
논문원본: https://arxiv.org/pdf/2506.00608
Introduction
Background
계약서: 개인, 상업, 정부 간의 다양한 관계를 규율하는 기본 법적 문서
법률 계약 문서의 특수성
- 복잡한 법률 용어가 많아 도메인 이해 필요
- 견고한 조항 검색 및 상충되는 조항 해결 능력 필요
- 예외 규정과 문서 내 참조가 많음 -> 정확한 검색 필요
- 모호한 문구와 다양한 해석 가능이 많아 정밀한 문맥 분석 필요
기업의 어려움
- 조직은 계약 관리 미흡으로 연간 수익의 평균 9.2% 손실 (WorldCC 연구)
- fortune 1000대 기업은 2만~4만 건의 계약을 동시에 관리하고 있으며 계약 승인까지 1주일 이상 걸리는 경우도 있음 (ISM Report)
Proposed Method
PAKTON
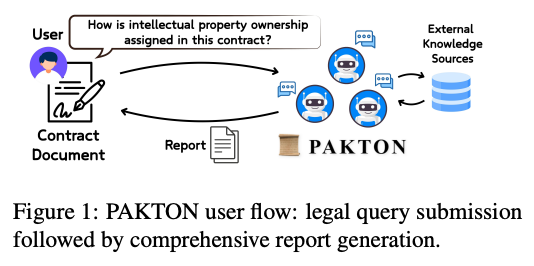
- 계약 문서를 분석하고 사용자 질의에 대해 설명 가능하고 법적으로 근거 있는 답변과 종합 보고서를 제공하는 멀티 에이전트 프레임워크
- multi-agent
- Archivist: 사용자와 상호작용하고 구조화된 문서 입력 관리
- Researcher: 내부 및 외부 정보를 검색
- Interrogator: 다단계 추론을 통해 최종 보고서를 점진적으로 정제
- 투명성, 점진적 정제, 근거 기반 정당성
Framework

- 목표: 사용자가 제공한 계약서를 분석하고, 외부 지식을 통합하여 질의 응답 생성
- 최종결과: 구조화된 법률 보고서 형태, 계약서에서 발췌한 증거 구간
Archivist Agent
역할
- 대화에 참여하여 사용자의 질의, 부가 지시사항, 그리고 맥락적 배경을 요약하여 Interrogator agent에게 전달
- 사용자의 계약서 저장
Document Parsing
- 문서 계층 구조를 보존하면서 파싱
Hierarchical Parsing
계약서 내부 구성을 반영한 계층적 트리를 생성
1. 문서의 개별 섹션 식별 (rule-based)
