
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 18일 기준으로 작성되었습니다.
Chapter 8
RAG로 문서에 기반해 답변하는 챗봇 만들기
본 포스팅에서는 RAG가 무엇인지 배워보겠습니다
기본적인 수학 내용이 들어갈 예정입니다!!
1. 언어 모델과 RAG의 작동 방식
GPT와 같은 언어 모델을 이전 문장을 기반으로 다음에 나올 문장을 확률적으로 계산하고
가장 가능성이 높다고 판단되는 단어와 문장을 생성한다
즉, 언어모델을 기억하거나 생각하는게 아니라 과거에 학습한 데이터를 기반으로 계산된 결과를 내놓을뿐이다
따라서 질문과는 맞지 않는 엉뚱한 답변을 하는 환각 현상(Hallucination)이 발생한다
RAG는 이런 환각 현상을 줄이는 방법 중에 하나이다
리트리버가 데이터 조각들을 미리 쌓아두고 질문이 들어오면 유사한 데이터 조각을 신속하게 찾아서 언어 모델에게 건네며 이것을 기반으로 답변하라고 알려주는 방식이다
이렇게 하면 언어 모델이 학습하지 않은 정보에 대해서도 답변할 수 있고 실수할 확률이 크게 줄어든다
2. 기본적인 언어 모델의 답변과 RAG의 차이
GPT 같은 언어 모델에 질문하면 언어 모델은 그 질문의 답이 될 가능성이 높은 내용을 기반으로 답변을 구성한다
따라서 학습 시점 이후의 내용을 물어보면 대답할 수 없다
예를 들어 2024년 3월에 학습이 완료된 모델은 2024년 9월에 출시된 아이폰 16에 대해 대답을 할 수 없는 것이다
또한 너무 광범위한 질문에 대해서는 답변을 제대로 할 수 없다
'올해 한국의 발전 계획이 뭐야?' 라고 물어본다면 실제 문서에 기반한 내용이 아니라 일반적인 발전 계획으로 답변을 하게 된다
이러한 문제를 RAG를 이용해서 해결할 수 있다
RAG를 이용하면 질문과 관련된 문서를 찾아 그 문서를 바탕으로 답변할 수 있기 때문이다
또한 언어 모델이 답변을 만드는데 사용한 문서의 출처도 사용자에게 알려줄 수 있따

3. 청킹 : 대량의 문서를 쪽지 단위로 자르기
GPT에게 한번에 많은 양의 문서를 주고 답변을 해달라고 요청할 수도 있지만 좋은 방법이 아니다
아래와 같은 문제가 발생한다
- 언어 모델이 한 번에 처리할 수 있는 텍스트 길이를 초과할 수 있다
- 언어 모델이 문서에서 필요한 정보를 제대로 찾지 못할 수 있다
- 대화형 방식으로 진행할 경우 매번 수백 페이지의 문서를 언어 모델에 입력하게 되므로 높은 토큰 비용이 발생한다
컨텍스트 윈도우(Context Window)는 언어 모델이 한 번에 처리할 수 있는 텍스트 길이의 한계를 의미한다
이 길이를 초과하는 텍스트를 입력할 경우 언어 모델이 처리하지 못해 오류가 발생하거나 텍스트의 일부만으로 대답한다
또한 사람도 300페이지 논문을 주고 해당 내용을 찾으라고 하면 필요한 부분을 찾아내리 어렵듯
언어 모델도 마찬가지로 데이터가 너무 많으면 필요한 정보를 찾는데 어려움이 있다
또한 PDF 한 쪽당 약 800토큰이 소모된다고 칠때 300쪽 PDF라면 약 24만 토크가 필요하고
2025년 4월 기준으로 100만 토큰당 5달러가 필요하므로 언어 모델에 PDF 문서를 한번 입력하는데 약 1500원 정도가 필요할 것이다
