
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 3월 7일 기준으로 작성되었습니다.
Chapter 10
랭그래프와 친해지기
본 포스팅에서 랭그래프에 대해서 본격적으로 알아보고 이를 활용한 챗봇을 만들어보겠습니다
1. 랭그래프로 만드는 기본 챗봇
랭그래프의 기본 개념을 배우고 이를 이용해 간단한 챗봇을 만들어보자
- 랭그래프란?
랭그래프(LangGraph)는 랭체인에서 한발 더 나아가 여러 AI 에이전트를 연결하여 상황에 맞게 다음 작업을 하도록 구성할 수 있게 하는 프레임 워크이다
라고만 설명하면 그 누구도 알아듣지 못할 것이다
일단 간단하게 랭그래프(LangGraph)는 단계별로 실행되는 작업들을 연결하는 도구 라고 생각해보자
여기서 말하는 "그래프"란 수학 시간에 배운 좌표평면 위의 그래프를 말하는 것이 아니라 그래프 이론에서 가져온 개념이다
그래프 이론에서는 각각의 객체를 노드로, 노드 간의 연결을 엣지로 표현한다
따라서, 랭그래프는 언어 모델이 처리해야 할 일의 단계와 순서를 그래프로 명확하게 지정하고 행동, 판단할 기준을 제시한다
그러면 굳이 랭체인에서 랭그래프로 옮겨와야 할 이유는 뭘까?
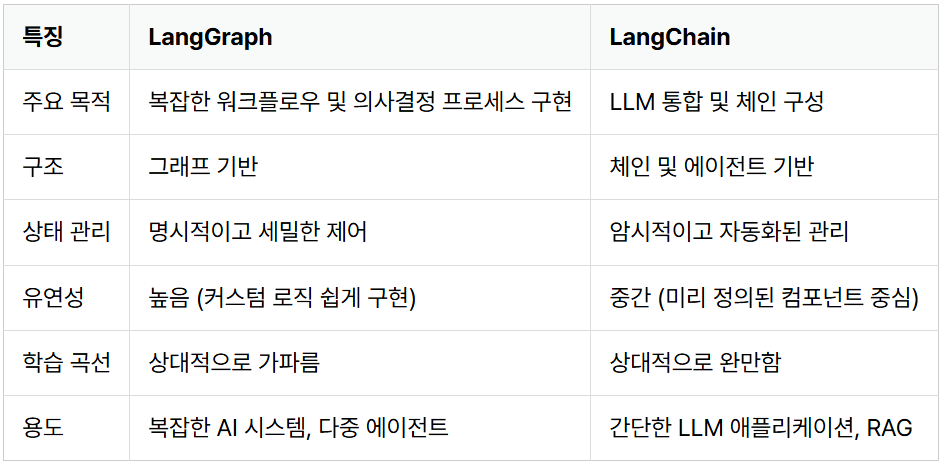
아래의 사진에서 비교점을 알아보자 [출처]
또한 일반적인 랭그래프는 아래 사진과 같이 표현 된다
랭그래프의 요소들에 대해 하나씩 알아보자
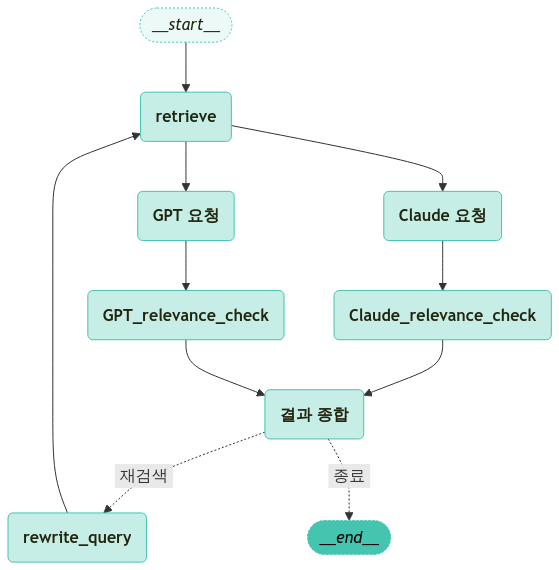
- 노드 (Node) : 하나의 작업이나 단계를 나타낸다
- 엣지 (Edge) : 노드와 노드 사이의 연결을 나타내는 화살표
- 상태 (State) : 노드가 작업한 결과를 기록해 두는 작업 일지
2. 랭그래프로 간단한 챗봇 만들기
이제 실제로 코딩을 하면서 랭그래프의 차이를 직접 경험해보자
사용자와 대화를 주고 받는 단순한 구조의 챗봇을 만들어보자
이 실습으로 랭그래프의 장점을 제대로 느끼기에는 부족하지만, 그래프의 기본 구조를 익히는데 중점을 두려고 한다
일단 langgraph_simple_chatbot.ipynb 파일을 생성하고 필요한 라이브러리를 설치하자
%pip install langgraph그리고 다음과 같이 GPT 모델을 설정하자
from langchain_openai import ChatOpenAI
# 모델 초기화
model = ChatOpenAI(model = "gpt-4o-mini")
model.invoke("안녕하세요!")이 셀을 실행하면 지금까지 실습했던것처럼 AI가 정상적으로 답변을 해준다
이제 본격적으로 랭그래프의 상태를 정의해보자
랭그래프에서 상태(State)는 언어 모델이 임무를 수행하면서 현재 상태를 명확하게 관리할 수 있도록 돕는 요소이다
랭그래프는 여러 노드, 즉 AI 에이전트가 각자 맡은 일을 수행하도록 구성되고 이 노드들은 상황에 맞게 작업할 수 있도록 필요한 정보를 주고 받아야한다
