
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 3월 4일 기준으로 작성되었습니다.
Chapter 9
인터넷 검색을 활용해 답변하는 챗봇 만들기
본 포스팅에서 웹 검색과 유튜브를 활용하는 챗봇을 만들어보겠습니다!!
1. 챗봇에 웹 검색 도구 추가하기
먼저 인터넷 검색 기능을 활용하는 챗봇을 만들어보자
이전에 만들었던 langchain_streamlit_tool.py 코드를 재활용하려고 한다
이 파일을 복사해서 streamlit_with_web_search.py 파일을 만들고 코드를 수정해보자
웹 검색 엔진은 이전 포스팅에서 사용했던것처럼 덕덕고를 사용하려 한다
필요한 라이브러리를 우선 import 해주자
# 기존 langchain_streamlit_tool.py의 라이브러리
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from dotenv import load_dotenv
import os
load_dotenv()
from langchain_core.tools import tool
from datetime import datetime
import pytz
# 추가된 라이브러리
from langchain_community.tools import DuckDuckGoSearchResults
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper그리고 덕덕고를 활용해 웹 검색을 하기 위해 get_web_search 함수를 만든다
@tool 로 만든 도구 함수 정의 부분에 아래 함수를 추가한다
@tool
def get_web_search(query : str, search_period: str) -> str:
"""
웹 검색을 수행하는 함수
Args:
query (str) : 검색어
search_perios (str) : 검색 기간 (e.g., "w" for past week, "m" for past month, "y" for past year )
Returns:
str : 검색 결과
"""
wrapper = DuckDuckGoSearchAPIWrapper(region = "kr-kr", time= search_period)
print('-----------------WEB SEARCH-----------------')
print(query)
print(search_period)
search = DuckDuckGoSearchResults(
api_wrapper = wrapper,
# source = "news",
results_separator = ';\n'
)
docs = search.invoke(query)
return docs그리고 GPT가 선택할 수 있도록 도구 바인딩 딕셔너리에도 추가해준다
# 도구 바인딩
tools = [get_current_time, get_web_search]
tool_dict = {"get_current_time" : get_current_time,
"get_web_search" : get_web_search
}그리고 이제 이 파일을 streamlit run (파일명).py를 이용해서 실행해보자

포스팅 하는 시점 기준으로 예상 과징금 부과액까지 거의 정확하게 정보를 보여주는 것을 알 수 있다
또한, 관련 기사를 링크해주는것 까지 완벽한것 같다
2. 유튜브 검색 도구 추가하기
이제 유튜브를 활용해 검색하는 기능도 추가해보자
바로 이전 포스팅에서 사용한 코드를 재활용해서 현재 작업 중인 streamlit_with_web_search.py 파일에 코드를 적어보자
우선 유튜브 검색에 필요한 라이브러리들을 import 하자
