
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 3월 9일 기준으로 작성되었습니다.
Chapter 11
랭그래프를 활용한 멀티에이전트 RAG 만들기
본 포스팅에서 랭그래프 기반 RAG 챗봇을 만들어보겠습니다
1. RAG의 한계
이전에 만들었떤 RAG의 흐름을 생각해보자
사용자가 질문하면 모든 경우에 대해 리트리버를 활용해 관련 문서들을 가져오고, 그 문서들을 바탕으로 답변한다
이런 경우 문제는 사용자가 일상적인 질문과 답변을 할 때에도 관련 문서를 찾아오게 되므로
시간과 토큰 비용을 계속 낭비하게 된다는 것이다
이런 문제를 해결하기 위해서 랭그래프를 이용할 수 있다
랭그래프를 이용하면 사용자의 질문을 분석해서 RAG를 사용할지 말지 판단하고 RAG가 필요한 경우에만 검색을 사용할 수 있다
또한 RAG를 실행하지 않을 때에도 필요하지 않은 청크들은 제외하고 답변을 생성하는 등 다양한 작업을 추가할 수 있다
그래서 이번 실습에서는 상황에 따라 RAG를 활용하는 챗봇을 만들어보고자 한다
사용자의 질문데 답변하는데 RAG가 필요한지 판단하고, 필요하지 않다면 RAG를 수행하지 않는 casual_talk 노드로 가서 답변을 생성한다
RAG가 필요하다면 리트리버로 질문과 관련된 청크를 가져오고, 이 청크가 사용자의 질문에 답변하는데 정말 쓸모가 있는지 판단한다
그리고 쓸모 있는 청크만 활용해 언어 모델로 답변한다
2. PDF 전처리하고 벡터 DB 만들기
우선 rag_with_langgraph.ipynb 파일을 만들고 RAG에 필요한 요소들을 채워나가보자
LLM 개발 입문 (8) 에서 사용한 PDF 파일을 그대로 사용할 예정이다
우선 현재 프로젝트 폴더에 data 폴더를 만들고 PDF 파일을 복사해오자
그리고 PDF 경로가 정상적으로 출력되는지 확인해보자.
from glob import glob
for g in glob('./data/*.pdf'):
print(g)PDF 경로가 정상적으로 출력되었다
이제 PDF 파일을 텍스트로 읽고 청크 단위로 텍스트를 자른 후, 리스트로 담아 반환하는 read_pdf_and_split_text 함수를 만들어보자
이 함수는 rag_practice.ipynb 파일에서 만든 함수를 가져와 변수명만 수정하였다
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
def read_pdf_and_split_text(pdf_path, chunk_size = 1000, chunk_overlap = 100):
"""
주어진 PDF 파일을 읽고 텍스트를 분할한다
매개변수 :
pdf_path(str) : PDF 파일의 경로
chunk_size (int, 선택적) : 각 텍스트 청크의 크기. 기본값은 1000
chunk_overlap (int, 선택적) : 청크 간의 중첩 크기. 기본값은 100
반환값 :
list : 분할된 텍스트 청크의 크기
"""
print(f"PDF : {pdf_path}")
# PDF 파일을 읽어서 텍스트 데이터 추출
pdf_loader = PyPDFLoader(pdf_path)
data_from_pdf = pdf_loader.load()
# 텍스트 데이터를 1000자 단위로 나눔 / overlap은 100자로 설정
text_splitter = RecursiveCharacterTextSplitter(chunk_size = chunk_size, chunk_overlap = chunk_overlap)
splits = text_splitter.split_documents(data_ndata_from_pdfyc)
print(f"Number of splits : {len(splits)}")
return splits방금 만든 read_pdf_and_split_text 함수를 이용해 잘라 놓은 청크들을 임베딩해서 크로마DB에 저장해보자
해당 파일과 같은 파일을 이용해서 이전에 임베딩한 경험이 있으므로 시간과 토큰이 아깝다면
