
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 3월 10일 기준으로 작성되었습니다.
Chapter 11
랭그래프를 활용한 멀티에이전트 RAG 만들기
본 포스팅에서는 이전에 만든 기초 코드를 기반으로 본격적인 RAG 에이전트를 만들어보겠습니다
1. 랭그래프로 RAG 에이전트 만들기
이전 포스팅에서 작성한 코드로 리트리버가 잘 작동하는지는 확인해보았다
리트리버는 벡터 DB에서 벡터 유사도를 기준으로 가장 관련있는 문서 n개 (현재는 5개)를 가져온다
문서를 무조건 5개 가져오기 때문에 질문과 관련 없는 청크가 선택될 수도 있다
질문과 관련 없는 청크를 포함하는 경우 답변을 생성할 때 혼란이 올 수 있으므로 미리 삭제하는 편이 좋다
따라서 문서의 관련성을 판단하는 방법을 프롬프트로 작성하고, 판단 결과는 BaseModel과 .with_structured_output을 활용해 출력 형식을 제한해보자
이전 포스팅에서 작업했던 주피터 노트북 파일에서 그대로 작업하면 됩니다!
우선 BaseModel을 이용해 출력 방식을 yes 또는 no 로만 제한하는 GradeDocuments 클래스를 만들자
GPT 모델을 그래도 쓰지 않고 .with_structured_output을 상요해 출력 형식을 제한한 structured_llm_grader를 만들어 사용한다
from langchain_core.prompts import PromptTemplate
class GradeDocuments(BaseModel):
"""
검색된 문서가 질문과 관련성 있는지 yes 또는 no 로 평가한다
"""
binary_score : Literal["yes", "no"] = Field(
description = "문서가 질문과 관련이 있는지 여부를 'yes' 또는 'no'로 평가한다"
)
structured_llm_grader = model.with_structured_output(GradeDocuments)이제 PromptTemplate을 이용해 프롬프트를 생성해보자
이전까지는 챗봇에서 많이 사용하는 ChatPromptTemplate를 주로 활용했는데
기존 대화 내용이 계속 이어질 필요가 없는 경우에는 PromptTemplate이 가장 정확하다
PromptTemplate.from_template 으로 프롬프트 메세지를 작성해보자
리트리버가 가져온 청크가 질문과 관계있으면 yes 아니면 no로 평가하도록 설정한다
그리고 {document}, {question}으로 빈칸을 만든다
이 빈칸은 for 문 안에서 딕셔너리 형태로 채워진다
테스트를 위해 '서울시 자율주행 관련 계획'이라는 쿼리로 리트리버를 실행해보자
grader_prompt = PromptTemplate.from_template("""
당신은 검색된 문서가 사용자 질문과 관련이 있는지 평가하는 평가자입니다. \n
문서에 사용자 질문과 관련된 키워드 또는 의미가 포함되어 있으면 해당 문서를 관련성이 있다고 평가하십시오. \n
엄격한 테스트가 필요하지 않는다. 목표는 잘못된 검색 결과를 걸러내는 것이다. \n
문서가 질문과 관련이 있는지 여부를 나타내기 위해 'yes' 또는 'no'로 이진 점수를 부여하십시오.