일반적으로 랭그래프에서는 State(상태) 클래스에 필요한 데이터 형식을 최대한 명확하게 정의한다
이렇게 정의된 상태에 각 노드에서 처리된 결과를 저장하고 이 정보를 다음 작업을 수행할 노드로 전달한다
이처럼 랭그래프에서는 작업을 진행하는데 필요한 항목들의 자료 형태를 미리 정해놓아야한다
이제 State 클래스와 그래프를 생성해보자
from typing import Annotated # annotated는 타입 힌트를 사용할 때 사용하는 함수
from typing_extensions import TypedDict # TypedDict는 딕셔너리 타입을 정의할 때 사용하는 클래스
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
"""
State 클래스는 TypedDict를 상속받습니다
속성:
messages (Annotated[list[str], add_messages]) : 메세지들은 "list" 타입을 갖비니다
'add_messages' 함수는 이 상태 키가 어떻게 업데이트 되어야 하는지를 정의합니다
(이 경우, 메세지를 덮어쓰는 대신 리스트에 추가합니다)
"""
messages: Annotated[list[str], add_messages]
# StateGraph 클래스를 사용하여 State 타입의 그래프 생성
graph_builder = StateGraph(State)
- class State(TypedDict)
State 클래스는 TypedDict를 사용하여 딕셔너리 형태로 사용한다
- messages: Annotated[list[str], add_messages]
State클래스에는 messages라는 변수만 있음
Annotated를 사용해 문자열로 구성된 리스트 형식임을 명시한다
- 'add_messages' 함수는 이 상태 키가 어떻게 업데이트 되어야 하는지를 정의합니다
add_messages 함수를 추가한다
langgraph에서 제공하는 함수로 문자열이 주어질 때 이를 추가하는 기능을 한다을 한다
앞으로 이렇게 만든 graph_builder에 노드와 엣지들을 연결해보자
3. 노드와 엣지 설정하기
이제 노드를 설정할 차례다
지금은 간단한 챗봇을 만들고 있으므로 사용자가 질문하면 답변을 생성하는 generate 란느 노드를 가진 랭그래프를 만들어보자
이 노드는 기존의 대화 내용에 기반해서 GPT로 답변을 생성하는 역할을 한다
def generate(state: State):
"""
주어진 상태를 기반으로 챗봇의 응답 메세지를 생성한다
매개변수 :
state (State) : 현재 대화 상태를 나타내는 객체로, 이전 메세지들이 포함되어 있다
반환값:
dict : 모델이 생성한 응답 메세지를 포함하는 딕셔너리
형식은 {"messages" : [응답메세지]} 입니다.
