
논문원본: https://arxiv.org/pdf/2410.05779
Introduction
Background
- RAG 장점
- 특정 도메인 지식에 적응함으로써 사용자 요구에 맞춰 관련성 높은 정보 제공
- 최신 정보에 접근 가능
- RAG 한계
- 쿼리와 유사도를 통해 청킹된 문서 검색 -> 청킹된 문서들 간에 관계를 사용하여 검색할 수 없음
- 검색된 문서들 간에 관계를 LLM이 직접 파악해야함
Problem Definition
- Comprehensive Information Retrieval: 모든 문서에서 상호의존적인 엔티티의 전체 문맥 검색
- Enhanced Retrieval Efficiency: 검색 효율을 통한 응답 시간 단축
- Rapid Adaptation to New Data: 새로운 데이터에 대해서도 적용할 수 있는 동적 환경
Proposed Method
- LightRAG 모델
- Graph-Based Text Indexing: 지식그래프 구축
- Dual-level Retrieval Framework: 로우레벨 검색(특정 엔티티와 관계에 대한 정밀 정보 검색), 하이레벨 검색(넓은 주제와 개념 중심)
Architecture
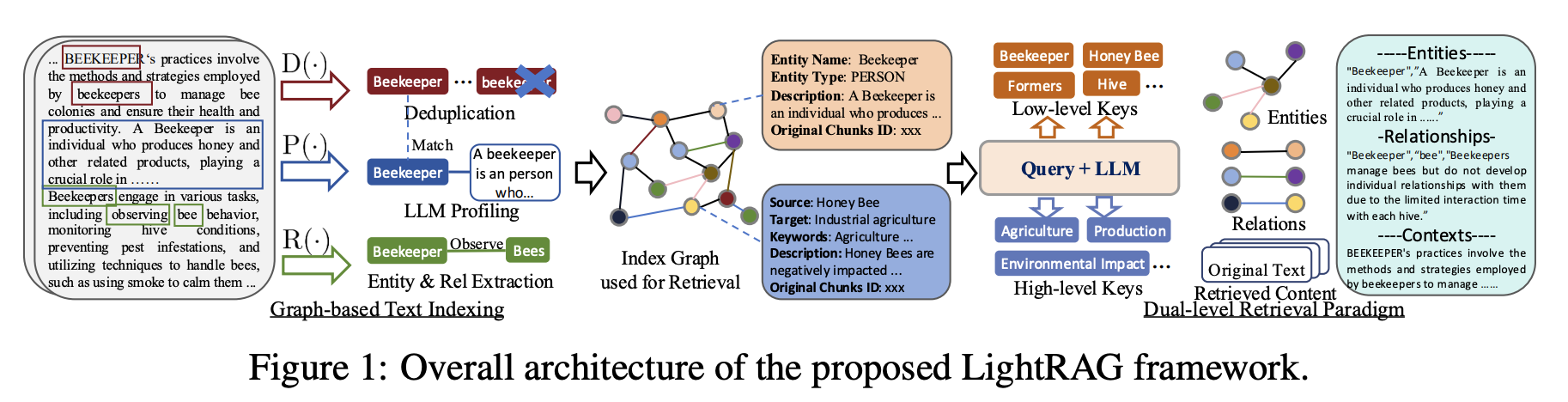
Graph-Based Text Indexing
- LLM을 사용해 텍스트에서 엔티티와 관계 추출
- LLM을 사용해 key-value profiling
- 엔티티(Entity)
- key: 엔티티 이름
- value: LLM이 생성한 해당 엔티티의 설명
- 관계(Relation)
- key: LLM으로 생성한 관계에 대한 단어나 키워드 (여러개 가능)
- value: 관계의 설명
- key들은 검색에 사용됨
- 엔티티(Entity)
- 중복된 엔티티와 관계에 대해 Deduplication
Dual-level Retrieval Paradigm
질의 키워드를 두단계로 분리 -> 구체적인 정보와 추상적인 주제를 모두 검색 가능
- Query Keyword Extraction: 쿼리로부터 지역 키워드(엔티티 중심)와 전역 키워드(주제/개념 중심)를 추출
- ex. “탄소세가 산업계의 경쟁력에 미치는 구체적 영향은 무엇인가?”
- 지역 키워드: 탄소세, 산업계
- 전역 키워드: 경제적 영향, 경쟁력, 정책 효과
- ex. “탄소세가 산업계의 경쟁력에 미치는 구체적 영향은 무엇인가?”
