꺼내올 수 있다.
Physical Address & Logical Address
그러면 CPU는 어떻게 메모리에 접근해서 실행할 프로그램을 가져올까?
기본적으로 CPU와 실행 중인 프로그램은 메모리 몇 번지에 무엇이 저장되어 있는지 다 알지 못한다. 메모리에 저장된 값들은 계속 변하기 때문에 그런 것인데, 전원이 꺼지면 프로그램이 날아가기도 하거니와, 계속 보조 기억 장치에 있는 프로그램과 스왑을 하기 때문에 그렇다.
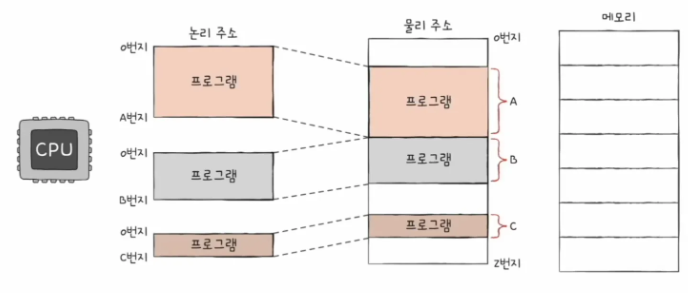
Physical Address
물리 주소
- 메모리 입장에서 바라본 주소
- 정보가 실제로 저장된 하드웨어 상의 주소
Logical Address
논리 주소
- CPU와 실행 중인 프로그램 입장에서 바라본 주소
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소
- MMU(메모리 관리 장치)라는 하드웨어에 의해 논리 주소가 물리 주소로 변환된다.
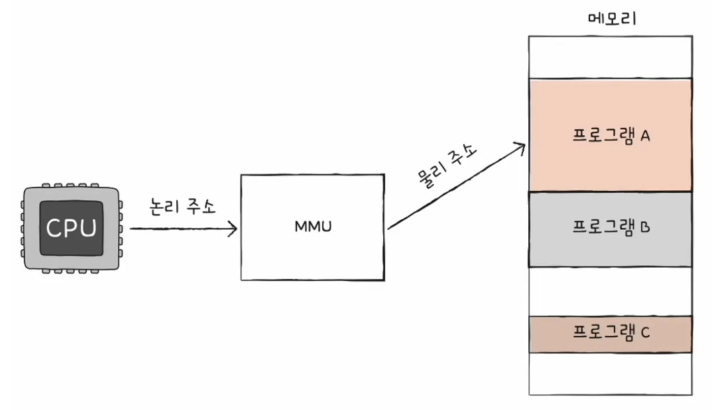
- MMU는 논리 주소와 베이스 레지스터 값을 더해 논리 주소를 물리 주소로 변환한다.
무슨 소리야? 라고 한다면, 다음과 같은 예시를 봅니다.
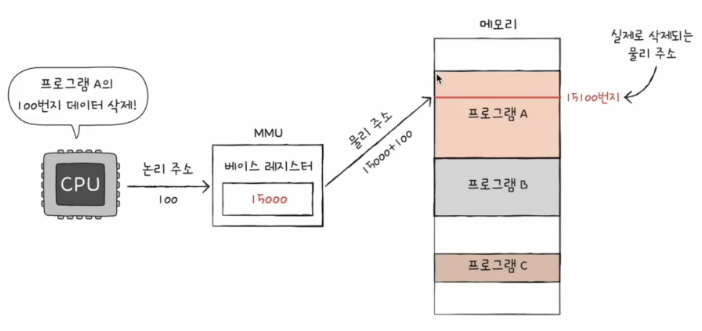
CPU는 프로그램 A의 100번지 데이터를 삭제하려고 합니다.
그런데 프로그램 A가 도대체 메모리 몇 번지에 있는지를 알 수가 없다는거죠.
