블로그에 데이터베이스 관련글은 처음 작성하는 것 같다. 학교에서 신입생 입학전형 시스템 팀에 소속되어있는데 이번년도에 데이터베이스를 새로 설계하기로 했다. 기존 데이터베이스를 어떻게 수정했는지 그 과정을 블로그에 작성하려고 한다.
기존 데이터베이스 분석하기
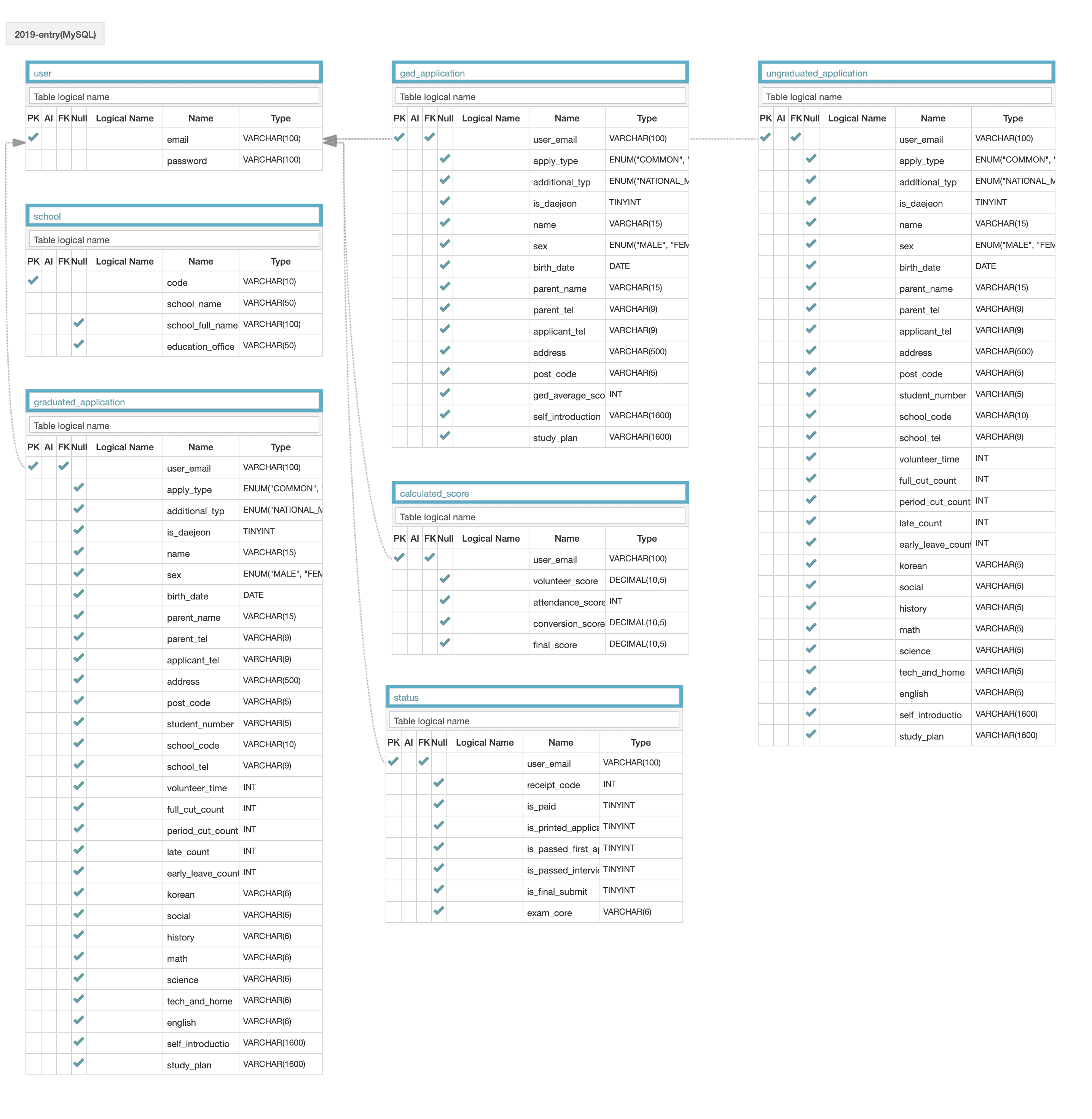
위의 사진아 기존 서비스의 데이터베이스 ERD이다. 천천히 수정할 부분이 어디있는지 분석해보자.