# 유튜브 검색을 위한 라이브러리
from youtube_search import YoutubeSearch
from langchain_community.document_loaders import YoutubeLoader
from typing import List유튜브 검색 기능을 구현하기 위해 get_youtube_search 함수를 만든다
@tool
def get_youtube_search(query : str) -> List:
"""
유튜브 검색을 한 뒤, 영상의 내용을 반환한느 함수
Args:
query (str) : 검색어
Returns:
List : 검색 결과
"""
print('-----------------YOUTUBE SEARCH-----------------')
print(query)
videos = YoutubeSearch(query, max_results = 5).to_dict()
videos = [video for video in videos if len(video['duration']) <= 5]
for video in videos:
video_url = 'https://youtube.com' + video['url_suffix']
loader = YoutubeLoader.from_youtube_url(video_url, language = ['ko', 'en'])
video['video_url'] = video_url
video['content'] = loader.load()
return videos
- videos = [video for video in videos if len(video['duration']) <= 5]
비디오의 길이가 너무 길면 언어 모델에서 많은 토큰을 사용하게 된다 따라서 duration이 최대 59:59 이하인 영상만 남기려 한다
duration은 문자열로 주어지므로 이런 영상의 duration 문자열의 최대 길이는 '59:59'에 해당하는 5이다
그리고 마찬가지로 이 함수도 tools에 추가해서 GPT가 도구를 선택할 수 있게 해준다
# 도구 바인딩
tools = [get_current_time, get_web_search, get_youtube_search]
tool_dict = {"get_current_time" : get_current_time,
"get_web_search" : get_web_search,
"get_youtube_search" : get_youtube_search
}
해당 코드에는 영상을 요약하는 기능까지는 추가하지 않았다
언어 모델이 답변하기 전에 전체 텍스트를 한번 읽어서 답변을 생성하기에 요약이 반드시 필요한 것은 아니기 때문이다
이제 수정한 코드를 가지고 다시 스트림릿에서 실행시켜보자
그리고 똑같은 질문을 해보고 결과가 어떻게 달라졌는지 비교해보자
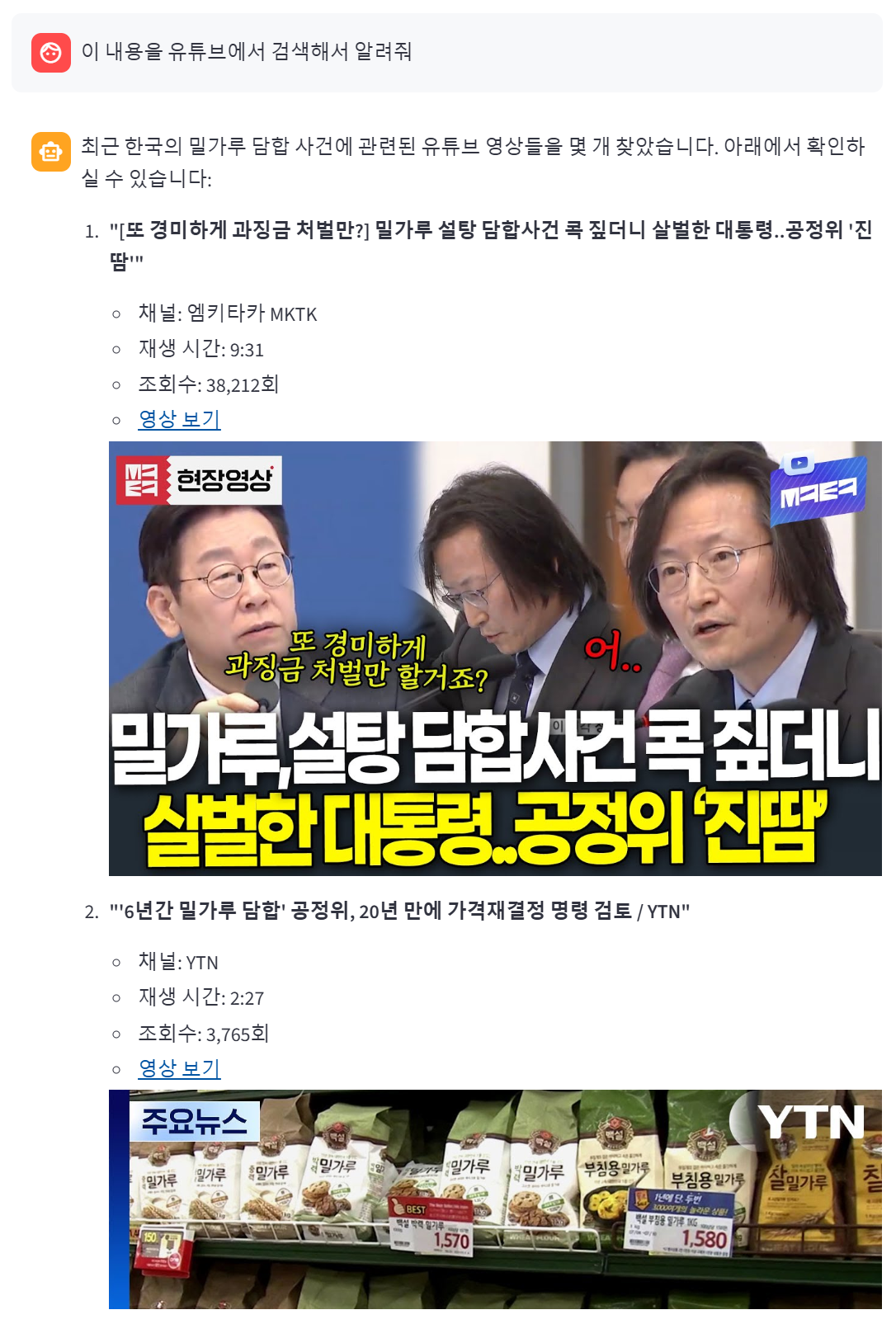
실제 영상을 불러와준다!!
3. 마무리
이번 챕터에서 배운 웹 검색과 유튜브 검색 기능을 활용해서 스트림릿에 적용해보았다
지금까지 여러번 코드를 만들고 스트림릿에서 적용시켜보면서 느낀점은...
기능을 개발하고 나서 해당 코드를 이식해서 조금씩 수정하는게 오류도 적고 확실하게 수행가능 하다는 것...?
이번 챕터에서 배운 것들은 최신 정보들을 알고 싶을 때 활용하면 좋을 것 같지만... 토큰 비용이 많이 들지 않을까
원래 책에서 다음 챕터는 로컬에서 딥시크-R1 모델 사용하기 인데
딥시크가 중국 AI라서 보안이라던가 검열 문제가 있다고 들은게 있어서... 괜히 쓰기 좀 껄그러워서 해당 챕터는 넘어갈 생각이다
그래서 다음 포스팅부터 새로운 챕터 랭그래프를 활용한 멀티에이전트 RAG 만들기를 해보려고 한다!