이 때, MMU는 해당 프로그램 A가 어디에 있는지 베이스 레지스터로 알려주는 역할을 합니다. 여기서는 15000번지에 있다고 하네요. 그래서 MMU를 보고 "아, 메모리 15000 번지로 일단 가야겠다."라고 하면서 물리 주소로 접근합니다. 그 후에, 물리 주소에 도착했으면 "여기서 100걸음 걸어서 15100번지를 삭제 해야지."라고 하며, 15000번지에서 100을 더한 15100번지의 데이터를 삭제하게 됩니다.
즉, 기준 주소(베이스 레지스터)에서부터 얼마만큼 떨어진 곳인지를 파악해야 하죠.
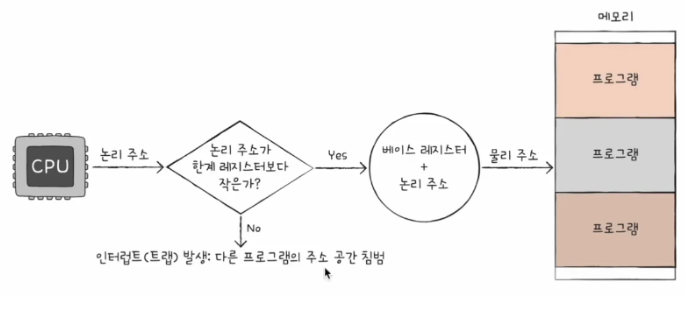
만일, 한 프로그램이 실행되는 영역을 벗어난 명령이 실행되면 이를 막을 필요가 있습니다. 이를 한계 레지스터로 보호할 수가 있어요.
한계 레지스터란, 프로그램의 영역을 침범하는 명령어의 실행을 막는 것입니다.
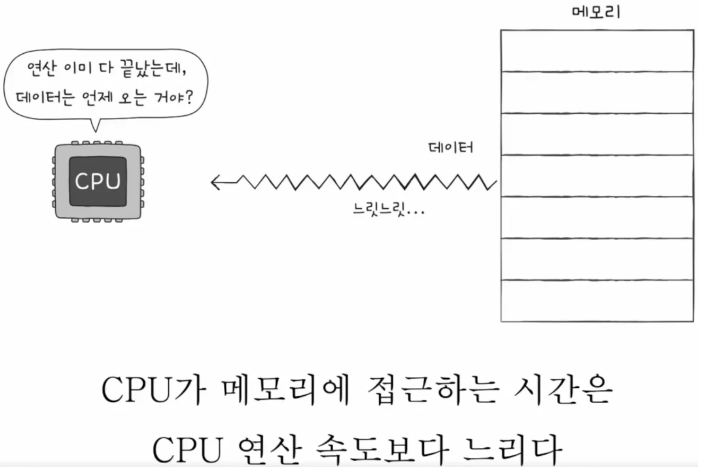
캐시 메모리
기본적으로 메모리는 CPU와 다소 떨어져 있는 하드웨어입니다. 그렇기 때문에 메모리에서 데이터를 가져오기까지 시간이 소요가 되겠죠.
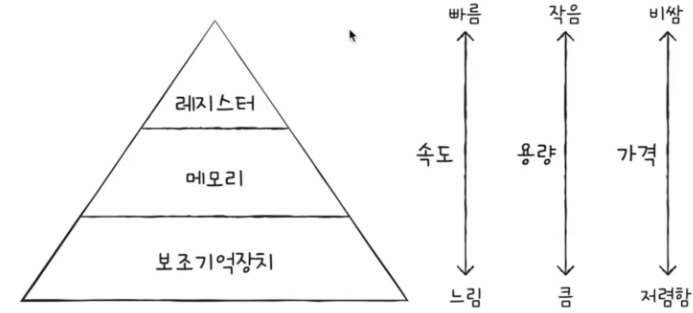
저장 장치의 계층 구조를 보면 다음과 같습니다.
CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느려요.
그리고, 속도가 빠른 저장 장치는 저장 용량이 작고 가격 또한 비싸죠.