비슷한 내용을 표현하는 컬럼이 여러 테이블에 존재
ERD를 보면 비슷한 내용을 표현하는 컬럼이 한개의 테이블에만 있는 것이 아니라 총 3개의 테이블 graduated_application, ungraduated_application, ged_application에 존재하는 것을 볼 수 있다.
이 컬럼들은 대부분 지원자의 개인 정보에 관련된 정보가 많았다. 따라서 user 테이블로 모아서 정보를 전달 할 수 있다고 판단되었다. 처음으로 한 일은 이 중복 컬럼들은 하나의 테이블로 모아주는 일이었다.
원서 생성, 수정 시간을 알 수 없음
기존에는 원서가 자동저장 되었는데 언제 수정이 되었고, 언제 생성되었는지 알수가 없었다. 특히 작년 서비스 플로우에서는 최종제출이 되었는지 구분하기 어려워서 문의 전화가 많이왔었다. 이에 대한 방안으로 디자인등을 수정했지만 이러한 문의가 왔었을 때 정확하게 시간을 알려주기 위해서 원서 생성, 수정 시간을 알 수 있으면 좋을 것 같았다.
성적을 계산할 때 유저가 어느 전형에 신청했는지 알 수 없음
기존에는 지원자의 성적을 계산하기 위해서 테이블 3개 모두 검색했어야 했다. 그 이유는 user 테이블에서는 이 유저가 어느 전형에 신청했는지 알 수 없어서 3개의 테이블을 모두 풀 스캔했어야 했다. 이는 매우 비효율적인 부분이었고 개선이 필요하다고 느꼈다.
