
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 17일 기준으로 작성되었습니다.
Chapter 7
랭체인을 활용한 에이전트 개발
본 포스팅에서는 랭체인으로 스트림 출력방식을 스트림릿에 구현해보겠습니다!!
1. 랭체인 메모리에 기반한 멀티턴 챗봇 만들기
예전에 만든 streamlit_basic.py 파일을 기반으로 랭체인에서도 스트림릿을 활용해보자
langchain_simple_chat_streamlit.py 파일을 만들고 streamlit과 랭체인에서 필요한 클래스들을 모두 가져오자
# langchain_simple_chat_strealit.py
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.chat_history import BaseChatMessageHistory클래스들을 가져오고 기존 코드에서 사이드바를 주식으로 처리하거나 삭제한다
기존 코드는 사이드바를 사용했지만 오픈AI의 API키를 env 파일에서 관리한다면 딱히 사이드바가 필요하지 않다
그리고 st.title() 안에 원하는 제목을 써보자
# with st.sidebar:
# openai_api_key = os.getenv('OPENAI_API_KEY')
# "[GET an OpenAI API Key](https://platform.openai.com/account/api-keys)"
# "[View the source code](https://github.com/streamlit/llm-examples/blob/main/Chatbot.py)"
# "[](https://codespaces.new/streamlit/llm-examples?quickstart=1)"
st.title("💬 Chatbot")이제 stream_basic.py 에 있던 코드에서 수정해보자
st.session_state 는 스트림릿이 세션 동안 유지하는 상태 저장용 딕셔너리이다
messages 키가 아직 st.session_state에 없다면 ["messages"]에 시스템 메세지를 넣어서 초기화한다
if "messages" not in st.session_state:
st.session_state["messages"] = [
SystemMessage(content = "너는 사용자의 질문에 친절히 답하는 AI 챗봇이다.")
]그리고 대화 내용을 기록하기 위해 store 딕셔너리를 반든다
store는 세션별 대화 히스토리를 담아 두는 공간으로 사용된다
messages는 전체 메세지 목록이라면 store는 세션ID 별로 나뉘는 대화 이력 객체를 보관하는 장소이다
# 세션별 대화 기록을 저장할 딕셔너리 대신 session_state 사용
if "store" not in st.session_state:
st.session_state["store"] = {}이제 get_session_history 함수를 선언한다
이 함수는 이전에 langchain_message_history.ipynb 에서 만들었던 함수를 가져와서 약간 수정한 것이다
session_id를 매개변수로 받아 st.session_state["store"] 딕셔너리에서 해당 session_id에 대응하는 대화 이력 객체를 가져온다
만약 session_id가 없다면 InMemoryChatMessageHistory()를 새로 생성한다
그리고 최종적으로 해당 세션의 대화 이력 객체를 반환한다
이렇게 하면 각 사용자마다 고유 session_id를 기준으로 대화 이력을 추적할 수 있다
def get_session_history(session_id : str) -> BaseChatMessageHistory:
if session_id not in st.session_state["store"]:
st.session_state["store"][session_id] = InMemoryChatMessageHistory()
return st.session_state["store"][session_id]이제 랭체인의 ChatOpenAI를 이용해서 언어 모델을 사용하고 llm 변수로 선언한다
langchain_message_history.ipynb 파일과 동일하게 RunnableWithMessageHistory를 사용한다
config도 동일하게 session_id도 abc2로 지정해보자
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(model = "gpt-4o-mini")
with_message_history = RunnableWithMessageHistory(llm, get_session_history)
config = {"configurable" : {"session_id" : "abc2"}}st.session_state.message 에는 지금까지 주고 받은 대화가 리스트 형태로 저장되어있다
for문을 통해서 각 메세지 내용을 스트림 릿의 st.chat_message로 출력한다