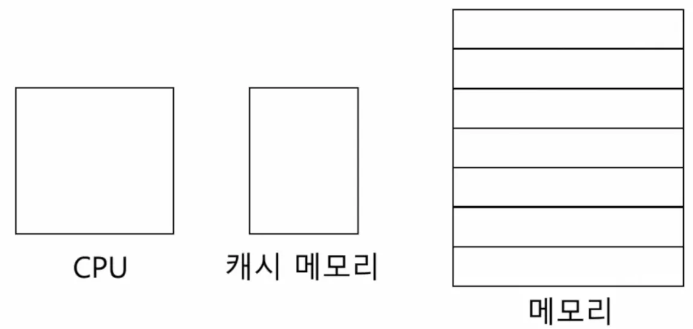
캐시 메모리는 CPU와 메모리 사이에 위치해 있습니다.
CPU가 매번 메모리에 접근하는 것은 시간이 오래 걸리니, 메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리에 가져와 사용한다는 것이 캐시 메모리의 목적입니다.
속도와 용량에 대해서 다음과 같은 예시를 들어볼게요.
CPU라는 집이 있을 때, 가까운 거리에 편의점, 먼 거리에 대형 마트가 있습니다.
이걸 편의점은 캐시 메모리, 대형 마트는 메모리라고 비유할게요.
편의점은 물건이 대형 마트보다는 적지만 집과 가까이에 위치해 있고, 대형 마트는 물건은 많아도 CPU와 멀리 떨어져서 왕복이 오래 걸리죠.
계층적 캐시 메모리
| 종류 | 위치 |
|---|---|
| L1 | CPU 내부에 존재 |
| L2 | CPU와 RAM 사이에 존재 |
| L3 | 메인보드에 존재 |
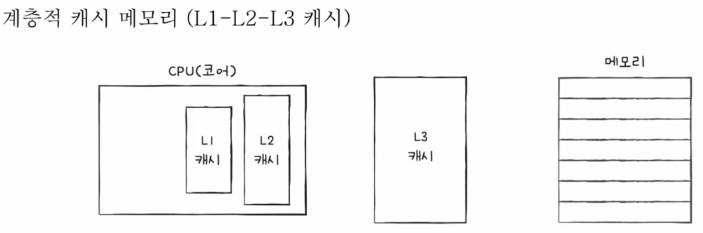
계층 구조의 확장
계층 구조를 캐시 메모리를 포함해서 확장해볼게요.
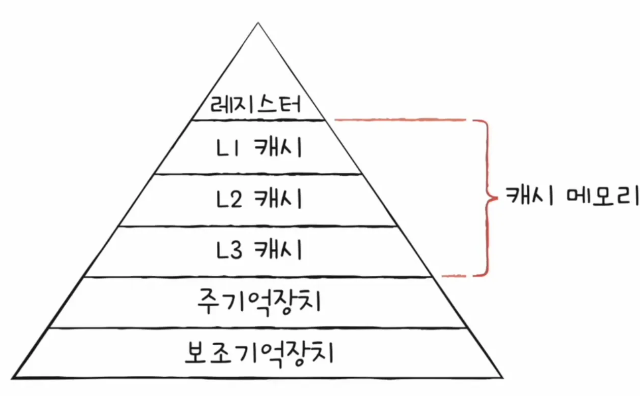
그렇다면, 캐시 메모리는 램보다 공간이 적은데, 모든 내용을 저장할 수는 없겠고... 어떤 내용을 올려둬야 하는거지?
당연히 CPU가 자주 사용할 것 같은 것들을 예측해서 저장해야겠네.
지역성의 원칙
시간적 지역성(Temporal Locality)
- 어떤 항목이 참조됐을 때, 곧바로 다시 참조되기가 쉬운 특성을 말합니다.
- 어떤 정보를 찾기 위해 도서를 책상으로 가져왔다면, 곧바로 그 책을 다시 찾아볼 확률이 크다는 것을 말해요.
공간적 지역성(Spatial Locality)
- 어떤 항목이 참조되면, 근처 다른 항목들이 곧바로 참조될 가능성이 높음을 말합니다.