Retrieved document : \n {document} \n
User Question : {question}
""")
retrieval_grader = grader_prompt | structured_llm_grader
question = "서울시 자율주행 관련 계획"
documents = retriever.invoke(question)
for doc in documents:
print(doc)이 셀을 실행한 결과는 아래와 같다
총 5개의 청크를 가져왔따

가져온 청크 중에서 '서울시 자율주행 계획'과 관련된 문서만 찾아서 filtered_docs에 담는다
각 청크는 retrieval_grader로 연관성을 판단해서 결과를 받아 is_relevant에 담는다
결과가 yes인 경우에만 해당 청ㄱ크가 filtered_docs 리스트에 추가된다
filtered_docs = []
for i, doc in enumerate(documents):
print(f"Document {i+1}")
is_relevant = retrieval_grader.invoke({"question" : question, "document" : doc.page_content})
print(is_relevant)
print(doc.page_content[:200])
print("==================================\n\n")
if is_relevant.binary_score == 'yes':
filtered_docs.append(doc)
print(f"Filtered documents : {len(filtered_docs)}")해당 셀을 실행해보니 다음과 같은 결과를 확인할 수 있었다
서울시 자율주행 관련 내용을 5개 검색했지만 관련있는 내용은 4개로 판단한 것이다
Document 1
36제2장 미래상과 목표
6) 미래교통수단의 등장과 첨단 인프라 요구 증대자율주행,
UAM 등 미래 교통에 공간적 대응방안 마련 필요Ÿ자율주행차량, 전동킥보드 등 교통 기술의 발전에 따라 새로운 교통환경이 조성되고 있음에도 불구하고,
이에 대한 정착 가이드라인이 없어, 위험한 교통 사고가 유발되고 있다.-최근 3년간 서울시에서 발생한 전동킥보드 관련 사고
==================================
(생략)
Filtered documents : 42. RAG답변 생성하기
이제 GPT로 질문 내용과 관련된 청크들만 필터링해서 남겼으니 답변을 생성할 차례이다
앞서 사용한 방식과 동일하게 PromptTemplate를 이용해 사용자 질문(question)과 관련 청크(context)를 제공했을 때 답변하는 프롬프트 rag_prompt를 만들어보자
같은 PromptTemplate를 사용했지만 이번에는 선언하는 방식이 약간 다르다
앞에서는 PromptTemplate.from_template()의 괄호 안에 프롬프트 텍스트와 빈칸을 써놓았지만
이번에는 input_variables를 리스트로 따로 써두고 template에 rag_generate_system으로 만들어놓은 문자열을 받아보자
두 방식에 큰 차이는 없지만 그래도 이런 방식이 있다는 것을 알아보자
사용자의 질문은 '서울시 자율주행 관련 계획'이고 언어 모델에게 전달할 context는 filtered_docs이다
이 필터링된 리스트에는 4개의 청크만 포함되어 있다
### Generate
# PromptTemplate을 사용해 RAG를 위한 프롬프트 생성
rag_generate_system = """
너는 사용자의 질문에 대해 주어진 context에 기반하여 답변하는 도시 계획 전문가이다.
주어진 context는 vectorstore에서 검색된 결과이다
주어진 context를 기반으로 사용자의 question에 대해 답변해라
============================
question : {question}
context: {context}
"""
# PromtTemplate을 생성해 question과 context를 포매팅
rag_prompt = PromptTemplate(
input_variables=["question", "context"],
template = rag_generate_system
)
# rag chain
rag_chain = rag_prompt | model
# 사용자 질문과 검색된 문서를 입력으로 사용해 RAG를 실행
question = "서울시 자율주행 관련 계획"
rag_chain.invoke({"question" : question , "context" : filtered_docs})이 셀을 실행시키면 다음과 같이 AIMessage로 생성된 답변을 볼 수 있다
AIMessage(content='서울시는 자율주행 관련 계획을 단계적으로 추진하고 있으며,
2040년까지 서울 전역의 자율주행차량 운행 환경을 구축하고 수송 분담률을 10% 달성하는 것을 목표로 하고 있습니다.
이를 위해, 2030년까지 간선도로급 이상 도로에서 자율주행차량이 운영될 수 있도록 도로 인프라 환경을 조성할 계획입니다.\n\n또한, 서울시는 미래 교통수단의 도입에 따라 변화하는 도시 활동과 공간 구조를 반영하여 포용적인 교통체계를 구축하려고 합니다.
이를 위해 기존 교통과 새로운 미래 교통수단(예: 자율주행, UAM 등)을 통합하는 인프라 확충도 필요하게 됩니다.
\n\n서울시는 교통 뿐만 아니라 공공서비스와 물류 기능도 포함하는 모빌리티 허브를 도입하여 광역거점과 도심 간의 연결성을 강화할 계획입니다.