이때 st.chat_message("user")나 st.chat_message("assistant")등을 사용해 채팅 인터페이스처럼 출력할 수 있다
# 스트림릿 화면에 메세지 출력
for msg in st.session_state.messages:
if msg:
if isinstance(msg, SystemMessage):
st.chat_message("system").write(msg.content)
elif isinstance(msg, AIMessage):
st.chat_message("assistant").write(msg.content)
elif isinstance(msg, HumanMessage):
st.chat_message("user").write(msg.content)이제 원래 streamlit_basic.py 코드에서 스트림릿에 맞게 바꾸자
if prompt := st.chat_input():
print('user :', prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
st.chat_message("user").write(prompt)
response = with_message_history.invoke([HumanMessage(content = prompt)], config = config)
msg = response.content
st.session_state.messages.append(response)
st.chat_message("assistant").write(msg)
print('assistant :', msg)이제 터미널 창에서 streamlit run (파일명).py를 이용해서 스트림릿에서 확인을 해보자

이렇게 대화 기록을 기억하는 챗봇을 만들었다
여기서 스트림 방식으로 출력할 수 있도록 수정해보자
랭체인에서는 매우 간단하게 .invoke()를 .stream()으로 수정한다
그리고 ai_response_bucket = None으로 선언하고 for문을 실행하면서 스트림 방식으로 넘어오는 AIMessageChunk를 담고
ai_response_bucket에 이어붙이는 방식으로 저리한다
if prompt := st.chat_input():
print('user :', prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
st.chat_message("user").write(prompt)
response = with_message_history.stream([HumanMessage(content = prompt)], config = config)
ai_response_bucket = None
with st.chat_message("assistant").empty():
for r in response:
if ai_response_bucket is None:
ai_response_bucket = r
else:
ai_response_bucket += r
print(r.content, end = " ")
msg = ai_response_bucket.content
st.session_state.messages.append(ai_response_bucket)
print('assistant :', msg)이제 파일을 다시 실행시켜보면 스트림 방식으로 잘 출력되는 것을 볼 수 있다
2. 랭체인에서 메모리 없이 멀티턴 만들기
랭체인에서 메모리 기능을 활용하기 보다 대화 내용을 리스트로 직접 관리하는 것이 더 간편할 때도 있다
예를 들어 대화 내용을 DB에 저장하거나 히스토리를 수정해야 할 때는 랭체인 메모리에 관리하는것보다 리스트로 직접 관리하는 것이 더 효율적일 수 있다
이번에는 stock_info_history.py를 기반으로 스트림릿에서 랭체인의 도구 호출까지 사용하도록 만들어보자
langchain_streamlit_tool.py 파일을 생성하고 랭체인의 히스토리를 사용하지 않고 코드를 작성한다
기본적으로 스트림 방식으로 출력될 수 있게 한다
# langchain_streamlit_tool.py
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from dotenv import load_dotenv
import os
load_dotenv()
# 모델 초기화
llm = ChatOpenAI(model = "gpt-4o-mini")
# 사용자의 메세지를 처리하는 함수
def get_ai_response(messages):
response = llm.stream(messages)
for chunk in response:
yield chunk
# 스트림릿 앱
st.title("💬 GPT-4o Langchain Chat")
# 스트림릿 session_state에 메세지 저장
if "messages" not in st.session_state:
st.session_state["messages"] = [
SystemMessage(content = "너는 사용자의 질문에 친절히 답하는 AI 챗봇이다."),