"""
return {"messages" : [model.invoke(state["messages"])]}
graph_builder.add_node("generate", generate)
- def generate(state: State):
generate 함수를 만들고 매개변수로 앞서 정의한 State를 받을 수 있도록 설정한다
- return {"messages" : [model.invoke(state["messages"])]}
state 안에는 messages 라는 리스트를 담을 수 있는 변수만 포함되어 있다
state에 저장된 messages를 전달해서 답변을 받아온 뒤 딕셔너리 형태로 반환한다
이 셀을 실행시키면 노트가 생성된다
<langgraph.graph.state.StateGraph at 0x1764a0bdd90>이제 엣지를 설정해보자
노드 앞뒤로 START와 END노드를 지정하고 엣지를 설정해보려고 한다
START와 END는 랭그래프에서 제공하는 노드이다
우선 앞에서 만든 graph_builder에 연결 관계를 선언하자
그래프는 START에서 챗봇을 거쳐 END로 가는 흐름으로 구성된다
이 흐름을 정의하고 그래프를 컴파일해서 graph로 선언한다
graph_builder.add_edge(START, "generate")
graph_builder.add_edge("generate", END)
graph = graph_builder.compile()그리고 우리는 현재 주피터 노트북에서 진행하고 있으므로 우리가 만든 그래프의 구조를 파이썬으로 그려볼 수 있다
이렇게 하면 현재까지 우리가 만든 노드와 엣지를 시각적으로 확인할 수 있다는 장점이 있다
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass이 셀을 실행하면 아래 사진처럼 우리가 지금까지 만든 랭그래프를 확인할 수 있다
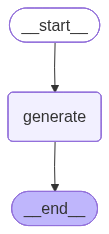
이제 그래프를 이용해 답변을 생성하기 위해 "messages" 리스트에 문장을 넣는다
그리고 graph.invoke()의 결과 데이터 타입과 전체 response를 확인하는 코드를 작성한다
response = graph.invoke({"messages" : ["안녕하세요! 저는 그루트입니다!"]})
print(type(response))
response이 셀을 실행하면 response가 dict 타입으로 반환된 것을 알 수 있다
<class 'dict'>
{'messages': [HumanMessage(content='안녕하세요! 저는 그루트입니다!', additional_kwargs={}, response_metadata={}, id='0e409880-a666-4b20-a9a0-95575c5527cf'),
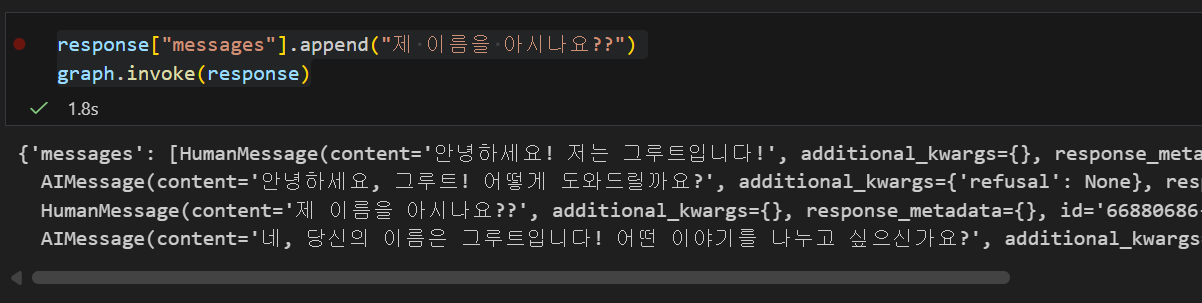
AIMessage(content='안녕하세요, 그루트! 어떻게 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 14, 'prompt_tokens': 16, 'total_tokens': 30, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0702c1c457', 'id': 'chatcmpl-DGiFSPXUUCBRWoLN4u84MBXfcUNp6', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019cc7a0-dc11-7241-af40-0b931054ffb4-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 16, 'output_tokens': 14, 'total_tokens': 30, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}이전 대화 내용을 이어나가려면 .append를 사용해서 원하는 메세지를 추가하고 graph.invoke()로 다음 문장을 생성하면 된다
response["messages"].append("제 이름을 아시나요??")