- Keyword Matching
- 지역 키워드: 엔티티 키 매칭 (vector search)
- 글로벌 키워드: 관계 키 매칭 (vector search)
- Incorporating High-Order Relatedness
- 검색된 노드와 엣지들 각각에 대해 1-hop 노드를 추가 수집 -> 맥락 확장
Retrieval-Augmented Answer Generation
- 검색된 key들의 value 값들을 프롬프트에 추가
- LLM을 통해 답변 생성
Evaluation
Experimental Settings
- UltraDomain benchmark 도메인: 농업, 컴퓨터 과학, 법률, 혼합
- 질문 생성(GraphRAG 방식 사용)
- 각 도메인에 5명의 가상 사용자 생성
- 각 사용자에게 5가지 과제 설정
- 각 과제당 5개 질문 생성 -> 최종 125개 질문 생성
- Baselines
- NaiveRAG: 단순 텍스트 청킹 임베딩 기반 유사도 검색
- RQ-RAG: 질문을 서브쿼리 단위로 검색
- HyDE: 질문으로부터 가상의 문서 생성 후 가상 문서와 청킹 간에 유사도 검색
- GraphRAG: https://velog.io/@sinjy1203/Microsoft-GraphRAG-Paper-Review 참고
- 평가 방법
- GPT-4o-mini 사용하여 응답 쌍을 비교 평가
- 4가지 항목으로 평가
- Comprehensiveness: 질문의 모든 측면과 세부사항을 잘 다루는가?
- Diversity: 다양한 관점과 정보를 풍부하게 제시하는가?
- Empowerment: 사용자가 주제를 잘 이해하고 판단할 수 있도록 도와주는가?
- Overall: 위 세가지 항목 종합 평가
LightRAG vs 기존 RAG 방식들
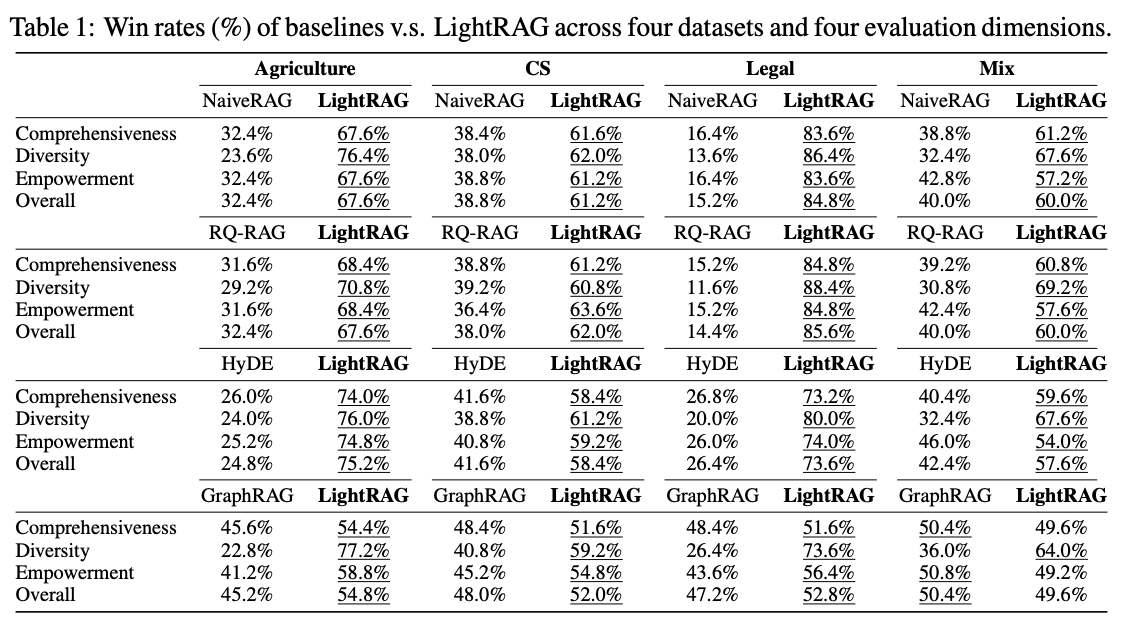
- 대규모 데이터셋 특히 법률 데이터셋에서 Graph 기반 RAG가 우수함
- 응답 다양성 측면에서 우수함, 특히 법률 도메인 -> 고수준/저수준 정보 모두 검색하는 방법의 효과로 해석
Ablation Study
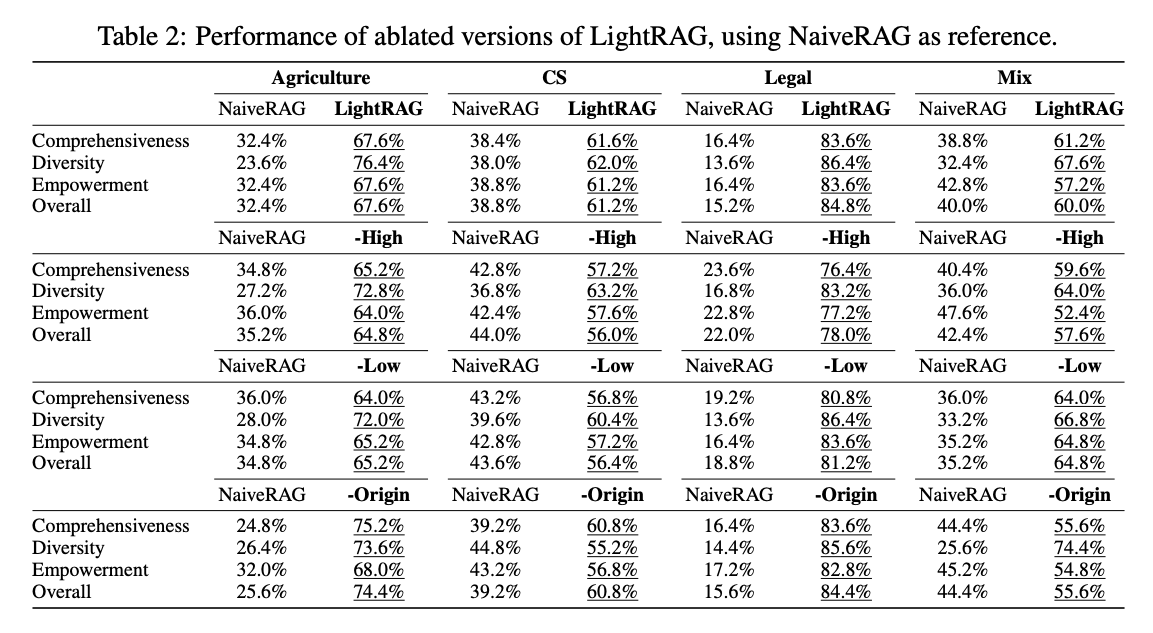
