
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 25일 기준으로 작성되었습니다.
Chapter 9
인터넷 검색을 활용해 답변하는 챗봇 만들기
본 포스팅에서는 기존 챗봇에 인터넷 검색 기능을 추가해보려고 합니다!
1. GPT에 인터넷 검색 기능 추가하기
랭체인에는 구글 검색, 빙 검색, 덕덕고 검색 등 다양한 도구를 제공하여 인터넷 검색 기능을 추가할 수 있다
이번에는 무료로 사용할 수 있는 덕덕고 검색 엔진을 사용해보려고 한다
덕덕고는 '사용자의 데이터를 수집하지 않는다'는 메세지를 내세우는 검색엔진이다
또한, 무료 API를 제공하므로 검색 결과를 언어 모델과 결함한 프로그램을 개발하려는 사람에게 유용하다!!
GPT에게 2026년 2월 25일 기준 화제가 되는 뉴스 중 하나인 '밀가루 가격 담합'에 대해 물어본다면 제대로 대답하지 못한다가격 담합'에 대해 물어본다면 제대로 대답하지 못한다
GPT 모델 자체는 학습한 시점까지의 정보만 갖고 있기 때문이다
이 단점을 극복하기 위해 GPT에 인터넷 검색기능을 추가해보자
duckduckgo.ipynb 파일을 만들고 언어모델을 gpt-4o-mini로 설정한다
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
model.invoke("최근 대한민국의 밀가루 가격 담합 사건에 대해 알려줘")
해당 코드를 실행시키면 2026년의 사건이 아니라 2023년의 정보를 제공하고 있는 것을 알 수 있다
이제 덕덕고 검색을 활용해 웹 검색 기능을 추가해보려한다
검색을 위한 라이브러리 설치를 하자
%pip install -U duckduckgo-search
%pip install -U ddgs이제 DuckDuckGoSearchResults 클래스를 이용해서 덕덕고에서 검색 결과를 가져오는 코드를 작성해보자
results_seperator 파라미터를 ';\n'으로 설정해서 검색 결과를 구분하는 방식을 지정하고
