
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 24일 기준으로 작성되었습니다.
Chapter 8
RAG로 문서에 기반해 답변하는 챗봇 만들기
본 포스팅에서는 저번 챕터에서 만든 스트림릿 코드를 응용해서 RAG를 활용한 챗봇을 완성해보려고 합니다!
1. 스트림릿 코드에 리트리버 추가하기
이전 포스팅에서 만든 코드를 활용해 질의응답 시스템을 만들어보자
retriever.py 파일을 만들고 rag_practice.ipynb 파일에서 관련 코드를 복사해서 가져오자
그리고 persist_directory의 폴더 경로를 절대 경로로 수정하자
이렇게 절대 경로를 설정하면 어떤 폴더에서 실해해도 크로마 DB의 위치를 확실하게 지정할 수 있다
크로마 DB는 이전 포스팅의 DB를 그대로 사용하려 한다
# retriever.py
# 임베딩 모델 선언하기
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
embedding = OpenAIEmbeddings(model = "text-embedding-3-large", api_key = OPENAI_API_KEY)
# 언어모델 선택하기
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model = "gpt-4o")
# Load Chroma store
from langchain_chroma import Chroma
print("Loading existing Chroma store")
persist_directory = 'C:\\Users\\user\\Desktop\\Coding\\LLM\\chap9\\chroma_store'
vectorstore = Chroma(
persist_directory = persist_directory,
embedding_function = embedding,
)
# Create retriever
retriever = vectorstore.as_retriever(k = 3)
# Create document chain
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"사용자의 질문에 대해 아래 context에 기반해 답변해라.:\n\n{context}",
),
MessagesPlaceholder(variable_name = "messages"),
]
)
document_chain = create_stuff_documents_chain(llm, question_answering_prompt) | StrOutputParser()
# Query Augmentation Chain
query_augmentation_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name = "messages"), # 기존 대화 내용
(
"system",
"기존의 대화 내용을 활용하여 사용자가 질문한 의도를 파악해서 한 문장의 명료한 질문으로 변환하라 대명사나 이, 저, 그와 같은 표현을 명확한 명사로 표현하라:\n\n{query}"
)
]
)
query_augmentation_chain = query_augmentation_prompt | llm | StrOutputParser()일단 RAG를 구현하기 전에 오픈AI의 API를 활요해 기본적인 대화를 할 수 있는 코드를 만들어보자
rag.py 파일을 만들고 예전에 저장해둔 langchain_streamlit_tool_0.py 파일의 코드를 붙여넣으면 된다
그리고 위에서 만든 retriever를 가져오기 위해 import를 해준다
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from dotenv import load_dotenv
import os
load_dotenv()
# 앞에서 만든 retriever 파일을 가져온다
import retriever
# 모델 초기화
llm = ChatOpenAI(model = "gpt-4o-mini")
# 사용자의 메세지를 처리하는 함수
def get_ai_response(messages):
response = llm.stream(messages)
for chunk in response:
yield chunk
# 스트림릿 앱
st.title("💬 GPT-4o Langchain Chat")
# 스트림릿 session_state에 메세지 저장
if "messages" not in st.session_state:
st.session_state["messages"] = [
SystemMessage(content = "너는 문서에 기반해 답변하는 도시 정책 전문가야"),
]
# 스트림릿 화면에 메세지 출력
for msg in st.session_state.messages:
if msg:
if isinstance(msg, SystemMessage):
st.chat_message("system").write(msg.content)
elif isinstance(msg, AIMessage):
st.chat_message("assistant").write(msg.content)
elif isinstance(msg, HumanMessage):
st.chat_message("user").write(msg.content)