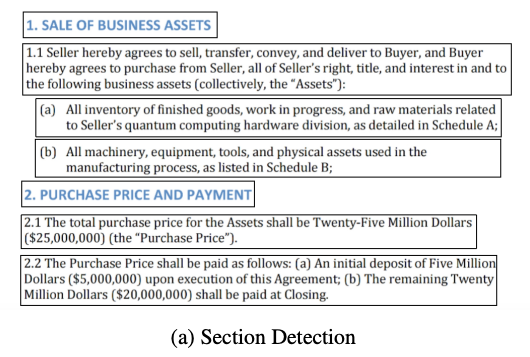
- 섹션 간 계층 관계 결정 (rule-based, BERT embedding, LLM)
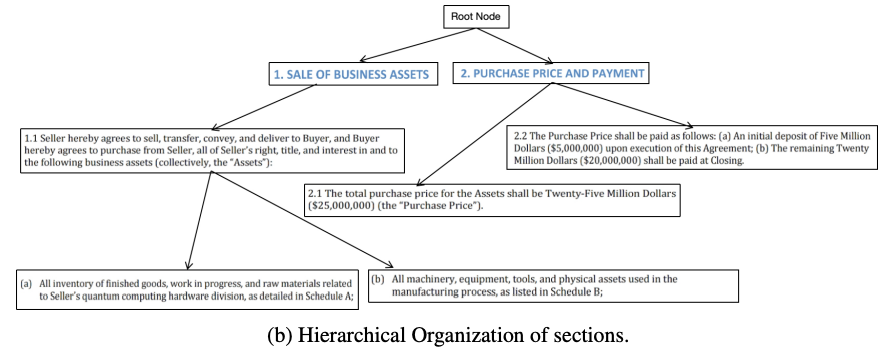
Encode Document

- 세가지 타입의 청크를 생성하여 임베딩 후에 중복제거하여 저장
- Node-level: 해당 노드만 인코딩 -> 특정 조항에 대한 질문을 위해
- Ancestor-aware: 해당 노드와 부모 노드들 인코딩 -> 해당 섹션의 맥락 파악 용이
- Descendant-aware: 해당 노드와 자식 노드들 인코딩 -> 구체적인 정보 파악
- 메타데이터: 트리 내 구조적 위치, 문서 내 위치, 파일명 등
Interrogator Agent
역할
- 사용자에게 최종 보고서 생성
- Archivist Agent로 부터 받은 정보를 바탕으로 Researcher Agent에게 반복적 심문을 통해 최종 보고서 생성
과정
- 질문에 대한 Researcher Agent의 응답을 바탕으로 초기 보고서 생성
- Archivist Agent로 부터 받은 정보, 보고서 초안을 바탕으로 후속 질문 생성
- Researcher에게 후속질문을 전달하고 얻은 정보로 보고서 초안 개선
- 최대 횟수 또는 완전하다고 판단될 때까지 2,3 과정 반복
최종 보고서 구조
- 제목과 주제 요약
- 법적 추론 및 주요 발견 사항
- 예비 답변과 제안된 연구 방향
- 지식 공백과 후속 질문
- 인용 출처와 증거 자료
Researcher Agent
역할
- 사용자의 질의에 답변할 수 있도록 Interrogator Agent를 위해 관련 정보 검색
In-document retrieval
- Archivist가 저장한 데이터에서 관련 텍스트 구간(span) 검색
- Hybrid search (BM25, RRF)
- LightRAG (option)
Cross-document retrieval
- 다른 문서에서 관련 구간 검색
- Interrogator가 few-shot 프롬프트에 사용