AIMessage(content = "How can I help you?")
]
# 스트림릿 화면에 메세지 출력
for msg in st.session_state.messages:
if msg:
if isinstance(msg, SystemMessage):
st.chat_message("system").write(msg.content)
elif isinstance(msg, AIMessage):
st.chat_message("assistant").write(msg.content)
elif isinstance(msg, HumanMessage):
st.chat_message("user").write(msg.content)
# 사용자 입력 처리
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
response = get_ai_response(st.session_state["messages"])
result = st.chat_message("assistant").write_stream(response)
st.session_state["messages"].append(AIMessage(result))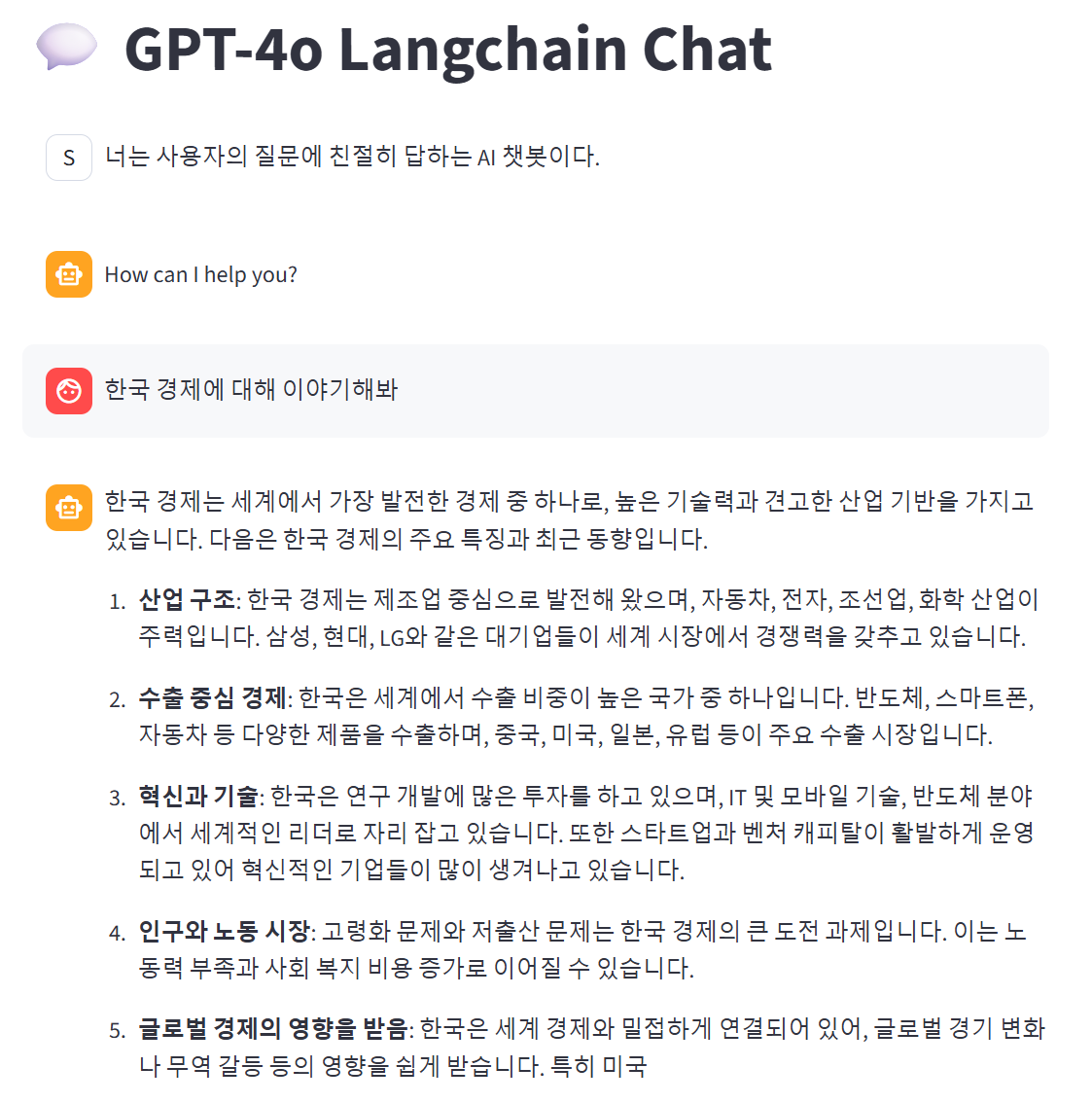
이 코드를 실행시키면 랭체인 메모리 없이 챗봇이 잘 작동한다
해당 파일은 다음 챕터에서 다시 활용할 예정이니 따로 저장해두도록 하자
langchain_stream_tool_0.py로 따로 저장해두었다
3. 도구 추가하고 스트림 방식으로 출력하기
앞에서 만들었던 파일에 이어서 실습을 진행해보자
현재 챗봇에서 현재 시각을 알려주는 도구를 추가하고 결과를 스트림 방식으로 출력해보려 한다
이전 챕터에서 만든 get_current_time 함수를 가져온다
그리고 tool로 연결해서 llm_with_tools로 정의한다
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from dotenv import load_dotenv
import os
load_dotenv()
from langchain_core.tools import tool
from datetime import datetime
import pytz
# 모델 초기화
llm = ChatOpenAI(model = "gpt-4o-mini")
# 도구 함수 정의
@tool
def get_current_time(timezone : str, location : str ) -> <str:
"""현재 시각을 반환하는 함수"""
try:
tz = pytz.timezone(timezone)
now = datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S")
result = f'{timezone} ({location}) 현재 시각 {now}'
print(result)
return result
except pytz.UnknownTimeZoneError:
return f"알수 없는 타임 존 : {timezone}"
# 도구 바인딩
tools = [get_current_time, ]
tool_dict = {"get_current_time" : get_current_time}
llm_with_tools = llm.bind_tools(tools)
# 사용자의 메세지를 처리하는 함수
def get_ai_response(messages):
response = llm_with_tools.stream(messages)
gathered = None
for chunk in response:
yield chunk
if gathered is None:
gathered = chunk
else:
gathered += chunk
if gathered.tool_calls:
st.session_state.messages.append(gathered)
for tool_call in gathered.tool_calls:
selected_tools = tool_dict[tool_call["name"]]
tool_msg = selected_tools.invoke(tool_call)
print(tool_msg, type(tool_msg))
st.session_state.messages.append(tool_msg)
for chunk in get_ai_response(st.session_state.messages):
yield chunk
# 스트림릿 앱
st.title("💬 GPT-4o Langchain Chat")
# 스트림릿 session_state에 메세지 저장
if "messages" not in st.session_state:
st.session_state["messages"] = [
SystemMessage(content = "너는 사용자의 질문에 친절히 답하는 AI 챗봇이다."),
AIMessage(content = "How can I help you?")