# 사용자 입력 처리
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
print("user\t : ", prompt)
augmented_query = retriever.query_augmentation_chain.invoke({
"messages" : st.session_state["messages"],
"query" : prompt,
})
print("augmented_query\t : ", augmented_query)
with st.spinner(f"AI가 답변을 준비 중입니다... '{augmented_query}'"):
response = get_ai_response(st.session_state["messages"])
result = st.chat_message("assistant").write_stream(response) # AI 메세지 출력
st.session_state["messages"].append(AIMessage(result)) # AI 메세지 저장
- st.session_state["messages"] = [SystemMessage(content = "너는 문서에 기반해 답변하는 도시 정책 전문가야"),]
우리가 준비한 크로마 DB에는 서울과 뉴욕의 도시 정책 계획 문서가 담경있으므로 프롬프트도 이에 맞게 수정한다
- augmented_query = retriever.query_augmentation_chain.invoke({
"messages" : st.session_state["messages"],
"query" : prompt,
})
사용자가 입력한 prompt를 이용해서 확장된 질의를 만든다
messages와 query 변수를 딕셔너리로 묶어 invoke 메소드를 이용해 전달한다
- with st.spinner(f"AI가 답변을 준비 중입니다... '{augmented_query}'"):
어떤 질문에 답변을 생성하는지 보여주는 요소와 문구를 추가한다
이제 이 코드를 터미널 창에서 streamlit run (파일명).py를 이용해서 실행해보자
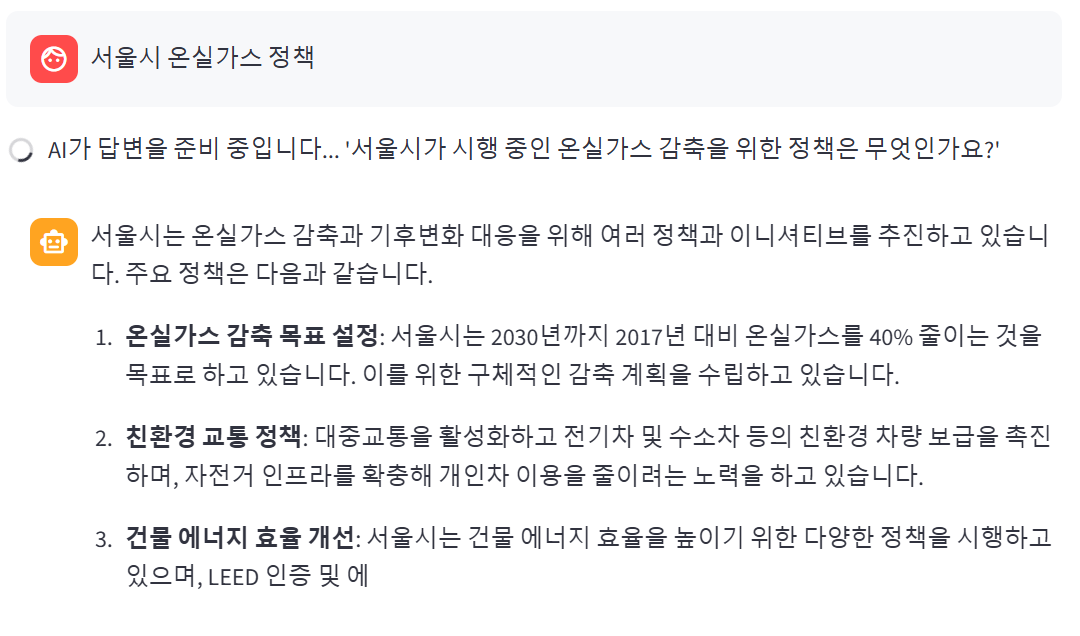
스트림릿에서 질문을 하면 st.spinner를 사용한 보람이 있게 답변을 준비하면서 스트림 방식으로 출력이 되는 것 까지 확인할 수 있다
답변 내용에 년도가 구체적으로 포함되어 있어서 그럴싸한 답변으로 보이지만 현재 코드에서는 크로마DB에 담긴 문서를 이용해서
답변을 생성하는 코드를 추가하지 않았기에 문서에 기반한 답변이라고 보기는 어렵다
RAG를 구현하기 위해 get_ai_response함수에 리트리버를 추가해보자
# 사용자의 메세지를 처리하는 함수
def get_ai_response(messages, docs):
response = retriever.document_chain.invoke({
"messages" : messages,
"context" : docs
})
for chunk in response:
yield chunk그리고 이 get_ai_response 함수를 사용하기 위해 코드를 추가한다
retriever.py 에 있는 retriver를 이용해 관련 문서를 검색해서 docs에 담고 그 결과를 출력한다
그리고 get_ai_response 함수에 docs를 추가해서 실행한다
# 사용자 입력 처리
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
st.session_state.messages.append(HumanMessage(content = prompt))
print("user\t : ", prompt)
augmented_query = retriever.query_augmentation_chain.invoke({
"messages" : st.session_state["messages"],
"query" : prompt,
})
print("augmented_query\t : ", augmented_query)
# 관련 문서 검색
docs = retriever.retriever.invoke(f"{prompt}\n{augmented_query}")
for d in docs:
print('------------------------')
print(d)
print("=========================")
with st.spinner(f"AI가 답변을 준비 중입니다... '{augmented_query}'"):
response = get_ai_response(st.session_state["messages"], docs)
result = st.chat_message("assistant").write_stream(response) # AI 메세지 출력
st.session_state["messages"].append(AIMessage(result)) # AI 메세지 저장이렇게 코드를 수정하고 스트림릿을 실행하면 문서에서 리트리버로 검색한 내용을 바탕으로 구체적인 답변을 해준다
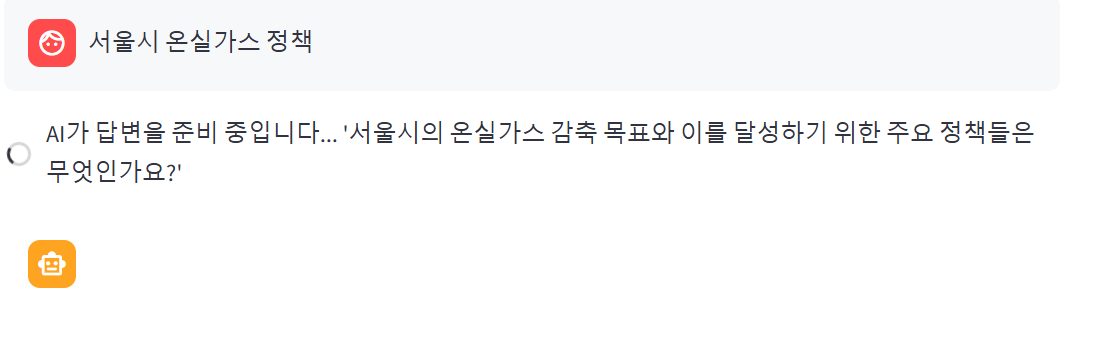

터미널을 확인해보니 실제 문서를 기반으로 답변을 찾고 있는것도 볼 수 있다

이전보다 확실히 답변의 퀄리티가 차이 나지 않는가!!!