.invoke() 메소드를 이용해 검색 쿼리를 전송하자
from langchain_community.tools import DuckDuckGoSearchResults
search = DuckDuckGoSearchResults(results_separator=';\n')
docs = search.invoke("최근 대한민국의 밀가루 가격 담합 사건에 대해 알려줘")
print(docs)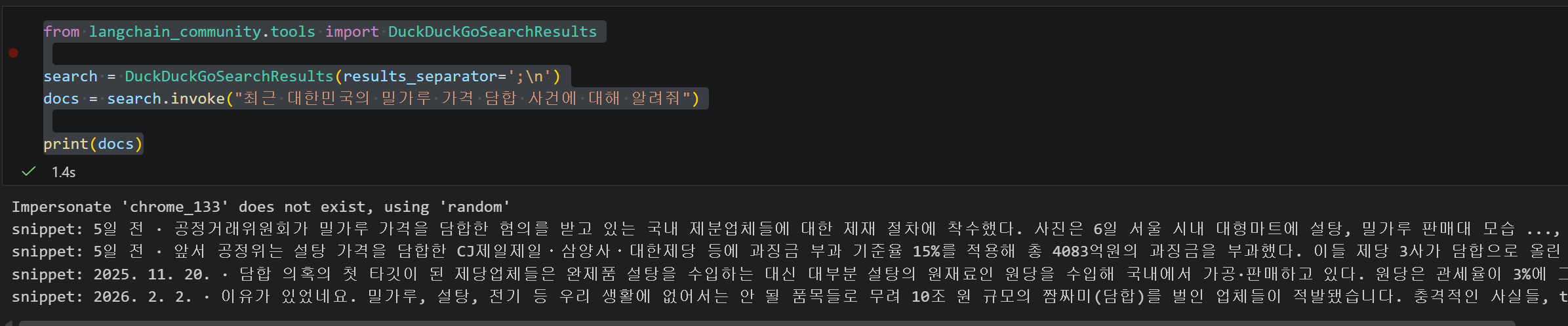
이전 답변과는 다르게 5일전 기사도 확인할 수 있고 2025년 말의 기사도 확인할 수 있다
이제 이 웹 검색을 문맥에 더 잘 수행하기 위해 질의 확장을 구현해보자
저번 챕터의 포스팅에서 RAG를 구현할 때 사용한 프롬프트와 체인코드를 재활용할 예정이다
question_answering_prompt 코드는 그대로 가져오고
document_chain은 LCEL 방식으로 프롬프트 바로 뒤에 | 연산자를 이용하여 GPT 모델만 연결하여 구현한다
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"사용자의 질문에 대해 아래 context에 기반해 답변해라.:\n\n{context}",
),
MessagesPlaceholder(variable_name = "messages"),
]
)
document_chain = question_answering_prompt | model사용자와 나눈 메세지를 저장하고 그 내용을 활용해 document.chain을 AI 답변을 생성한다
그리고 AI의 메세지를 저장하고 결과를 출력하도록 한다
이 코드도 지난 포스팅에서 RAG를 만들 때 썼던 코드를 재활용해보자
from langchain_community.chat_message_histories import ChatMessageHistory
# 채팅 메세지를 저장할 메모리 객체 생성
chat_history = ChatMessageHistory()