Retrieval of external knowledge
- 외부 지식 검색 (웹, 위키, sql, MCP)
- 기본 지식 보완과 실시간 정보 제공
- 평가시에는 사용안함
Reranking
- Cross-encoder 모델을 통해 precision 개선
Experiments
Quantitative Results
ContractNLI
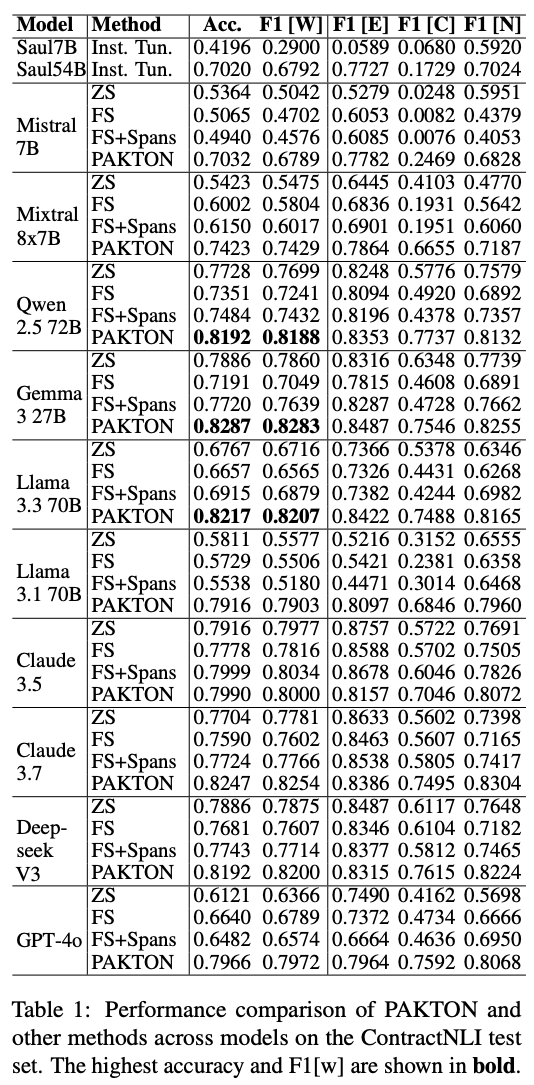
- hypothesis가 계약서에 포함되는지 모순인지 언급되지 않은지 구분
- Method
- zero-shot(ZS): 예시없음, 레이블 클래스에 대한 기본 설명, 전체 계약서 사용
- naive few-shot(FS): ZS에서 예시만 추가 -> cross-document retrieval 효과 검증
- naive few-shot isolated spans: FS에서 전체 계약서 대신 관련 있는 구간만 제공 (난이도가 쉬워짐)
- key point
- 모든 모델의 PAKTON은 baseline들을 모두 능가함
- Mistral 7B PAKTON이 Saul 54B를 능가함
- PAKTON을 사용할 경우 모델별 성능 차이가 매우 작음
LegalBench-RAG
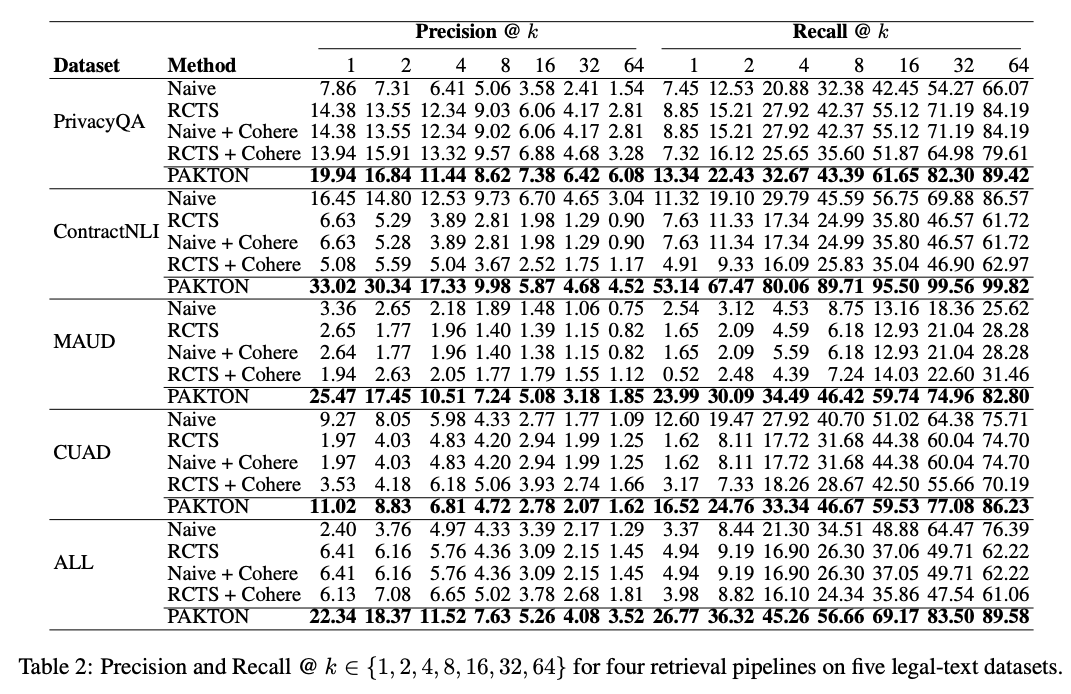
- 검색 성능만 독립적으로 평가 -> Archivist와 Researcher 만 사용
- Method
- Naive: 고정 chunk, openai embedding
- RCTS: langchain recursive structure chunk, openai embedding
- Naive + Cohere: Naive에서 reranker 추가
- RCTS + Cohere: RCTS에서 reranker 추가
- key point
- Recall 부분에서 향상된 성능 보임 -> 법률 분야에서 recall이 떨어지면 잘못된 추론이나 근거 없는 결론으로 이어질 수 있기 때문에 중요
Qualitative Results