최종제출 시간을 알 수 있으면 좋겠음
기존 서비스에서는 최종제출을 했는지, 하지 않았는지에 대한 정보만 알 수 있었다. 따라서 이미 서비스에서는 최종제출이 되었지만 제대로 되었는지 언제 되었는지를 유저가 확인 할 수 없어서 불편한점이 있었다. 시간을 알려줄 수 있는 컬럼이 필요하다고 느꼈다.
수정된 데이터베이스 분석하기
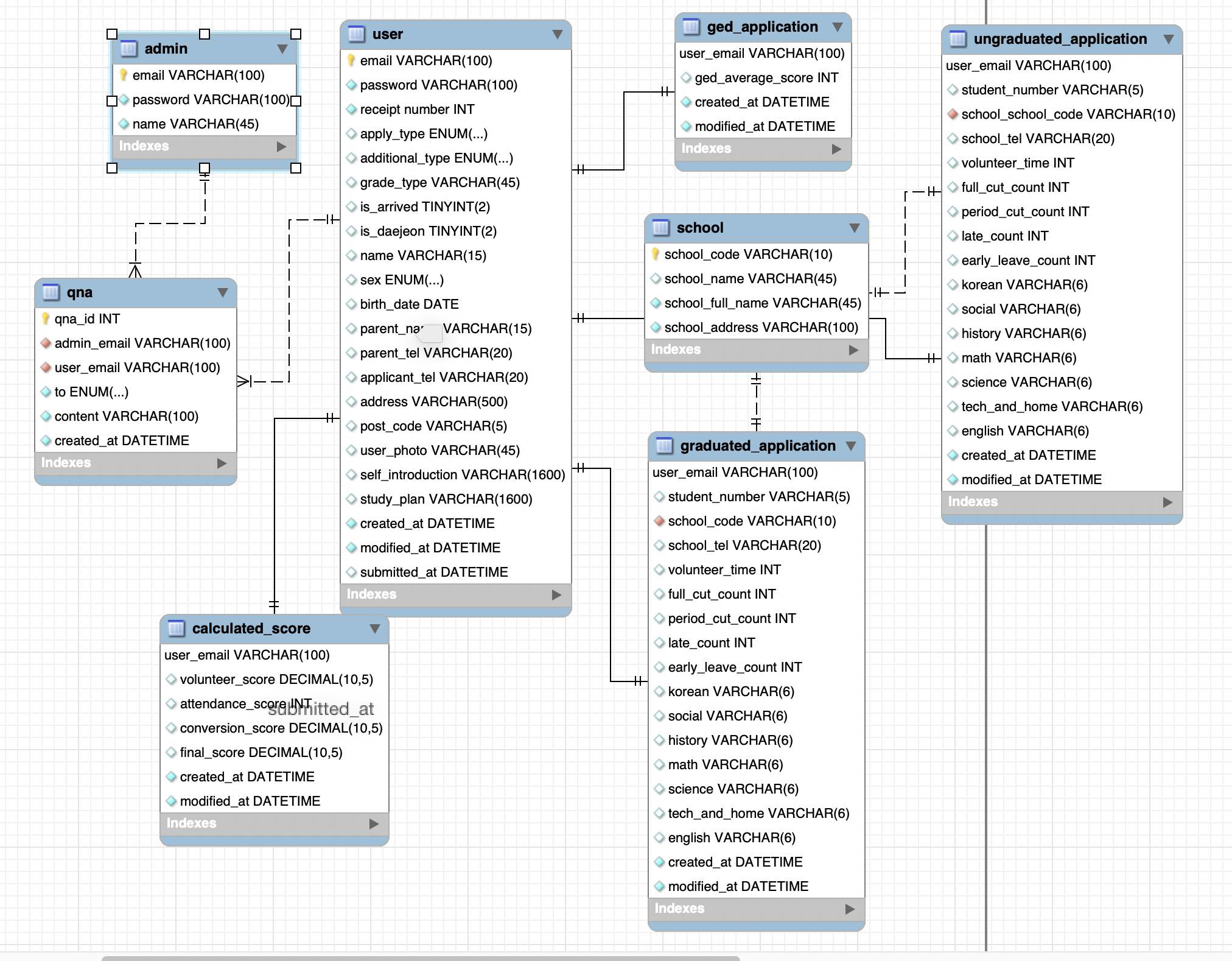
위의 ERD는 기존 데이터베이스 설계에서 수정한 이번년도 입학전형 서비스 ERD이다.
전체적으로 수정된 부분은 아래와 같다.
- 중복된 컬럼들을 하나의 테이블에서 확인할 수 있도록 수정
- 각 테이블에 생성, 수정시간 추가
- 성적계산을 위해 필요한 전형 유형 컬럼 추가
- 최종제출 시간을 알 수 있는 컬럼 추가
이것 외에도 자잘하게 기획이 수정되어 추가된 컬럼들과 ERD에서 표현 되지 않았지만 실제 데이터베이스에는 있었던 컬럼들을 추가했다.
각 수정을 통해 얻을 수 있는 이득은
중복된 컬럼들을 하나의 테이블에서 확인할 수 있다면?
기존의 학생의 기본 정보, 성적 정보등을 알 수 있게 하려면 여러 테이블을 풀스캔하여 찾아야 한다는 문제점이 있었다. 이러한 정보들을 user 테이블에 추가한다면 다른 테이블을 검색하지 않아도 user email만으로도 원하는 정보를 가져올 수 있다.