# 사용자 질문을 메모리에 저장
chat_history.add_user_message("최근 대한민국의 밀가루 가격 담합 사건에 대해 알려줘")
# 문서 검색하고 답변 생성
answer = document_chain.invoke(
{
"messages" : chat_history.messages,
"context" : docs,
}
)
# 생성된 답변 메모리에 저장
chat_history.add_ai_message(answer)
print(answer)이 코드를 이용하면 docs에는 최근 밀가루 가격 담합에 대한 기사가 들어가 있어서 AI가 이를 이용해서 답변을 생성해줄 것이다
content='최근 대한민국에서 밀가루 가격 담합 사건이 발생하여 공정거래위원회가 제재 절차에 착수했습니다.
이 사건은 국내 제분업체들이 밀가루 가격을 담합한 혐의로 제기되었습니다.
공정위는 이미 설탕 가격 담합 사건에서도 크게 부과된 과징금을 바탕으로 밀가루 담합에 대해서도 초강수를 두고 가격 재결정을 검토 중입니다.
제재 절차는 최근 몇일 전에 시작되었으며, 담합 혐의를 받고 있는 제분업체들에 대한 조사가 진행되고 있습니다.
이로 인해 사회적으로 중요한 품목인 밀가루 가격의 조정이 필요한 상황입니다.'2. 검색 기능에 옵션 설정하기
답변에 사용할 정보를 최근 소식이나 뉴스, 특정 웹 사이트로만 한정하고 싶을 수도 있다
이런 경우에 API 래퍼(Wrapper)를 이용해 검색 옵션을 설정할 수 있다
최신 뉴스 기사만 검색해보도록 설정해보자
DuckDuckGoSearchAPIWrapper를 활용해 검색 지역과 기간을 설정한다
# DuckDuckGo API 래퍼를 이용해 검색할 대 검색 매개변수를 설정하는 클래스 import
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
# 한국 지역("kr-kr") 기준, 최근 일주일('w') 내의 검색 결괄르 가져오도록 초기화
wrapper = DuckDuckGoSearchAPIWrapper(region="kr-kr", time="w")이렇게 설정한 wrapper를 DuckDuckGoSearchResults에 api_wrapper 매개변수에 넘겨준다