graph.invoke(response)이 셀을 실행시켜본 결과를 보면 이전 대화의 내용을 정확하게 기억하고 있는 것을 볼 수 있다
4. 스트림 방식으로 출력하기
언어 모델의 반응 속도를 크게 신경 쓰지 않아도 되는 문서 생성 작업에서는 현재 방식을 사용해도 문제가 없다
하지만 챗봇을 만들려면 사용자의 질문에 최대한 빠르게 반응할 수 있도록 스트림 방식으로 출력해야한다
이 점을 고려해서 이전 파일에 이어서 코드를 작성해보자
스트림 방식으로 출력할때는 .invoke 대신 .stream을 사용한다
이때 stream_mode를 messages로 선택하면 메세지를 스트림 방식으로 실시간 출력한다
inputs = {"messages" : [("human", "한국과 일본의 관계에 대해서 자세히 알려줘.")]}
for chunk, _ in graph.stream(inputs, stream_mode="messages"):
print(chunk.content, end="")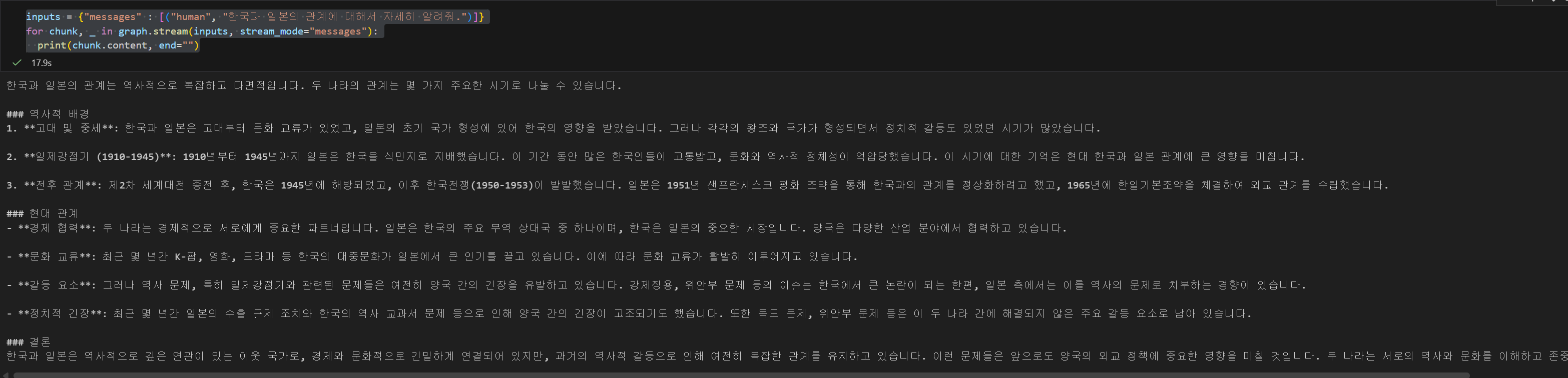
5. 마무리 및 참고링크
이렇게 간단하게 랭그래프의 이론에 대해 알아보고 이를 이용한 챗봇을 만들어보았다
아직까지는 랭체인 말고 사용해야 하는 이유를 명확하게 이해는 못했지만....
사용하는 AI 에이전트가 많아지고 더 상황이 복잡해진다면 확실히 더 도움이 되지 않을까??
일단 책에 있는 내용만 공부를 했지만 조금 더 심화 과정으로 공부할 때 참고하면 좋을 것 같아서 링크를 남겨놓으려고 한다
https://wikidocs.net/261576
나중에 이 책을 다 보고 나서 조금 더 자세히 알고 싶다면 참고하기 좋을 것 같다