생성, 수정시간의 추가
원서와 같은 중요한 자료는 추후 어떤 일이 생길지 모르니 생성, 수정시간을 기록해두는 것이 좋다. 학교에 문의가 왔을 때에도 마지막으로 수정시간을 지원자에게 알려줄 수 있고 보안적으로 이슈가 발생하도 추적할 수 있기 때문에 생성, 수정 시간의 추가는 필요하다고 생각한다.
전형 유형 컬럼 추가
엔트리와 같은 서비스는 전형별로 필요한 정보가 다르다. 이럴 경우에는 사용자가 어떤 전형을 선택했는지를 user 테이블에서 알 수 있다면 매우 쉽게 쿼리를 작성할 수 있다. 컬럼 하나를 추가 함으로써 굳이 다른 테이블을 풀스캔 하지 않아도 되기 때문이다.
최종제출 시간 확인 컬럼 추가
사용자가 언제 최종제출 했는지 알 수 있다면, 원서 마감시간이 지나서 최종 제출한 지원자를 구분할 수 있다. 원서 테이블에서도 충분히 수정시간으로 마지막 수정시간을 확인할 수 있지만 최종제출이라는 버튼을 누르는 이벤트의 시간을 기록하는 칼럼이 위의 목적을 더 잘 표현할 수 있기 때문에 추가하였다.
위와 같은 이유 때문에 기존 데이터베이스의 설계를 변경하였다. 물론 커다란 서비스가 아니기 때문에 분석을 하기도 수정하기도 쉬웠지만 데이터베이스의 규모가 커진다면 문제점을 찾기 어려웠을 것 같다.
위와 같이 수정하고 난 뒤의 의견
위와 같이 수정하고 난 뒤 팀원들에게 피드백을 받았었다. 그 중 하나의 질문이 되게 인상 깊었는데 이에 대해서도 이야기하려고 한다.
졸업자와 비졸업자 원서 테이블에도 중복되는 컬럼이 많은데 이는 테이블로 따로 빼서 작업하지 않나요?
이 부분에 대해서도 설계할 때 어느정도 고민을 했었던 부분이다. 근데 실제 로직을 짤 때를 생각해본다면 위의 정보가 성적계산을 할 때 필요한 정보이다.
만약 졸업자, 비졸업자 원서 테이블의 중복 컬럼을 따로 테이블을 뺐을 때 성적계산 쿼리의 플로우를 본다면
- 유저 테이블에서 현재 토큰의 유저 email과 같은 튜플을 가져온다.
- 그 튜플의 유저 전형관련 전형이름을 보고 어느 테이블에서 검색할 지 확인한다.
- 그 테이블이 졸업자, 비졸업자일 경우 졸업자, 비졸업자 테이블에서 user email과 같은 튜플을 가져온다.
- 하지만 3번 튜플에는 성적과 관련된 정보가 없기 때문에 졸업자, 비졸업자 성적관련 정보를 모아둔 테이블에 가서 계산한다.
위의 4단계로 성적에 대한 정보를 가져 올 수 있다.
하지만 수정된 ERD 처럼 성적 정보를 따로 테이블로 빼지 않는다면
- 유저 테이블에서 현재 토큰의 유저 email과 같은 튜플을 가져온다.
- 그 튜플의 유저 전형관련 전형이름을 보고 어느 테이블에서 검색할 지 확인한다.
- 그 테이블이 졸업자, 비졸업자일 경우 졸업자, 비졸업자 테이블에서 user email과 같은 튜플에 있는 성적 정보로 계산한다.
위의 3단계로 한단계를 줄일 수 있어서 중복된 컬럼이라도 따로 빼지 않았습니다.
이렇게 기존 서비스의 데이터베이스 설계를 바꿔보는 작업에 대한 이야기를 해보았는데 정답은 없는 것이고 이것도 제 하나의 의견이고 과정이기 때문에 참고용으로 봐주시면 될 것 같습니다. 질문이나 개선사항은 댓글로 남겨주시면 답변하겠습니다