RAG는 이러한 문제들을 해결하기 위해 대량의 문서를 쪽지 단위로 나누는 청킹(Chunking) 작업을 진행한다
그리고 이렇게 나누어진 쪽지를 청크(Chunk)라고 한다
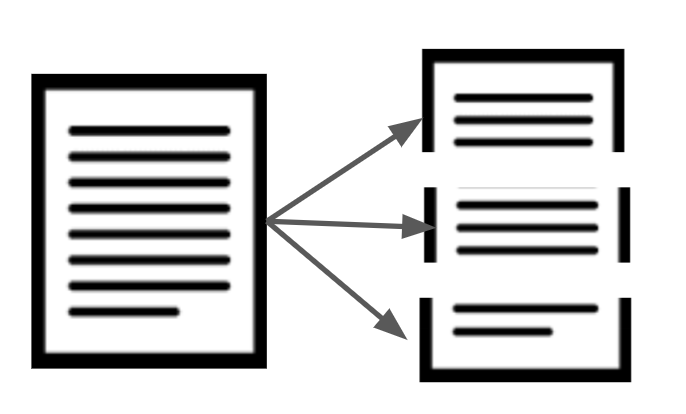
청크의 크기는 문서나 언어 모델에 따라 다르며, 일반적으로 언어 모델의 토큰당 비용과 처리할 수 있는 결과를 고려해서 결정한다
RAG는 이렇게 청크 단위로 문서를 나누고 사용자의 질문과 가장 유사한 청크 몇 개를 찾아서 질문과 함게 언어 모델에 전달하여 문서에 기반한 답변을 생성한다
4. 임베딩 : 텍스트를 벡터로 변환하기
문서를 청크 단위로 나눈 후 사용자의 질문과 관련 있을 가능성이 높은 청크를 어떻게 찾을 수 잇을까??
에를 들어 '서울시 상암동의 발전 계획이 뭘까?' 라는 질문에 답변하려면 문서에서 있는 모든 청크 중에서 가장 관련 있는 몇개를 골라야한다
청크는 보통 5개를 선택하는데 이 개수는 여러 번 실험을 통해 결정한다
그 후 텍스트 간의 유사도를 비교하는 과정을 거친다 유사도를 수학적으로 비교하려면 텍스트를 수치 정보로 바꿔야 한다
이를 위해 각 청크의 텍스트를 벡터 공간의 숫자 형태로 변환하는 과정이 필요하며 이 과정을 임베딩(Embedding)이라고 한다
- 벡터와 임베딩
정보를 수치로 표현해서 일렬로 나열한 것을 벡터라고 한다
예를 들어 [키, 몸무게, 위도, 경도, 출생연도]라는 원소가 5개인 5차원 벡터로 사람을 표현한다고 해보자
이때 마이클 조던은 [198, 98, 40.67, -73.94, 1963], 일론 머스크는 [188, 82, 30.27, -97.74 ,1971]로 표현할 수 있을것이다
이렇게 표현한다면 사람 정보를 5차원 벡터에 임베딩한다고 표현한다
이제 이렇게 표현된 벡터들 간의 유사성을 계산하는 방법을 알아보자
5차원은 종이에 표현하기 어려우니 일단 2차원 벡터 공간에 단어를 표현하는 방법을 살펴보자
예를 들어 카페 음료 메뉴만 있다고 생각했을 때, x축은 음료의 바디감, y축은 음료의 온도를 의미한다
이렇게 음료 종류를 2차원 벡터 공간으로 임베딩하여 표현할 수 있다
책에서는 위와 같은 이미지로 설명을 하고 있다
- 코사인 유사도
위 그래프에서 모카와 우유를 나타내는 두 벡터가 이루는 각도가 아메리카노와 아이스 아메리카노를 나타내는 두 벡터 사이의 각도보다 좁다
이것은 (모카, 우유)의 관계가 (아메리카노, 아이스 아메리카노)의 관계보다 더 유사하다는 것을 나타낸다
이렇게 두 벡터 사이의 각도를 이용하면 음료 간의 유사도를 계산할 수 있다
각도가 180도에 가까우면 유사도가 낮고, 각도가 0도에 가까울수록 유사도가 높다
유사도를 계산하는 방식은 코사인 유사도(Cosine Similarity)를 이용한다
두 벡터 A와 B가 있을 때, 벡터의 내적을 이용해서 두 벡터 사이의 각도의 코사인 값은 아래와 같이 나타낸다
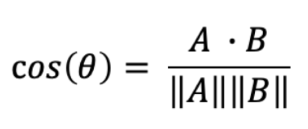
물론 RAG를 이용할 때 이 과정을 직접 게산할 필요는 없다
이미 다른 사람들이 만들어 놓은 도구들이 있을것이고 우리는 그것을 잘 이용하면 된다!!