예전 실습에 활용한 chroma_store 폴더를 현재 프로젝트 폴더로 복사하면 된다
그리고 그 DB를 읽어서 vectorstore에 담아보자
아래 코드에는 DB를 복사해오지 않는 경우 크로마 DB를 생성하는 코드까지 포함하였다
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
embedding = OpenAIEmbeddings(model = "text-embedding-3-large", api_key = OPENAI_API_KEY)
persist_directory = './chroma_store'
if os.path.exists(persist_directory):
print("Loading existing Chroma store")
vectorstore = Chroma(
persist_directory = persist_directory,
embedding_function = embedding,
)
else:
print("Creating new Chroma store")
vectorstore = None
for g in glob('./data/*.pdf'):
chunks = read_pdf_and_split_text(g)
# 100개씩 나눠서 저장
for i in range(0, len(chunks), 100):
if vectorstore is None:
vectorstore = Chroma.from_documents(
documents = chunks[i, i+100],
embedding = embedding,
persist_directory = persist_directory
)
else:
vectorstore.add_documents(
documents = chunks[i, i+100],
)이제 벡터 DB가 정상적으로 작동하는지 확인하기 위해 질문을 하나 해보자
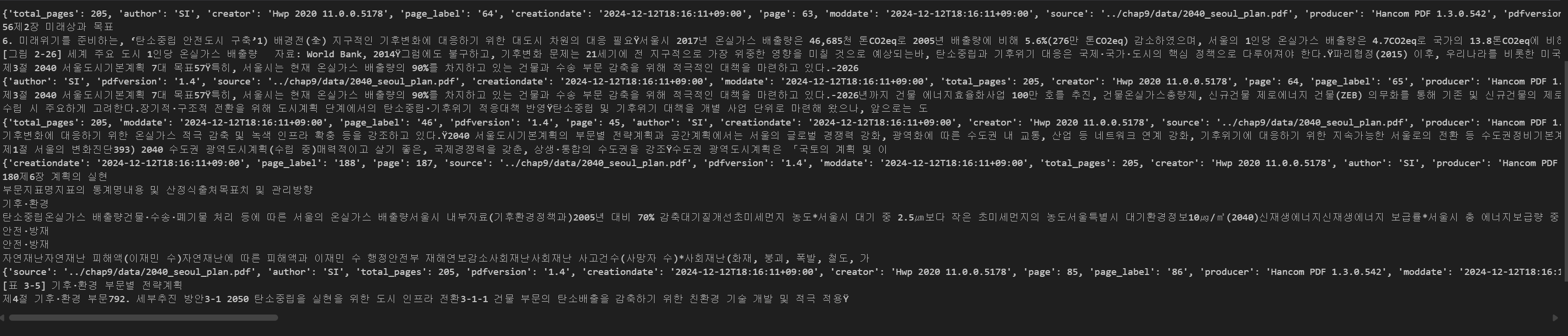
retriever = vectorstore.as_retriever(search_kwargs={"k":5})
chunks = retriever.invoke("서울 온실가스 저감 계획")
for chunk in chunks:
print(chunk.metadata)
print(chunk.page_content)우리가 가지고 있는 PDF를 기반으로 관련 내용을 잘 검색해온다
이제 챗봇으로 활용하기 위해 다음과 같이 언어 모델을 설정한다
from langchain_openai import ChatOpenAI
# 모델 초기화
model = ChatOpenAI(model = "gpt-4o-mini")
model.invoke("안녕하세요!")이 코드를 실행하면 AIMessage로 답변이 반환된다
3. 라우터 알아보기
이제 사용자의 질문에 따라 RAG의 사용 여부를 판단하는 기능인 라우터에 대해 알아보자
지금 우리가 만드는 챗봇은 사용자의 질문에 따라 RAG의 사용 여부를 판단해야 한다
예를 들어 사용자가 '안녕하세요?'라고 입력하면 일상적인 대화를 하고
'서울시 온실가스 저감 계획이 뭐야?'라고 입력하면 관련 문서를 이용해 RAG를 활용해야 한다
이런 판단을 처리하기 위해 라우터(Router)기능이 필요하다
라우터는 입력한 내용에 따라 여러 개의 실행 경로 중에서 적절한 경로를 결정해 다음 노드를 선택하는 기능을 한다
일반적으로 언어 모델의 응답이나 특정 조건에 따라 다르게 동작해야 할 때 라우터를 사용한다
4. 챗봇에 라우터 설정하기
라우터에 대해 간단하게 알아보았으니 챗봇에 라우터를 설정해보자
GPT와 같은 언어 모델이 사용자의 입력을 일상적인 대화인지 RAG가 필요한 질문인지를 판단하는 기능을 구현해보자
일상적인 대화라면 casual_talk를 반환하고 RAG가 필요한 대화라면 vector_store를 반환한다
그리고 이 판단에 따라 conditional_edge를 이용해 어떤 노드를 활용할지 판단한다
랭체인을 처음 배울 때 다룬 BaseModel을 이용해 RouteQuery라는 클래스를 만든다