이러한 계획들은 서울시의 교통 기술 발전과 안전한 교통환경을 조성하는 데 중점을 두고 있습니다.',
additional_kwargs={'refusal': None}, (생략) )3. 그래프 상태 선언하고 노드 정의하기
이제 RAG 에이전트에 필요한 기능들은 다 만들었으니 이 기능들을 엮어서 하나의 그래프로 만들어보자
우선 TypeDict를 사용해 랭그래프에서 사용할 상태를 선언한다
GraphState에 필요한 정보를 담아놓고 사용한다
사용자의 질문을 담는 question, 언어 모델 답변 생성 결과를 담는 generation,
리트리버에서 검색된 문서(청크)를 담아 놓는 documents로 구성한다
이 중 documents는 리트리버에서 문서를 가져온 후 관련성을 판단해서 최종 필터링한 결과를 담게 된다
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
question : str # 사용자 질문
generation : str # LLM 생성 결과
documents : List[str] # 검색된 문서그리고 route_question 함수를 만든다
이 함수는 state를 매개변수로 받고 질문 내용을 바탕으로 RAG가 필요하면 vector_store를, 일반 대화내용이면 casual_talk를 반환한다
def route_question(state):
"""
사용자의 질문을 vectorstore 또는 casual_talk로 라우팅한다
Args:
state(dict) : 현재 graph state
return:
state(dict) : 라우팅된 데이터 소스와 사용자 질문을 포함하는 새로운 graph state
"""
print('--------------ROUTE--------------')
question = state['question']
route = question_router.invoke({"question" : question})
print(f"---Routing to {route.datasource}---")
return route.datasource다음은 retrieve 노드를 생성한다
이 노드는 리트리버에서 state의 question으로 검색한다
그 결과를 딕셔너리 형태로 반환하여 graph state를 업데이트한다
def retrieve(state):
"""
vectorstore에서 질문에 대한 문서를 검색합니다.
Args:
state (dict) : 현재 graph state
return:
state (dict) : 검색된 문서와 사용자 질문을 포함하는 새로운 graph state
"""
print('--------------RETRIEVE--------------')
question = state['question']
# Retrieve documents
documents = retriever.invoke(question)
return {"documents" : documents, "question" : question}이제 retrieve 노드에서 업데이트된 state의 documents 중에서 question과 연관성이 있는 문서만 필터링하여 filtered_docs에 담고
state의 documents를 filetered_docs로 업데이트하는 grade_documents 노드를 구현해보자
def grade_documents(state):
"""
검색된 문서를 평가하여 질문과 관련성이 있는지 확인한다
Args:
state (dict) : 현재 graph state
return:
state (dict) : 관련성이 있는 문서와 사용자 질문을 포함하는 새로운 graph state
"""
print('--------------GRADE--------------')
question = state['question']
documents = state['documents']
filtered_docs = []
for i, doc in enumerate(documents):
# print(f"Document {i+1}")
is_relevant = retrieval_grader.invoke({"question" : question, "document" : doc.page_content})
# print(is_relevant)
# print(doc.page_content[:200])
# print("==================================\n\n")
if is_relevant.binary_score == 'yes':
filtered_docs.append(doc)
return {"documents" : filtered_docs, "question" : question}다음으로 generate 노드와 casual_talk 노드를 구성해보자
generate 노드는 앞 단계의 grade_documents 노드에서 필터링한 state의 documents를 이용해 최종 답변을 생성하고
casual_talk 노드는 RAG가 필요 없는 일상적인 질문에 답하는 노드이다
def generate(state):
"""
LLM을 사용하여 문서와 사용자 질문에 대한 답변을 생성한다
Args:
state (dict) : 현재 graph state
return:
state (dict) : LLM 생성 결과와 사용자 질문을 포함하는 새로운 graph state
"""
print('--------------GENERATE--------------')
question = state['question']
documents = state['documents']
generation = rag_chain.invoke({"question" : question, "context" : documents})
return {
"documents" : documents,
"question" : question,
"generation" : generation
}def casual_talk(state):
"""
일상 대화를 위한 답변을 생성한다
Args:
state (dict) : 현재 graph state
return:
state (dict) : 일상 대화 결과와 사용자 질문을 포함하는 새로운 graph state
"""
print('--------------CASUAL TALK--------------')
question = state['question']
generation = model.invoke(question)
return {
"question" : question,
"generation" : generation
}4. StateGraph 만들기
랭그래프를 사용하기 위해서는 StateGraph를 만들고 노드들을 등록한 후, 각 노드들의 연결 관계를 정의해야 한다
앞에서 만든 노드들을 등록할 StateGraph를 만들어보자
앞에서 question, generation, documents를 담아 둘 수 있도록 했던 GraphState를 이용해서 StateGraph를 만든다
해당 객체의 이름은 workflow로 정했다
from langgraph.graph import START, END, StateGraph
workflow = StateGraph(GraphState) # StateGraph 객체 생성먼저 만든 함수들을 .add_node를 이용해 workflow의 노드로 등록하자
# 노드 정의
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)```
inputs = {
"question" : "서울시 자율주행 계획"
}
app.invoke(inputs)workflow.add_node("casual_talk", casual_talk)
이 노드들을 .add_edge를 이용해 연결하자
그리고 조건에 따라 경로를 선택하는 기능을 제공하는 .add_conditional_edge 메소드를 사용한다
그리고 이 그래프를 app이라는 이름으로 컴파일한다
```python
workflow.add_conditional_edges(
START,
route_question,
{
"vectorstore" : "retrieve",
"casual_talk" : "casual_talk"
}
)
workflow.add_edge("casual_talk", END)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
workflow.add_edge("generate", END)
app = workflow.compile() # workflow를 컴파일이제 컴파일된 결과를 그래프로 그려보면 다음과 같다
from IPython.display import Image, display
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception as e:
pass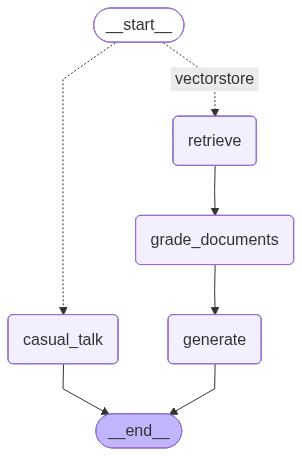
5. 멀티에이전트 테스트하기
이제 필요한 경우에만 RAG로 답변을 생성하고 일상적인 질문에는 RAG 없이 답변을 생성하는지 확인해보자
우선 서울시 자율주행 계획에 대해 app 워크플로에게 물어보자
inputs = {
"question" : "서울시 자율주행 계획"
}
app.invoke(inputs)
이 셀을 실행해본 결과 위 사진처럼 Route를 하고 vectorstore를 이용해서 답변을 생성한 것을 볼 수 있다
이번에는 일상적인 내용을 물어보자
inputs = {
"question" : "요새 어떻게 지내?"
}
app.invoke(inputs)
그리고 메세지를 스트림 방식으로 출력하고 싶다면 다음과 같은 코드를 실행하면 된다
inputs = {
"question" : "서울시 자율주행 계획"
}
for msg, meta in app.stream(inputs, stream_mode = "messages"):
print(msg.content, end='')6. 마무리
지금까지 간단하게 랭그래프와 라우터를 이용해서 멀티에이전트 RAG를 이용했다
이전에 RAG를 이용한 챗봇을 만들 때에는 RAG의 문제로 언제나 많은 양의 토큰을 사용해야 한다 라는게 있다는 것을 깨닫지 못했는데
이번 포스팅을 하면서 RAG의 문제점에 대해서도 깨달을 수 있는 시간이었다
또한, 다소 복잡하긴 하지만 라우팅을 하면서 직접 노드와 엣지를 배치해나가는 과정이 일련의 흐름을 짜는것 같았다
이렇게 대화 흐름을 만들면서 AI를 적재적소에 배치하니까 조금 더 정교한 챗봇을 만들어나가는 과정이라고 생각한다