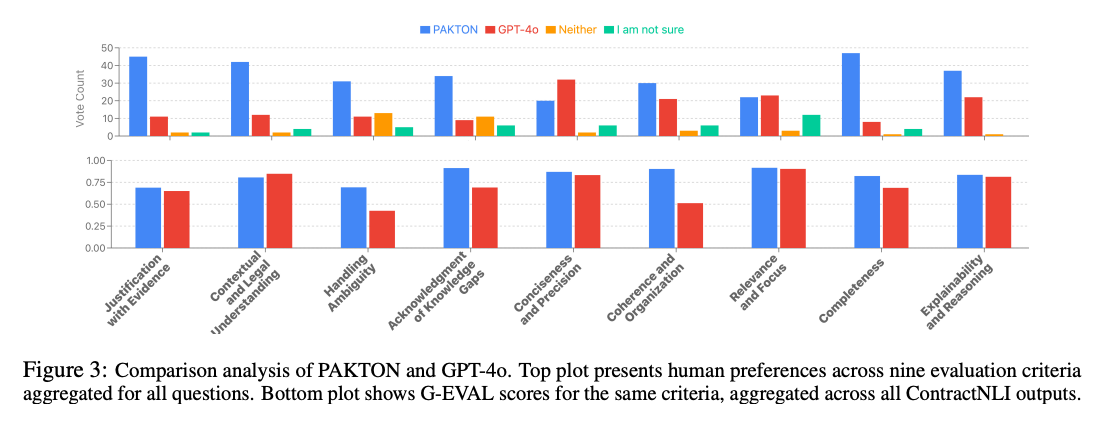
human preference
- 5명의 변호사, 1명의 대법원 판사가 만든 법률 질문 사용
- key point
- completeness 부분에서 두드러진 우위 확인됨 -> 포괄적인 답변
- explainability and reasoning 뛰어남 -> 비전문가에게 명확한 답변 제시
LLM-as-a-Judge
- G-EVAL 프레임워크 사용
- ContractNLI 데이터셋에서 샘플 사용
- key point
- human preference에서도 동일하게 completeness 부분은 뛰어나지만 precision 부분에서는 성능이 gpt와 유사함 -> 트레이드오프 관계를 뜻함
Limitation & Impact
Limitation
- 논문에서 밝힌 한계
- 영어만을 대상으로 함 -> 다국어 또는 교차 언어에서는 추가 개발 필요
- 멀티에이전트 특성상 Latency와 cost 문제 발생
- Explainability vs. Efficiency Tradeoff
- hierarchical parsing이 특정 패턴에 국한되어 있음
- 내가 생각하는 한계
- 코드가 아직 공개되어 있지 않지만 논문으로만 봤을 땐 hierarchical parsing, 계층구조에서의 탐색 및 hybrid search 가 성능 향상에 핵심이라고 생각하고 multi-agent 구조가 성능 향상에 큰 도움을 줬을 지는 의문임
- 데이터 인덱싱하는 과정은 고정된 pipeline 형태이고 나머지 두개의 agent는 사실 single react agent 이여도 충분하기 때문에 multi-agent 구현은 과도하다고 생각됨
Impact
- 법률 계약서에서 섹션 구조를 보존하면서 인덱싱하고 이러한 트리구조를 root 노드부터 탐색하는 과정은 복잡한 형태의 문서에 대한 RAG 구현시 참고하면 좋을 것으로 생각됨

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.