- -High(고수준 검색 제거): 특정 엔티티 중심 정보만 검색 -> 전체 맥락 파악이 부족
- -Low(저수준 검색 제거): 세부 정보 부족 -> 응답 깊이 저하
- -Origin(원문 청크 제공 안하고 key/value 만 제공): 그래프 기반 인덱싱이 이미 주요 정포 포착 및 노이즈 제거 -> 성능 크게 안떨어지고 심지어 좋아지기도 함
Case Study
- 사례: “추천 시스템 평가에 가장 유용한 지표는 무엇인가?”
- GraphRAG 응답: Precision, Recall, F1 등 기본 지표 중심, 사용자 참여 지표는 미포함
- LightRAG 응답: MAP@K, AUC, 사용자 참여도, F1, RMSE 등 다양하고 깊이 있는 지표 포함
Cost & Adaptability
- 검색시 토큰 수 및 API 호출 수
- GraphRAG: 약 610,000 tokens, 수백 개 API 호출 필요
- LightRAG: 100 tokens 미만, API 호출 1번으로 처리
- 데이터 업데이트 시 비용
- GraphRAG: 기존 커뮤니티 모두 재구성 필요 → 약 1,399 × 2 × 5,000 tokens 소모
- LightRAG: 새 정보만 그래프에 결합 → 증분 업데이트, 비용 절감 및 구조 일관성 유지
Limitation & Impact
Limitation
- Keyword Matching 부분에서 각 엔티티와 관계의 key를 사용하는데 Embedding model의 성능이 향상되면서 value를 사용하면 어떨지..?
- Incorporating High-Order Relatedness 부분에서 1-hop 까지만 추가 수집하는데 knowledge graph의 강점인 multi-hop을 100% 활용하지 못했다고 생각됨
Impact
- 추출한 엔티티와 관계의 키값으로 키워드 매칭을 함으로써 검색 효율성 향상
- GraphRAG에서 각 커뮤니티마다 답변을 생성하는 비효율을 개선함
- key는 검색, value는 prompt에 사용한다는 점에서 기발하다고 생각됨
- 쿼리를 그대로 검색에 사용하는게 아니라 그래프 구조에 맞게 키워드를 추출했다는 점도 좋은것 같음

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.