- 예로, 서론에서 이야기 했던, EDSAC 내용을 찾기 위해 초창기 컴퓨터에 대한 책을 찾아왔습니다. 그렇다면 EDSAC을 찾은 그 서가 주변에 관련 책들이 있을 것이라는 의미인거죠.
이렇게 해서 캐시 메모리가 CPU가 원하는 것을 저장해두고 CPU가 이를 사용한 확률을 Cache Hit(캐시 히트)라고 합니다.
CPU가 캐시 메모리에 저장된 값을 활용하는 경우죠.
만일 틀렸다면, 이를 Cache Miss(캐시 미스)라고 합니다.
예측이 틀려 결국 메모리에 접근을 해야하는 경우죠.
캐시 적중률 = 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
엔디안
지금까지는 CPU가 램에 있는 데이터 주소에 어떻게 접근하는지에 대해서 봤습니다.
이 엔디안은 데이터가 메모리에 어떻게 쌓이는지를 보는 것입니다.
데이터를 메모리에 저장할 때 컴퓨터는 Byte 단위로 저장을 합니다.
이 저장을 어떻게 하느냐에 따라 우리는 빅 엔디안, 리틀 엔디안 방식으로 나누죠.
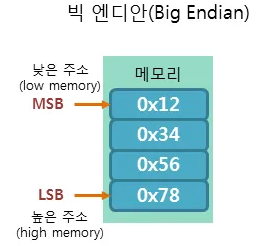
빅 엔디안(Big Endian)
- 큰 쪽을 먼저 저장하는 방식
- MSB = Most Significant Bit
- 평소 우리가 인식하는 선형 방식으로, 저장된 순서 그대로를 읽습니다.
- 32비트 크기의 0x12345678이 있다고 가정하겠습니다. 이를 빅 엔디안 방식으로 저장하면 다음과 같이 저장이 되죠.
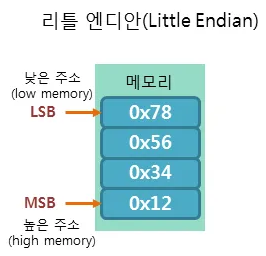
리틀 엔디안(Little Endian)
- 작은 쪽을 먼저 저장하는 방식
- LSB = Least Significant Bit
그래서 이게 왜 중요한건데? 라고 하면, 다음과 같이 이해할 수 있을 것 같습니다.
- 방식이 두 개로 나뉜다는 것은 결국 약속을 지키지 않으면 통신에서 문제가 발생할 수 있다는 것이죠.
- 예로, 본인 컴퓨터는 Little Endian인데, Big Endian으로 보내는 통신을 했을 때, Big Endian 측에서는 어떻게 읽을까요?
- 반대로 읽을 것이니 문제가 발생하겠죠.
일반적으로 네트워크에서는 Big Endian을 사용합니다. Intel은 Little Endian을 사용하고요.
Big Endian은 사람이 숫자를 읽고 쓰는 방법과 같기 때문에, 디버깅 과정에서 메모리 값을 보기 편하다는 장점이 있습니다.
Little Endian은 하위 바이트부터 먼저 읽기 때문에 컴퓨터가 연산하기에 좋다는 거죠.
그래서 예전 같았으면 Little Endian이 연산 속도에서 우위를 점하고는 있었는데, 최근에는 워낙 하드웨어가 발전하면서 연산을 병렬적으로 한다고 합니다. 그렇기 때문에 Big Endian과 Little Endian의 속도 차이는 많이 없다고 하며, 예전부터 해왔던 방식을 그대로 고수하고 있다고만 봐도 될 것 같습니다.
참고 문헌
https://code-lab1.tistory.com/179
https://www.tcpschool.com/c/c_refer_endian
https://softtone-someday.tistory.com/20
https://namu.wiki/w/%EC%97%94%EB%94%94%EC%96%B8
컴퓨터 구조 및 설계 - 하드웨어/소프트웨어 인터페이스 ARM Edition
인프런 강의 : 개발자를 위한 컴퓨터공학 1: 혼자 공부하는 컴퓨터구조 + 운영체제

구웃