종이에서는 2차원만 표현할 수 있지만, 해당 방식만 알고 있다면 고차원 벡터의 유사도도 계산할 수 있다
- 임베딩 모델의 중요성
임베딩을 통해 벡터로 변환된 데이터를 기반으로 유사도를 계산할 수 있지만 임베딩 방식에 따라 유사도 결과는 달라질 수 있다
예를 들어 카페 음료 메뉴를 바디감과 온도를 기준을 임베딩했을 때 그 결과가 만족스럽지 않을 수 있다
앞에서처럼 (아메리카노, 아이스 아메리카노)의 관계보다 (카페 모카, 우유)의 관계가 더 가깝다고 나올 수도 있다
이처럼 벡터 공간에서 유사도는 임베딩을 어떻게 하는지에 따라 완전히 다르게 평가될 수도 있다
실제로 임베딩하는 모델은 훨씬 더 고차원의 벡터 공간으로, 직관적으로 이해하기 어려운 방식으로 데이터를 변환한다
임베딩 방법은 매우 다양하므로 텍스트를 벡터로 변환하는 모델도 많이 존재한다
또한 언어나 특정 분야에 따라 더 적합한 임베딩 모델이 있을 수 있으며, 필요한 경우 모델을 파인튜닝하여 성능을 개선하기도 한다
5. 벡터 DB와 리트리버
벡터 DB(Vector DB) 는 벡터로 변환된 결과를 저장하고 텍스트 간의 유사도를 계산하여 사용자가 입력한 질문과 가장 유사한 청크를 찾아낼 때 유용하다
벡터 DB는 고차원 벡터에서 의미의 유사성을 빠르게 계산하고 그 결과를 반환하는데 최적화되어있다
현재 사용하는 벡터 DB로는 크로마 DB, FAISS, 파인콘 등이 있다
나중에 크로마 DB를 이용하는 실습을 할 예정이다
리트리버(Retriever) 는 사용자가 질문한 정보에 적절한 답을 생성하는 데 필요한 데이터를 가져오는 역할을 한다
벡터 DB에 저장된 내용 중에서 유사도가 가장 높은 청크를 찾아서 가져온다
6. 질의 확장
리트리버는 사용자의 질의를 벡터로 변환한 뒤 그 벡터와 유사성이 높은 청크를 검색한다
따라서 사용자의 질의가 명확하지 않고 이해하기 어려우면 적절한 청크를 가져올 확률이 낮아진다
즉, 사용자의 마지막 질문을 그대로 검색하는 대신 질문의 문맥을 파악하여 적절한 질문으로 변환한 뒤,
그 질문을 벡터로 임베딩하여 검색하는 과정이 필요하다
이렇게 사용자의 질문을 더 명확하게 수정하는 작업을 질의 확장 (Query Augmentation) 이라 한다
7. 마무리
이번 책을 계속 따라하면서 거의 처음으로 수학적인 이론 (매우 간단하지만)이 나오고, 용어에 대한 설명이 나온 것 같다
다행히 해당 내용들은 학교에서 수업을 들을 때, 인공지능 관련 과목에서 다 들어본 내용이어서 이해하기에 어렵지는 않았다
다음 포스팅부터 본격적으로 실습할 예정이다!!
미리 코드를 살펴보니까 은근 복잡하던데... 열심히 이해해보려고 노력해봐야겠다!