# 검색 기능을 위한 DuckDuckGoSearchResults 초기화
serach = DuckDuckGoSearchResults(
api_wrapper = wrapper, # 앞에서 정의한 API 래퍼 사용
source = "news", # 뉴스 검색 결과만 가져오도록 설정
results_separator=';\n' # 결과 항목 사이에 구분자 사용 (세미콜론, 줄바꿈)
)그리고 이전과 같은 질문을 하여 어떤 결과가 나오는지 확인해보자
docs = search.invoke("최근 대한민국의 밀가루 가격 담합 사건에 대해 알려줘")
print(docs)검색 기간을 최근 1주일로 설정하니까 2일전, 5일전의 기사들이 검색되는 것을 볼 수 있다

3. 특정 웹사이트에서 검색하기
인터넷 전체가 아닌 특정 웹사이트에서 검색 결과를 가져올 수도 있다
search.invoke() 쿼리문에 site:ytn.co.kr을 이용해 특정 웹사이트를 지정하고 검색을 진행해보자
site:(원하는 웹사이트 주소)를 이용하면 ytn.co.kr 이외에도 특정 웹사이트에서 검색할 수 있다
# DuckDuckGo를 이용해 ytn.co.kr 웹사이트에서 최근 일주일간의 뉴스 검색 결과 가져오기
docs = search.invoke("site:ytn.co.kr 최근 대한민국의 밀가루 가격 담합 사건에 대해 알려줘")
print(docs)이 코드를 실행하면 'ytn.co.kr'인 웹사이트에서 검색한 내용만 결과로 보여준다

4. 기사 링크 가져오기
지금까지의 검색 결과를 보면 snippet과 제목을 활용한 짧은 내용으로 결과가 생성된 것을 알 수 있다
상황에 따라 검색된 링크의 본문 내용까지 자세히 알고싶을 수 있다
DuckDuckGoSearchResults로 검색한 결과에는 페이지의 링크가 포함되어있으므로 URL을 이용해 웹 페이지의 텍스트를 가져와보자
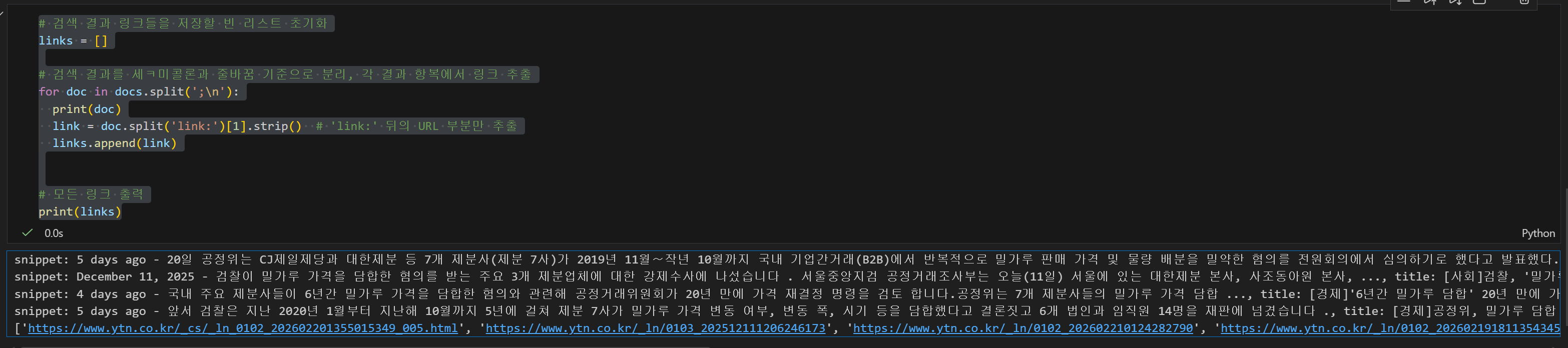