2. 출처 표기하기
RAG를 사용할 때 언어 모델의 답변이 실제 문서에 근거한 것인지 아니면 엉뚱한 문서를 참고하거나
언어 모델이 임의로 생성한 답변인지 확인해야 할 때가 있다
이제 답변에 사용한 문서의 출처가 스트림릿에 표시되도록 해보자
기존에 get_docs 함수로 가져온 청크들을 print로 터미널 창에 출력하게 되어있는데
이를 스트림릿에서도 표시할 수 있도록 수정해보자
# 관련 문서 검색
docs = retriever.retriever.invoke(f"{prompt}\n{augmented_query}")
for d in docs:
print('------------------------')
print(d)
with st.expander(f"**문서 : ** {d.metadata.get('source', '알수없음')} "):
# 파일명과 페이지 정보 표시
st.write(f"**page : ** {d.metadata.get('page', '')}")
st.write(d.page_content)
print("=========================")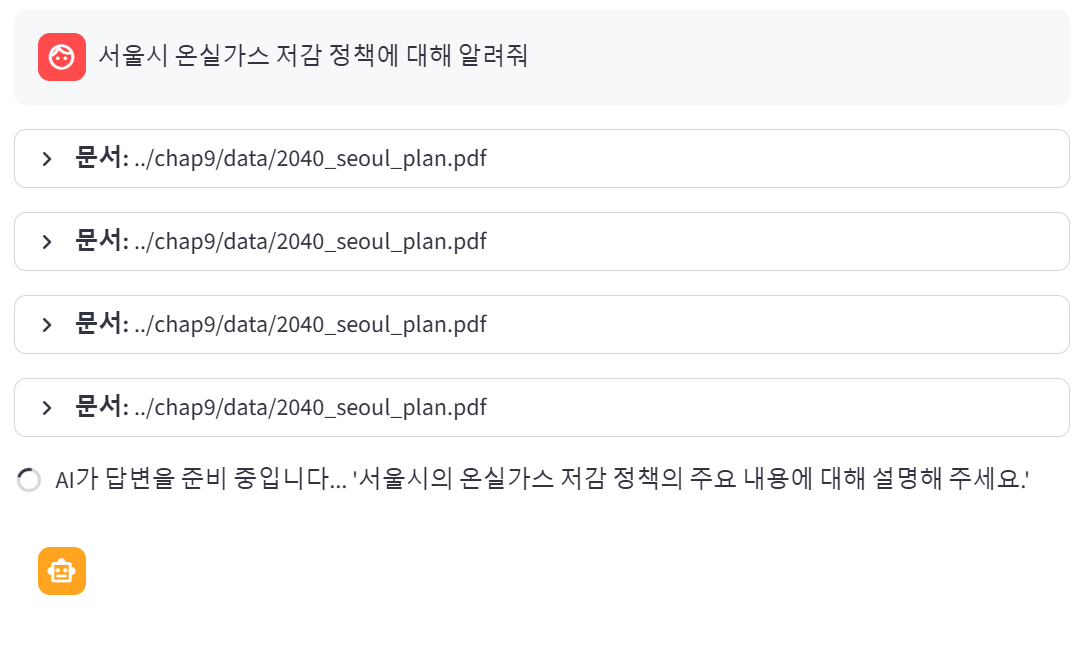
이전과 달리 확장할 수 있도록 답변이 생성되기 전에 사용한 청크들을 드롭다운 형태로 보여준다
버튼을 클릭하면 구체적으로 몇페이지를 기반으로 답변이 생성되었는지 확인할 수 있다

3. 마무리
이번에 스트림릿으로 옮기는 과정은 생각보다 불편하지 않았다!!
기존에 코드들을 많이 재활용해서인것 같다
지금까지 RAG를 이용해서 답변을 생성해봤는데 생각보다 퀄리티가 좋고 신뢰도가 가는 답변들이 많았다
다만 이 기술의 단점은.... 문서를 모아야 한다는 점이 아닐까 싶다
확실히 특정 목적이 있는 경우에 사용하기에 매우 좋은 기술인것 같다
그리고 해당 분야에 대해서 문서를 얻기 쉬운 경우에 지금까지 만든 코드를 이용하면 쉽게 응용할 수 있지 않을까!!
이번 챕터는 여기까지이다!
다음 챕터에서는 인터넷 검색을 활용해 답변하는 챗봇을 만드는 실습을 하려 한다
