
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 5일 기준으로 작성되었습니다.
Chapter 4
회의록을 정리하는 AI 서기
본 포스팅에서는 음성 파일을 텍스트로 변환하고 요약하는 방법에 대해 알아보겠습니다
1. 음성을 텍스트로 변환하기
GPT는 텍스트를 다루는 언어모델이므로 녹음된 음성 파일을 텍스트로 변환해야만 사용할 수 있다
음성을 텍스트로 변환하는 기술을 STT (Speech To Text)라고 하며 오픈AI는 위스퍼API를 통해 이 기능을 제공한다
또한 구글에서도 STT 기능을 제공한다
일단 텍스트로 변환하고 싶은 MP3 파일을 준비해야한다
본 포스팅에서는 책의 예시에서 사용하고 있는 MP3 파일을 그대로 사용하려 한다
해당 Mp3 파일을 텍스트로 전환해보도록 하자
이번 실습부터는 단계별로 코드를 진행할 수 있도록 주피터 노트북 파일을 사용할 것이다.
#openai_api_whisper.ipynb
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
audio_file_path = "./audio/lsy_audio_2023_58s.mp3"
with open(audio_file_path, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model = "whisper-1",
file = audio_file
)
transcription위 코드를 실행시키면 MP3 파일이 텍스트로 변환된 것을 확인할 수 있다
Transcription(text='안녕하세요. 이 강의는 GPT API로 챗봇 만들기라는 내용을 다루는 강의입니다.
GPT API에 대해서 생소하신 분들도 있을 텐데 우리가 잘 알고 있는 채GPT,
채GPT 기능을 이용해서 우리가 원하는 프로그램을 어떻게 만드는지에 대해서 이야기할 거예요.
그래서 뭐 이런 강의들이 사실 많이 있습니다.
그래서 여러 가지들이 있는데 좀 이 강의의 특징이라고 한다면 GPT로 명확한 미션을 달성하는 챗봇 프로그램을 만드는 게 사실 쉽지는 않은데
이걸 어떻게 해서 구현을 하는지 그리고 그게 왜 필요한지에 대해서 좀 이야기를 할 거고요.
그 예제로 예제는 여러 가지가 될 수 있는데 여기서 예제로 하는 것은 음악 플레이리스트 동영상을 자동으로 대화를 통해서
생성하는 프로그램 만드는 것을 다루려고 합니다.
그래서 프로그램이 실행되는 모습을 한번 보여드릴게요.
우리가 만들 프로그램은 이런 식으로 이제 나타나게 되고', logprobs=None, usage=UsageDuration(seconds=58.0, type='duration'))중간에 챗GPT를 채GPT로 인식하긴 하지만 꽤나 잘 인식하는 것을 확인할 수 있다
지금은 client.audio.transcriptions.create 함수로 파일을 열었지만 함수를 약간 바꾸면 바로 영어로 번역해서 저장할 수 있다
만약 한국어 음성 파일을 영어로 번역해서 사용하고 싶다면 client.audio.translations.create 함수로 파일을 열면 된다
한국어로 받아쓴 내용을 다시 GPT-4o를 사용해서 번역할 수도 있지만 위의 translations를 사용하면 API를 이중으로 사용하는 일을 줄일 수 있다
아래 코드와 결과는 동일한 음성 파일을 영어로 번역하여 텍스트로 저장한 코드이다
#openai_api_whisper.ipynb
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
audio_file_path = "./audio/lsy_audio_2023_58s.mp3"
with open(audio_file_path, "rb") as audio_file:
translations = client.audio.translations.create(
model = "whisper-1",
file = audio_file
)
translationsTranslation(text="Hello, this is a lecture on how to make a chatbot with GPT API.
Some of you may be unfamiliar with GPT API.
We're going to talk about how to make the program we want using the chat GPT function that we know well.
There are a lot of lectures like this.
There are a lot of things, but if I were to say the characteristics of this lecture,
it's not easy to make a chatbot program that achieves a clear mission with GPT.
I'm going to talk about how to implement this and why it's necessary.
As an example, there are many examples.
The example here is to create a program that automatically creates a music playlist video through conversation.