# 검색 결과 링크들을 저장할 빈 리스트 초기화
links = []
# 검색 결과를 세ㅋ미콜론과 줄바꿈 기준으로 분리, 각 결과 항복에서 링크 추출
for doc in docs.split(';\n'):
print(doc)
link = doc.split('link:')[1].strip() # 'link:' 뒤의 URL 부분만 추출
links.append(link)
# 모든 링크 출력
print(links)가장 아래 줄에 links 리스트가 실제 기사의 링크로 이루어져 있는 것을 볼 수 있다
이제 각 기사의 링크를 클릭할 때 열리는 웹 페이지의 내용을 가져와보도록 하자
랭체인에서 제공하는 WebBaseLoader를 사용하면 링크의 내용을 가져올 수 있다
# 랭체인의 WebBaseLoader를 사용하여 웹 페이지의 내용 불러오기
from langchain_community.document_loaders import WebBaseLoader
# WebBaseLoade 개체 생성
# bs_get_text_kwargs는 BeautifulSoup의 get_text() 메서드에 전달되는 인자
loader = WebBaseLoader(
web_path = links, # 앞에서 추출한 링크 리스트
bs_get_text_kwargs={
"strip" : True, # 텍스트 양쪽의 공백 제거
}
)
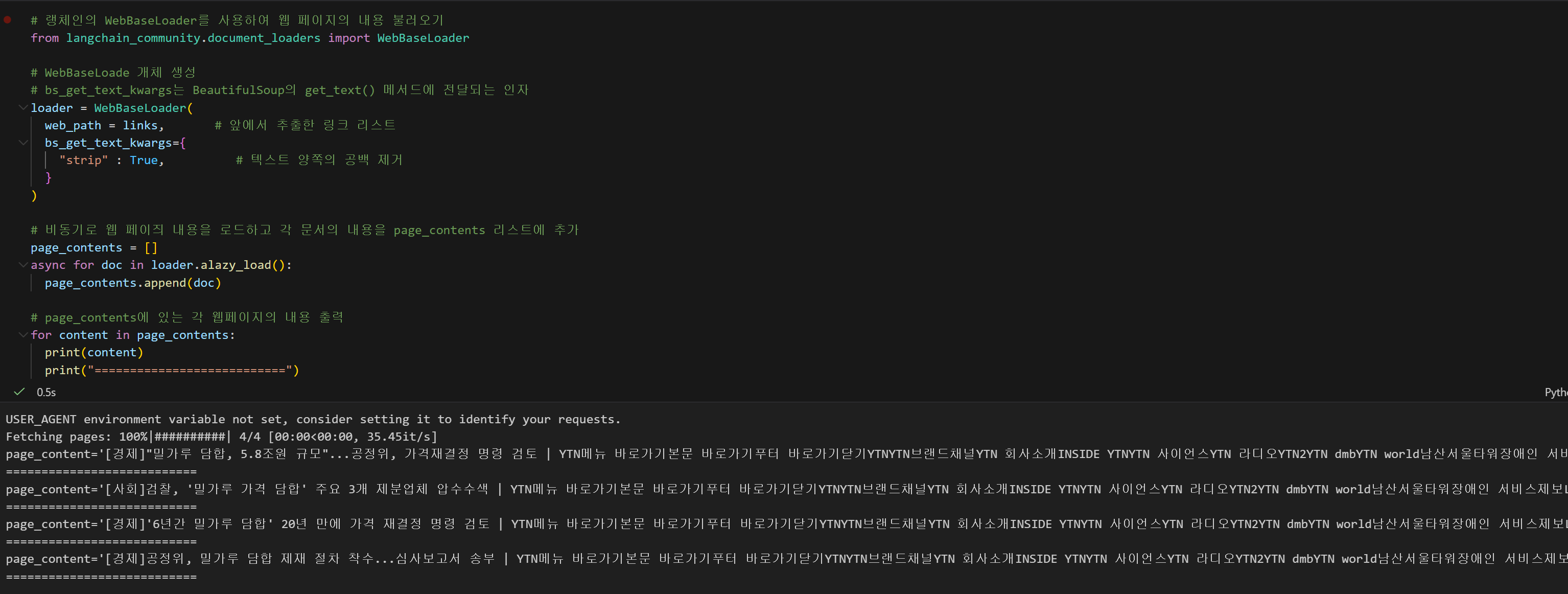
# 비동기로 웹 페이즤 내용을 로드하고 각 문서의 내용을 page_contents 리스트에 추가
page_contents = []
async for doc in loader.alazy_load():
page_contents.append(doc)
# page_contents에 있는 각 웹페이지의 내용 출력
for content in page_contents:
print(content)
print("===========================")해당 코드를 실행하면 실제 기사 내용들을 긁어온 것들을 볼 수 있따
