
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 4일 기준으로 작성되었습니다.
Chapter 3
문서와 논문을 요약하는 AI 연구원
본 포스팅에서는 PDF를 다루는 방법에 대해 다뤄보겠습니다
1. PDF 문서 txt 파일로 저장하기
PDF 파일로 저장되어 있는 문서를 언어 모델을 이용해 작업하려면 문서를 전처리하는 과정이 필요하다
이때, PyMuPDF 패키지를 사용하여 PDF 파일에서 쉽게 텐그트를 추출할 수 있지만 페이지 번호나 헤더, 푸터 같은
불필요한 정보도 포함될 수 있다
따라서, PDF를 언어 모델로 이용할 때에는 이런 불필요한 정보가 포함되지 않도록 전처리 후 사용한다
pip install PyMuPDF를 이용해서 PyMuPDF 패키지를 다운로드 받는다
이후 마음에 드는 PDF 파일을 아무거나 선택한다
이때, PDF 파일은 텍스트 영역이 선택되는 문서여야 함을 주의하자
본 포스팅에서는 언어 모델 분야에서 매우 획기적인 변화를 일으킨
2017년 Google 에서 발표한 Attention in All You Need 논문을 선택하였다
# pdf_to_text.py
import pymupdf
import os
pdf_file_path = "chap4/data/NIPS-2017-attention-is-all-you-need-Paper.pdf"
doc = pymupdf.open(pdf_file_path)
full_text = ''
for page in doc:
text = page.get_text()
full_text += text
pdf_file_name = os.path.basename(pdf_file_path)
pdf_file_name = os.path.splitext(pdf_file_name)[0] #확장자 제거
txt_file_path = f"chap4/output/{pdf_file_name}.txt"
with open(txt_file_path, 'w', encoding= 'utf-8') as f:
f.write(full_text)위 코드에서 살펴봐야할 부분은 다음과 같다
- doc = pymupdf.open(파일 경로)
파일 경로에 있는 PDF 파일을 PyMuPDF를 이용해서 열먼 PyMUPDF는 페이지별로 내용을 읽어온다
- text = page.get_text()
get_text() 함수를 이용해서 페이지에 존재하는 텍스트를 추출한다
- os.path.splitext(파일경로)[0]
pdf_file_name 에 확장자를 제거하고 PDF 파일의 이름만 넣기 위해 splitext를 이용한다
- f.write(full_text)
PDF 파일에서 읽어온 full_text를 지정한 경로의 txt 파일로 저장한다
위 코드를 바로 실행시키면 오류가 생기면서 실행되지 않는다
Python 코드가 존재하는 곳과 같은 위치에 output 폴더를 생성한 후 코드를 실행시켜보자
성공적으로 코드가 실행되었다면 아래 사진처럼 txt 파일로 PDF의 내용이 저장된 것을 확인할 수 있다
하지만 해당 txt 파일을 확인해보면 실제 논문 내용과는 관계 없는 정보 (논문 제목, 페이지 번호, 학회지 이름 등)가 포함되어 있는 것을 확인할 수 있을 것이다.
이런 PDF를 전처리 하는 과정을 거친다면 GPT와 같은 언어 모델이 더욱 잘 처리할 수 있지 않을까?
2. PDF 파일 전처리하기
PDF 에서는 각 페이지 상단과 하단에 부가 내용이 포함될 수 있다
이렇게 상, 하단에 포함된 내용을 헤더(Header)와 푸터(Footer)라고 한다
이 헤더와 푸터를 제거하고 저장하는 코드를 작성해보자
#pdf_without_header_footer.py
import pymupdf
import os
pdf_file_path = "chap4/data/NIPS-2017-attention-is-all-you-need-Paper.pdf"
doc = pymupdf.open(pdf_file_path)
header_height = 80
footer_height = 80
full_text = ''
for page in doc:
rect = page.rect # 페이지 크기 가져오기
header = page.get_text(clip=(0,0, rect.width, header_height))
footer = page.get_text(clip=(0,rect.height - footer_height, rect.width, rect.height - footer_height))