I'll show you how the program runs. This is how the program we're going to make appears.")이렇게 위스퍼API는 한국어 음성파일을 영어로 번역까지 잘 해주는 것을 확인할 수 있다
오픈AI STT 관련 문서는 링크에서 더 자세히 확인할 수 있다
2. 로컬에서 음성을 텍스트로 변환하기
위와 같이 위스퍼API를 사용하여 음성파일을 텍스트로 변환하는 것은 꽤나 편리한 작업이지만 몇가지 단점이 존재한다
일단 오픈AI의 서버에 음성 파일이 전송되어 처리되기 때문에 회사 내부의 문서나 민감한 내용의 음성파일은 사용할 수 없으며,
음성 파일의 길이가 너무 길다면 처리 비용이 너무 많이 발생할 수 있다
이러한 문제점들을 해결하기 위해서는 로컬 환경에서 언어 모델을 내려 받아 처리해야 할 필요성이 있다
이때 허깅페이스를 이용해보도록 하자
허깅페이스는 인공지능 모델을 개발하는 회사로 각종 모델들을 다운로드 받아 사용할 수 있다
위에서 사용한 위스퍼 모델도 허깅페이스에 공개되어 있으므로 검색해서 사용할 수 있는 것이다.
일단 주피터 노트북 파일을 생성하고 pip install로 필요한 패키지를 설치하도록 하자
%pip install --upgrade pip
%pip install transformers datasets[audio] accelerate허깅페이스의 whister-large-v3-turbo 모델을 사용하기 위해서는 FFMPEG가 컴퓨터에 설치되어있어야 한다
FFMPEG는 오디오와 비디오 파일을 변환해 처리하는 오픈소스 도구로 설치되지 않은 상태에서 위 코드를 실행한다면 오류가 발생한다
FFMPEG 미설치로 인한 오류 발생시 해결 방법
FFMPEG 웹사이트에 접속해서 ffmpeg-git-full.7z 파일을 다운로드 하고 원하는 위치에서 압축 해제 후 설치한다
FFMPEG 설치 완료 이후에 다음 셀에 아래와 같은 코드를 입력하고 실행한다
이때 자신의 컴퓨터에 설치된 FFMPEG의 파일 경로를 붙여넣는다
import os
os.environ["PATH"] += os.pathsep + r"(FFMPEF 설치 경로)"이제 허깅페이스의 whisper-large-v3-turbo 모델 안내 페이지에 있는 코드를 복사해서 사용해보자
하지만 그 전에 아래 코드는 torch 라이브러리를 필요로 한다
혹시 파이토치가 설치되지 않았다면 별도의 설치 과정이 필요하다
자신의 컴퓨터 환경에 맞게 버전을 선택하고 나오는 명령어를 사용하면 손쉽게 설치할 수 있다
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
# from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
return_timestamps=True,
chunk_length_s=10,
stride_length_s=2,
)
# dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
# sample = dataset[0]["audio"]
sample = "./audio/lsy_audio_2023_58s.mp3"
result = pipe(sample)
# print(result["text"])
print(result)위에서 확인해야할 부분은 다음과 같다
- pipeline : 오디오 파일을 처리하는데 사용하는 클래스
return_timestamps=True로 설정해서 긴 MP3 파일을 청크 단위로 나누고 청크 시간을 각각 기록한다
이후 화자 분리 기능을 구현할 때 유리하다
- chunk_length : 오디오 파일을 나눠서 처리하는 시간을 지정
stride_length : 각 청크가 겹치는 시간을 지정
해당 코드를 실행시켜보려고 했으나 torchcodec에서 dll의존성 문제가 발생해서 코드가 실행되지 않았다
구글링 한 결과 설치된 pytorch 버전이 2.10 버전이고 torchcodec과 호환성이 맞지 않아서 생긴 문제인것 같아서
pytorch의 버전을 2.9로 다운그레이드하고 코드를 실행했다
결과는 다음과 같다
Device set to use cuda:0
{'text': ' 안녕하세요. 이 강의는 GPT API로 챗봇 만들기 라는 내용을 다루는 강의입니다. GPT API에 대해서 생소하신 분들도 있을텐데
우리가 잘 알고 있는 ChatGPT, ChatGPT 기능을 이용해서 우리가 원하는 프로그램을 어떻게 만드는지에 대해서 이야기할 거예요.