]
# 스트림릿 화면에 메세지 출력
for msg in st.session_state.messages:
if msg:
if isinstance(msg, SystemMessage):
st.chat_message("system").write(msg.content)
elif isinstance(msg, AIMessage):
st.chat_message("assistant").write(msg.content)
elif isinstance(msg, HumanMessage):
st.chat_message("user").write(msg.content)
elif isinstance(msg, ToolMessage):
st.chat_message("tool").write(msg.content)
# 사용자 입력 처리
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
response = get_ai_response(st.session_state["messages"])
result = st.chat_message("assistant").write_stream(response)
st.session_state["messages"].append(AIMessage(result))
- def get_ai_response() 함수의 내부에서
response = llm_with_tools.stream(messages) 으로 변경
- gathered = None
도구를 사용한 결과를 처리할 수 있도록 gathered 를 None으로 처리함
- if gathered.tool_calls:
도구를 사용하지 않을 경우 gathered.tool_calls에는 아무 값도 들어있지 않다
하지만 도구를 사용할 경우는 필요한 도구와 매개변수를 확인하고 실행한다
- for chunk in get_ai_response(st.session_state.messages):
도구를 다 실행하고 결과를 받은 후, 해당 결과를 해석하는 AIMessages를 받아오기 위해 다시 한번 get_ai_response() 함수를 사용한다
- elif isinstance(msg, ToolMessage):
기존 메세지들을 출력하는 부분에서 ToolMessage도 스트림 방식으로 출력된 결과에 맞춰 스트림릿에 출력되도록 수정한다
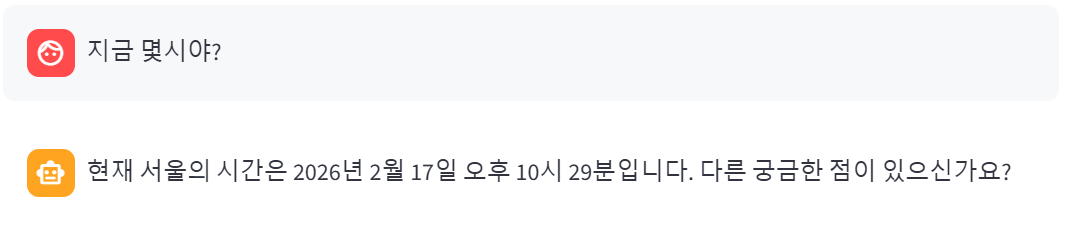
4. 마무리
이렇게 스트림릿에서 스트림 방식으로 출력을 하면서 멀티턴 대화 구현 + 도구를 사용하기 까지 해보았다
이전 챕터에서 한 멀티턴 대화 구현, 도구 사용해보기, 랭체인 메모리 구현이 갑자기 한데 모여서 약간 코드를 이해하는데 어려움이 있었다
특히 스트림릿에서 st.session_state와 st.chat_message 같은 스트림릿 관련 함수들이 꽤나 많이 헷갈리더라...
다음 챕터에서는 RAG를 배우고 실습해보려고 한다
LLM을 공부할 때 제일 많이 들었던게 랭체인, 랭그래프, RAG 인데 꽤나 유용하게 쓰이기에 유명하지 않을까란 생각에 은근 기대가 된다