다만 웹페이지에 들어갔을 때 상단과 하단, 메뉴바에 포함되는 모든 텍스트들이 포함되어있어서 내용을 보기에는 약간 불편한 감이 있다
5. BeautifulSoup를 이용해 특정 영역만 가져오기
위에서 확인했듯이 텍스트를 대부분 가져오면 불필요한 영역의 텍스트도 많이 포함된다
따라서 필요한 부분의 텍스트만 가져오도록 설정해보자
BeautifulSoup를 활용하면 웹 페이지에서 원하는 특정 영역의 텍스트만 가져올 수 있다
BeautifulSoup는 파이썬에서 HTML이나 XML 문서를 쉽게 파싱할 수 있도록 도와주는 라이브러리로,
웹페이지의 구조를 분석하고 특정 태그의 텍스트 등 원하는 요소를 쉽게 추출하게 해준다
위의 links 리스트에 있는 기사 링크 중에 하나를 클릭해서 F12를 누르면 오른쪽에 개발자 도구를 확인할 수 있다
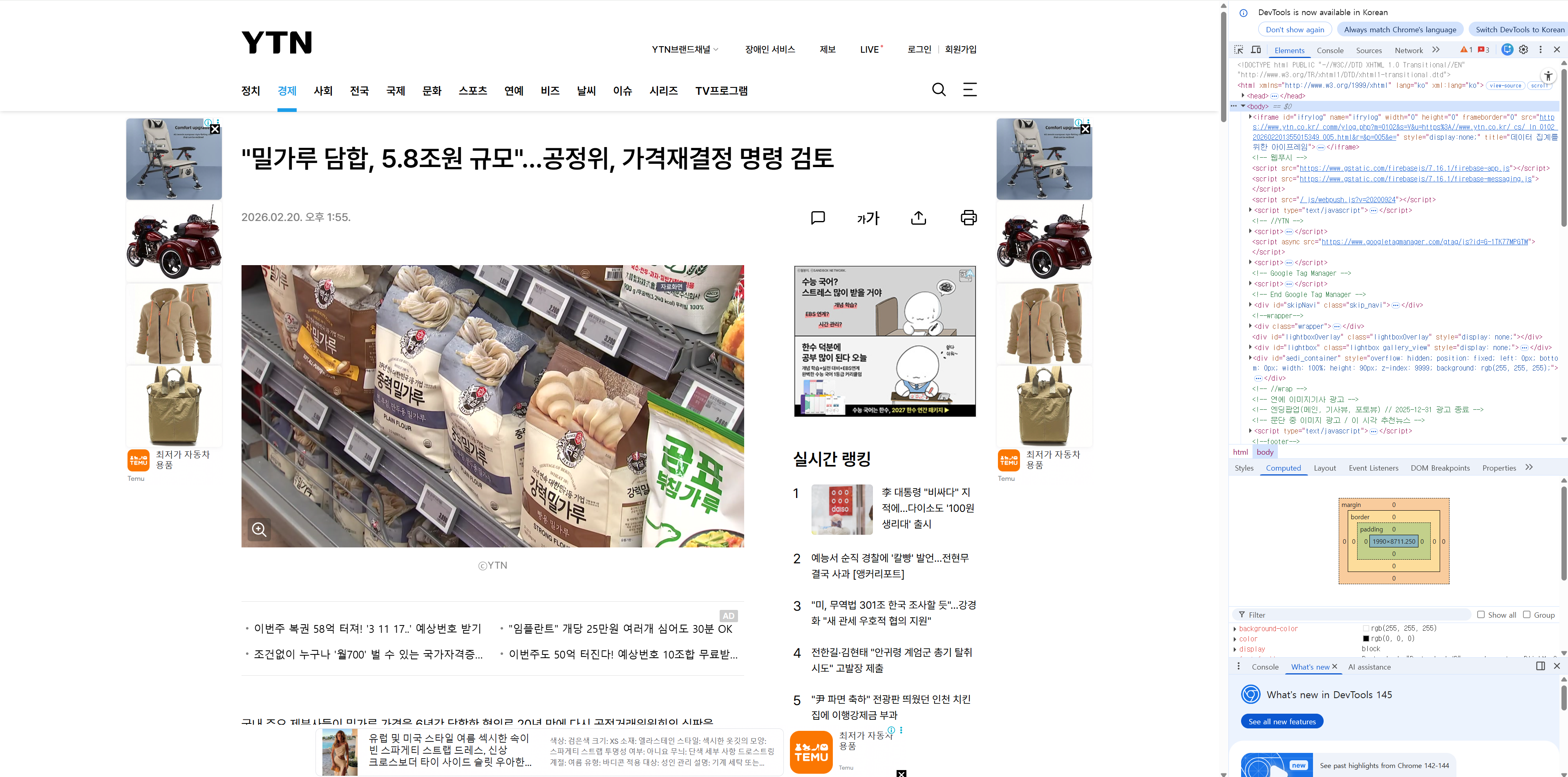
여기서 실제로 우리가 원하는 기사의 본문 내용이 어느 태그에 포함되어 있는지 확인해보자
웹 사이트마다 기사나 본문을 표시하는 영역 설정이 다르므로 직접 이 영역을 찾아야 한다
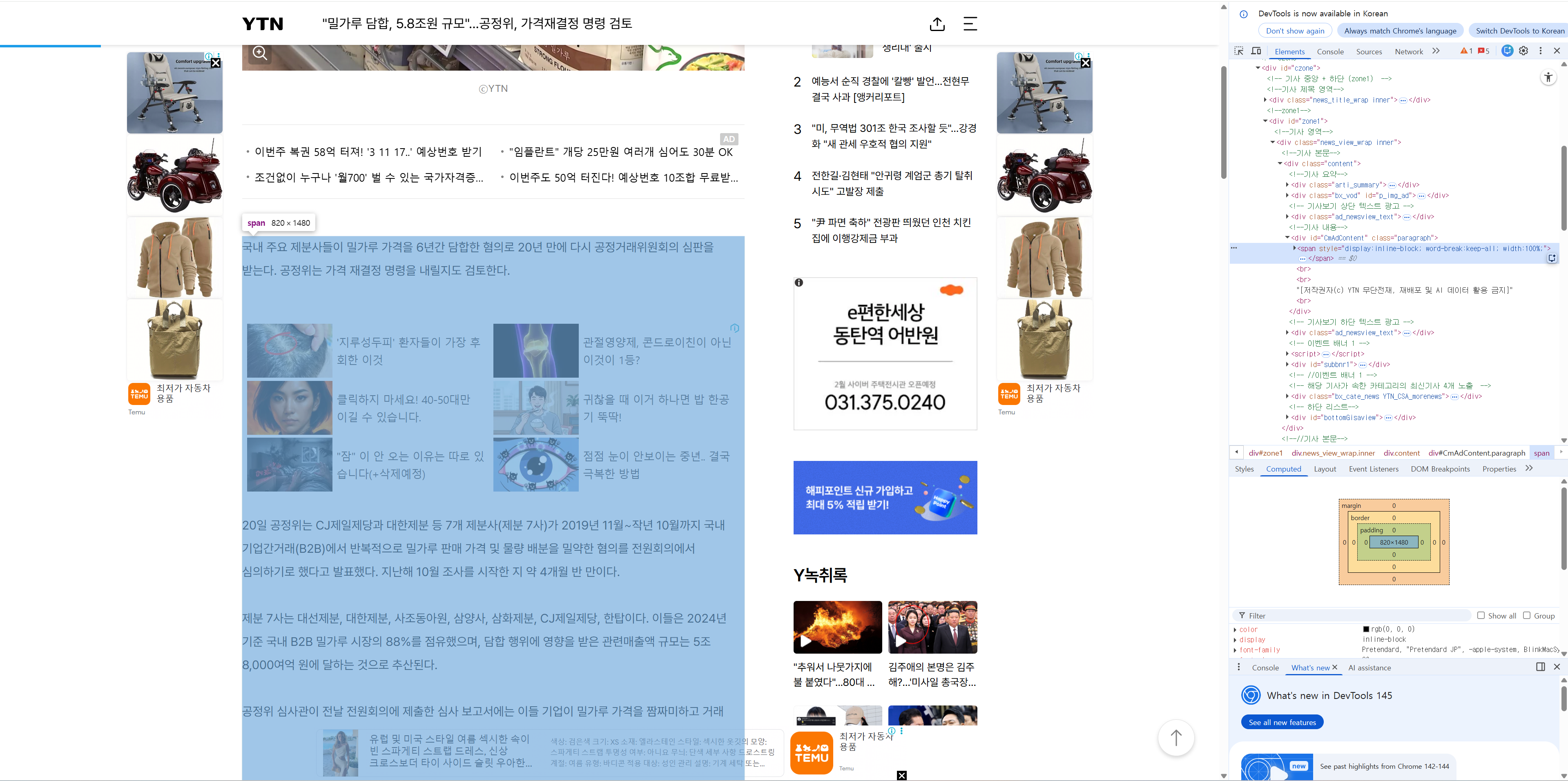
ytn 기사에서는 div id = "CmAdContent" class = "paragraph" 에 있는 span 태그 안에 기사 본문이 있었다

이 태그에 해당하는 내용을 가져올 수 있도록 함수를 작성해보도록 하자
import requests
from bs4 import BeautifulSoup
# 주어진 URL에서 기사 텍스트를 가져오는 함수
def get_article_text(url):
try:
# URL에 GET 요청을 보냄
response = requests.get(url)
# 요청이 성공하지 않으면 예외 발생
response.raise_for_status()