그래서 이런 강의들이 사실 많이 있습니다. 그래서 여러 가지들이 있는데 이 강의 특징이라고 한다면 GPT로 명확한 미션을 달성하는
챕터 프로그램을 만드는게 사실 쉽지는 않은데 이걸 어떻게 해서 구현을 하는지 그리고 그게 왜 필요한지에 대해서 좀 이야기를 할 거고요.
그 예제로 예제는 여러가지가 될 수 있는데 여기서 예제로 하는 것은 음악 플레이리스트 동영상을 자동으로 대화를 통해서 생성하는 프로그램을 만드는 것을 다루려고 합니다.
그래서 프로그램이 실행되는 모습을 한번 보여드릴게요. 우리가 만들 프로그램은 이런 식으로 이제 나타나게 되고',
'chunks':
[{'timestamp': (0.0, 6.3), 'text': ' 안녕하세요. 이 강의는 GPT API로 챗봇 만들기 라는 내용을 다루는 강의입니다.'},
{'timestamp': (7.18, 10.0), 'text': ' GPT API에 대해서 생소하신 분들도 있을텐데'},
{'timestamp': (11.0, 17.0), 'text': ' 우리가 잘 알고 있는 ChatGPT, ChatGPT 기능을 이용해서'},
{'timestamp': (17.0, 21.0), 'text': ' 우리가 원하는 프로그램을 어떻게 만드는지에 대해서 이야기할 거예요.'},
{'timestamp': (21.0, 24.0), 'text': ' 그래서 이런 강의들이 사실 많이 있습니다.'},
{'timestamp': (24.0, 27.48), 'text': ' 그래서 여러 가지들이 있는데 이 강의 특징이라고 한다면'},
{'timestamp': (27.48, 29.58), 'text': ' GPT로 명확한 미션을 달성하는'},
{'timestamp': (29.58, 31.66), 'text': ' 챕터 프로그램을 만드는게 사실'},
{'timestamp': (31.66, 34.32), 'text': ' 쉽지는 않은데 이걸 어떻게 해서'},
{'timestamp': (34.32, 36.4), 'text': ' 구현을 하는지 그리고 그게 왜 필요한지에 대해서'},
{'timestamp': (36.4, 37.36), 'text': ' 좀 이야기를 할 거고요.'},
{'timestamp': (38.0, 40.0), 'text': ' 그 예제로 예제는 여러가지가 될 수 있는데'},
{'timestamp': (40.0, 42.0), 'text': ' 여기서 예제로 하는 것은'},