text = page.get_text(clip=(0,header_height, rect.width, rect.height-footer_height))\
# 페이지별 구분하기 위한 구분선
full_text += text + '\n------------------------------\n'
pdf_file_name = os.path.basename(pdf_file_path)
pdf_file_name = os.path.splitext(pdf_file_name)[0]
txt_file_path = f"chap4/output/{pdf_file_name}_with_processing.txt"
with open(txt_file_path, 'w', encoding= 'utf-8') as f:
f.write(full_text)위 코드에서 확인해야 하는 부분은 다음과 같다
- rect = page.rect
페이지의 크기를 추출한다
- get_text(clip = (x0, y0, x1, y1) )
clip을 이용해서 (x0, y0) 부터 (x1, y1) 까지의 영역의 text를 가져온다
코드를 실행하면 아래와 같은 결과를 확인할 수 있었다
58번째 라인에서 페이지 별로 구분선이 확실하게 들어간 것을 확인할 수 있고, 페이지 하단에 있던 학회지 정보도 제거된 것을 볼 수 있다
3. 논문 요약해주는 AI 연구원 완성하기
위에서 PDF 파일을 전처리하고 텍스트로 변환했으므로 언어 모델을 활용해 원하는 작업을 요청할 수 있다
PDF 파일의 내용을 요약해주는 코드를 작성해보자
#summary.py
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv('OPENAI_API_KEY')
def summarize_text(file_path : str):
client = OpenAI (api_key = api_key)
with open (file_path, 'r', encoding = 'utf - 8') as f:
txt = f.read()
system_prompt = f'''
너는 다음 글을 요약하는 봇이다. 아래 글을 읽고, 논문의 주요 내용을 요약해라
작성해야 하는 포맷은 다음과 같다
# 제목
## 저자의 문제 인식 및 주장 (15문장 이내)
## 저자 소개
============이하 텍스트 ============
{txt}
'''
response = client.chat.completions.create(
model = "gpt-4o",
temperature = 0.1,
messages = [
{"role" : "system", "content" : system_prompt}
]
)
return response.choices[0].message.content
if __name__ == "__main__":
file_path = "./chap4/output/NIPS-2017-attention-is-all-you-need-Paper_with_processing.txt"
summary = summarize_text(file_path)
print(summary)
with open('./chap4/output/crop_model_summary.txt', 'w', encoding = 'utf-8') as f:
f.write(summary)위 코드에서 확인해야 하는 부분은 다음과 같다
- def summarize_text(file_path : str)
summarize_text 함수를 만들고 file_path를 이용해서 원하는 파일에 접근한다
- system_prompt
GPT에게 요구할 내용들을 적고 이를 "role" : "system" 형식으로 넘겨준다
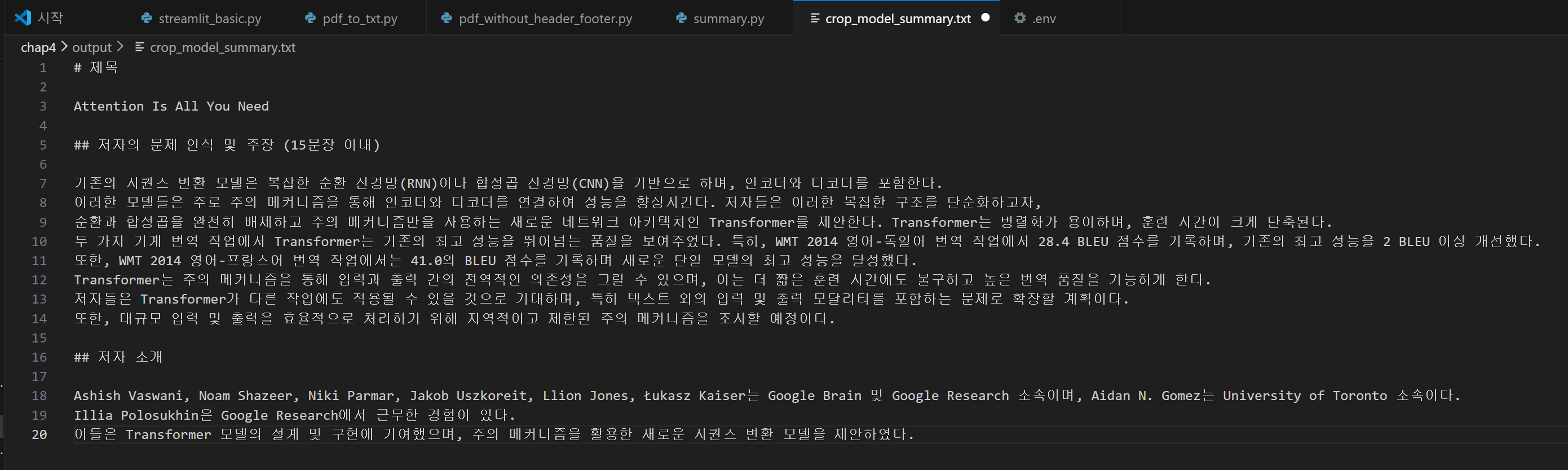
코드를 실행해서 txt 파일을 열어보면 아래와 같이 성공적으로 요약해주는 것을 볼 수 있다
4. PDF 내용을 요약해서 출력하지
마지막으로 PDF 파일을 입력하면 요약 결과를 저장하는 AI 연구원을 만들어보자
위에서 작성한 코드들을 활용하면 간단하게 만들 수 있다
summary.py 와 pdf_without_header_footer.py 코드를 활용해서 아래 코드를 만들었다
# pdf_summary.py
from openai import OpenAI
from dotenv import load_dotenv
import os
import pymupdf