# BeautifulSoup를 이용해서 HTML 내용 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 클래스가 paragraph인 <div> 태그 찾기
article = soup.find('div', class_ = 'paragraph')
# 기사를 찾았다면 그 텍스트를 반환
if article:
return article.get_text(strip = True)
# 요청이 실패할 경우 예외처리
except requests.RequestException as e:
return f"URL을 가져오는 중 오류 발생 : {e}"
그리고 이 함수를 이용해서 기사 내용을 받아오자
# URL 목록의 각 링크를 반복하면서 기사 텍스트 출력
articles = []
for link in links:
print(f"URL : {link}\n")
article_text = get_article_text(link)
print(f"Content : \n{article_text}")
print("============================")
articles.append(article_text)이 코드를 실행시키면 이전과는 달리 기사의 본문만 깔끔하게 읽어온 것을 볼 수 있다

이렇게 특정 웹사이트로 검색 범위를 한정하면 언어 모델에게 넘겨주는 텍스트를 깔끔하게 정리할 수 있다
하지만 이런 결과를 얻기 위해서는 해당 웹 페이지의 소스 코드를 분석하고
BeautifulSoup를 이용해 원하는 부분의 텍스트를 추출할 수 있어야 한다
6. 마무리
GPT에 인터넷 검색 기능을 추가하는 실습을 진행해보았다
지금까지 GPT만을 이용해왔는데 지금까지 배워온것만 이용해도 기존보다 더 똑똑하게 GPT를 사용할 수 있을것 같은 생각이 들었다
BeautifulSoup의 경우 학교에서 수업을 들을 때 과제를 하면서도 사용할 수 있어서 조금 쉽게 접근할 수 있었던것 같다
이렇게 특정 분야에 대해서 언어모델을 사용할 경우 (예 : 현재 화제가 되는 기술 / 뉴스 / IT 내용 등)
훨씬 빠르게 기사 내용을 파악하고 요약할 수 있지 않을까...