{'timestamp': (42.0, 44.2), 'text': ' 음악 플레이리스트 동영상을'},
{'timestamp': (44.2, 47.1), 'text': ' 자동으로 대화를 통해서 생성하는 프로그램을 만드는 것을'},
{'timestamp': (47.1, 48.46), 'text': ' 다루려고 합니다.'},
{'timestamp': (49.84, 51.96), 'text': ' 그래서 프로그램이 실행되는 모습을 한번 보여드릴게요.'},
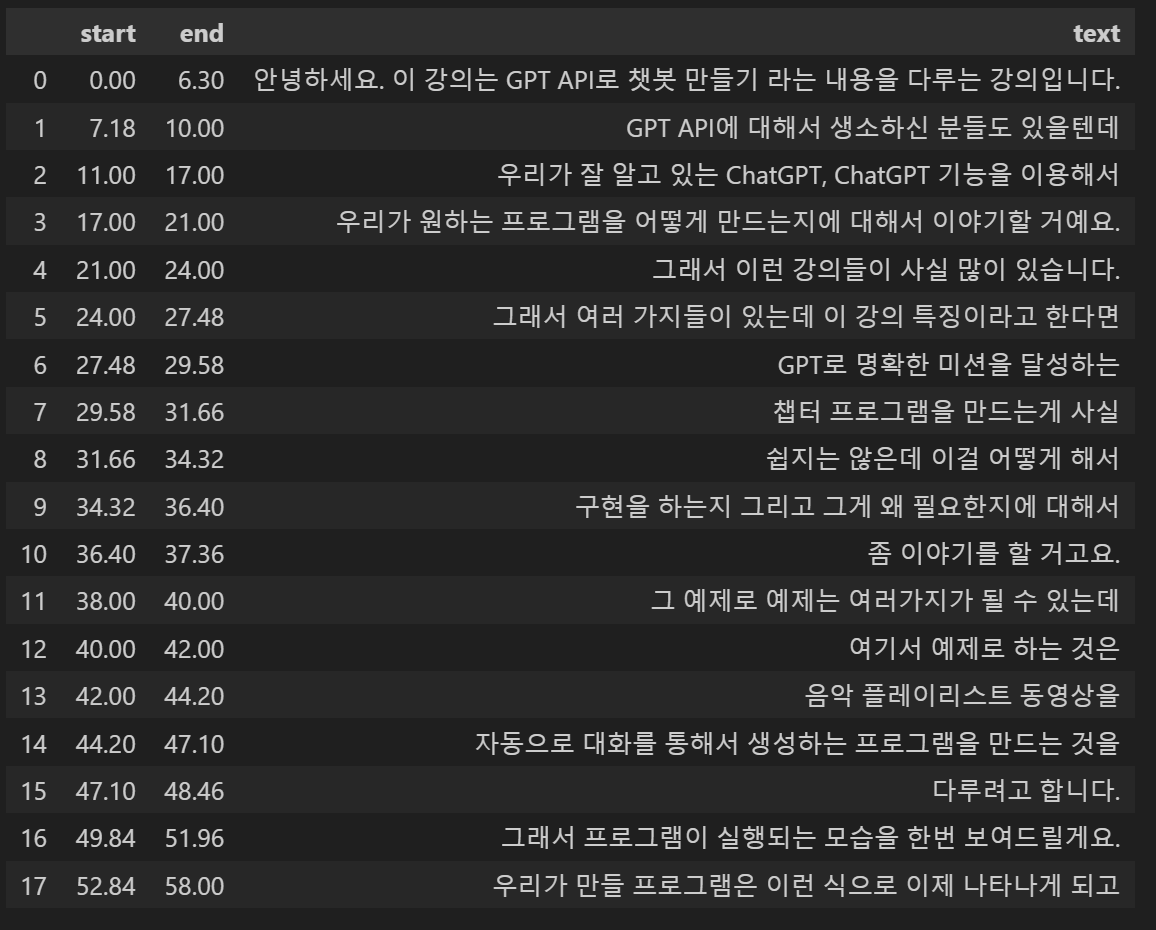
{'timestamp': (52.84, 58.0), 'text': ' 우리가 만들 프로그램은 이런 식으로 이제 나타나게 되고'}]}작성한 코드대로 timestamp 마다 text가 분리되어서 출력되는 것을 확인할 수 있다
이 중에서 chunk에 저장된 값들을 CSV 파일로 저장해보도록 하자
result의 chunks를 for문을 이용해서 저장하는 코드는 다음과 같다
이 결과는 Pandas의 DataFrame을 이용해서 저장하려 한다
start_end_text = []
for chunk in result["chunks"]:
start = chunk["timestamp"][0]
end = chunk["timestamp"][1]
text = chunk["text"]
start_end_text.append((start, end, text))
import pandas as pd
df = pd.DataFrame(start_end_text, columns=["start","end", "text"])
df.to_csv("lsy_audio_2023_58.vsc", index = False, sep = "|")
display(df) 코드 실행 결과는 아래와 같다
3. 마무리
이번 실습은 파이토치와 FFMPEG를 설치하고 확인하는데에 있어서 많은 시간이 걸렸다....
코드를 실행시키려고 하는데 계속 torchcodec에 에러가 발생해서 GPT에게도 질문하고 구글링을 하다가 겨우겨우 하나의 블로그를 발견해서 확인할 수 있었다
문제 해결에 도움을 준 블로그
역시 문제가 생길땐 출력창에 뜬 오류 메세지를 그대로 복붙해서 긁어봐야하나...?
다음 포스팅에서는 위스퍼AI를 이용해서 문장과 화자를 분리하고 이를 더 발전시켜서 AI 서기를 만들어보는 실습을 진행하려 한다