load_dotenv()
api_key = os.getenv('OPENAI_API_KEY')
def pdf_to_text(pdf_file_path : str):
doc = pymupdf.open(pdf_file_path)
header_height = 60
footer_height = 60
full_text = ''
for page in doc:
rect = page.rect # 페이지 크기 가져오기
header = page.get_text(clip=(0,0, rect.width, header_height))
footer = page.get_text(clip=(0,rect.height - footer_height, rect.width, rect.height - footer_height))
text = page.get_text(clip=(0,header_height, rect.width, rect.height-footer_height))
full_text += text + '\n------------------------------\n'
pdf_file_name = os.path.basename(pdf_file_path)
pdf_file_name = os.path.splitext(pdf_file_name)[0]
txt_file_path = f"chap4/output/{pdf_file_name}_with_processing.txt"
with open(txt_file_path, 'w', encoding= 'utf-8') as f:
f.write(full_text)
return txt_file_path
def summarize_text(file_path : str):
client = OpenAI (api_key = api_key)
with open (file_path, 'r', encoding = 'utf - 8') as f:
txt = f.read()
system_prompt = f'''
너는 다음 글을 요약하는 봇이다. 아래 글을 읽고, 논문의 주요 내용을 요약해라
작성해야 하는 포맷은 다음과 같다
# 제목
## 저자의 문제 인식 및 주장 (15문장 이내)
## 저자 소개
============이하 텍스트 ============
{txt}
'''
response = client.chat.completions.create(
model = "gpt-4o",
temperature = 0.1,
messages = [
{"role" : "system", "content" : system_prompt}
]
)
return response.choices[0].message.content
def summarize_pdf(pdf_file_path : str, output_file_path : str):
txt_file_path = pdf_to_text(pdf_file_path)
summary = summarize_text(txt_file_path)
with open (output_file_path, 'w', encoding = 'utf-8') as f:
f.write(summary)
if __name__ == "__main__":
pdf_file_path = "./chap4/output/NIPS-2017-attention-is-all-you-need-Paper_with_processing.txt"
summarize_pdf(pdf_file_path, 'chap4/output/crop_model_summary2.txt')위 코드를 실행시킨 결과는 다음과 같다
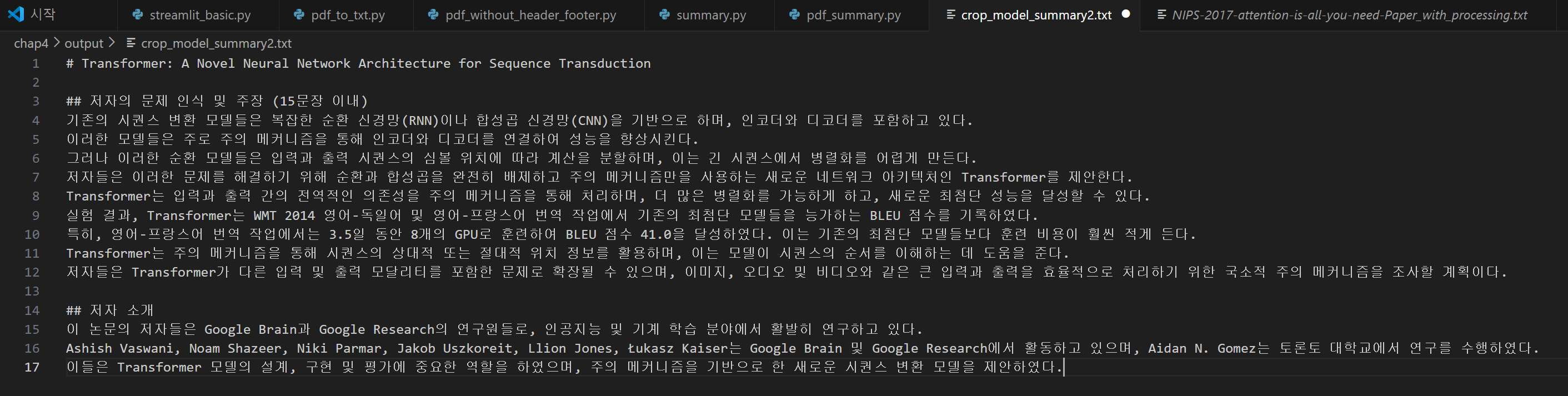
논문의 제목을 저장하는데에서 오류가 발생한것 같지만 그래도 논문의 주요 내용은 잘 요약된것을 확인할 수 있다
5. 마무리
여기까지 PDF를 텍스트로 변환하고 전처리과정을 거쳐 GPT를 이용해서 PDF를 요약해주는 봇까지 만들어보았다
전처리 과정에서 헤더와 푸터를 제외하고 또 고려해야 하는 것들일 발생할 수도 있을 것 같은 생각이 들었다
하지만 원래 데이터 처리는 전처리 과정이 매우매우매우매우 중요한 과정이니....
또한, 논문에 수식이 포함되어 있으면 잘 읽지 못하는 것 같다
이미지가 포함되어 있다면 논문의 이미지 또한 추출해서 GPT에게 넘겨준다면 더 잘 요약해줄 것 같다
PyMuPDF를 이용하면 이미지도 추출해낼 수 있다고 하니 추후에 개선점으로 이미지 추출 이후 GPT에게 전달하는 것 까지 해보면 어떨까?