datasoure 필드는 Literal 타입으로 설정해서 vector_store 또는 casual_talk 중 하나만 선택하도록 제한한다
단순히 GPT 프롬프트로 상황에 따라 판단하게 할 수도 있지만 이런 경우 답변에 불필요한 내용이 포함될 수 있따
# 라우터 설정
from langchain_core.prompts import ChatPromptTemplate
from typing import Literal # 문자열 리터럴 타입을 지원하는 typing 모듈의 클래스
from pydantic import BaseModel, Field
# Data Model
class RouteQuery(BaseModel):
"""
사용자 쿼리를 가장 관련성이 높은 데이터 소스로 라우팅한다
"""
datasource: Literal["vectorstore", "casual_talk"] = Field(
...,
description="""
사용자 질문에 따라 casual_talk 또는 vectorstore로 라우팅한다
- casual_talk : 일상 대화를 위한 데이터 소스. 사용자가 일상적인 질문을 할 때 사용한다
- vectorstore : 사용자 질문에 답하기 위해 RAG로 vectorstore 검색이 필요한 경우 사용한다
"""
)RouteQuery는 model.with_structured_output(RouterQuery)로 정의해서 둘 중 하나로만 출력이 되도록 한다
router_system으로 시스템 프롬프트를 작성해 사용자의 질문을 판단하게 한다
ChatPromptTemplate.from_messages를 이용해 route_prompt로 프롬프트 템플릿을 생성한다
이 프롬프트 안의 "{question}"은 question_router 체인을 통해 사용자의 질문을 받는 빈칸이다
# 특정 모델을 structured output(구조화된 출력)과 함께 사용하기 위해 설정
structured_llm_router = model.with_structured_output(RouteQuery)
router_system = """
당신은 사용자의 질문을 vectorstore 또는 catusl_talk로 라우팅하는 전문가이다
- vectorstore에는 서울, 뉴욕의 발전 계획과 관련된 문서가 포함되어 있다. 이 주제에 대한 질문에는 vectorstore를 사용해라
- 사용자의 질문이 일상 대화에 관련된 경우 casual_talk를 사용해라
"""
# 시스템 메세지와 사용자의 질문을 포함하는 프롬프트 템플릿 설정
router_prompt = ChatPromptTemplate.from_messages([
("system", router_system),
("human", "{question}")
])
# 라우터 프롬프트와 구조화된 출력 모델을 결합한 객체
question_router = router_prompt | structured_llm_router마지막으로 이 코드가 잘 작성되었는지 확인하기 위해 '서울 온실가스 저감 계획은 무엇인가요?' 라는 질문과 '안녕하세요?' 라는 질문을 각각 넣어보자
print(
question_router.invoke({
"question" : "서울시 온실가스 저감 계획이 뭐야?"
})
)
print(
question_router.invoke({
"question" : "안녕하세요"
})
)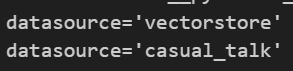
우리가 원하는 대로 질문을 구분하는 것을 확인할 수 있다
5. 마무리
이렇게 랭그래프를 이용해 RAG 에이전트를 만드는 기초 작업을 진행하였다
이전 챕터에서 진행한 내용들을 위주로 진행해서 아직까지는 코드적으로 어려운은 없는 것 같다
라우터 같은 경우에는 if 문으로 구분이 되면 제일 간단할것 같다는 생각이 들었는데
아직까지는 이렇게 경우에 따라 분기시키는게 익숙하지 않은 것 같다
라우터의 의미와 기능에 대해서는 이해했는데 어떻게 분리시키는건지는 아직도 신기함...
다음 포스팅에서 본격적으로 RAG 에이전트를 만들고 그래프 정의까지 해보려고 한다
