이번주차에는 내년 1월에 있을 2주간의 Product Serving 강의의 맛보기로 AI 서비스 개발 기초에 대해 배우게 됐다. 이전까지의 학습정리와는 달리 하루에 하나씩 글을 작성할 계획이며, 정보 전달 보다는 개인 복습에 초점을 두려고 한다.
1강 강의소개
목표하는 인재
- AI 엔지니어로 출발하기 위한 시작점을 그릴 수 있는 큰 그림을 인지하는 사람
- 직접 문제 정의, 필요한 도구를 찾아보는 능동적인 자세를 가지는 사람
- 지속적으로 개선하는 사람
- 프로토타이핑부터 모델 배포, 모니터링 과정을 이해하는 사람
문제 해결을 위해 “왜?”를 습관적으로 물어보며 답을 하나씩 찾아갔으면 좋겠다.
ex) 왜 강사님이 이렇게 생각을 하고 가르치셨을까?
배우는 라이브러리에 종속되지 않고 왜 만들어졌는지 집중하기
강의에서 다루는 방법이 진리는 아니다 (더 나은 방법을 고려하는 것은 언제나 옳다)
Special Mission
신입 입장에서 이 정도를 경험해보면 좋겠다 싶어서 만든 Mission
무조건 경험해보기
프로젝트에도 도움이 되는 내용 위주의 Mission들이 존재
정답을 제공하지 않고, 왜 그럴까? 등의 자유로운 사고를 추구
캠퍼분들끼리 적극적으로 답안 공유 및 토론
추천하는 학습 방식
강의를 흐름 위주로 키워드를 필기하면서 1회 수강하고, 지속적으로 반추하기
1) 강의의 전체 흐름 기억, 학습 내용이 MLOps에서 어떻게 활용될지 고민해보기
2) 외우지 말고 스토리와 기술들이 나온 배경을 이해하며 “왜 그럴까?” 생각하기
3) 추가 자료 스스로 찾아보면서 공부하기
복습할 때는 강의자료 최대한 활용하기 : 강의자료를 그만큼 세세히 작성하였다
나중에 회사에서도 잘 활용하길 바라는 마음에서 만들었다.
오픈소스코드 분석하기도 추천!
강의 내용을 자신의 언어로 정리하기
자유롭게 캠퍼들과 공유하기
수평학습 → 수직학습이 효과적이라고 생각한다.
수평학습으로 큰 그림을 보고, 꾸준하게 수직학습하여 무기를 뾰족하게 갈고 닦자
2강 MLOps 개론
MLOps의 다양한 components를 이해하고 각 단계가 왜 생겼는지 이해해보자
Research
예측하고 모델을 개발하는 과정은 흥미롭다!
문제 정의 - EDA - Feature Enginerring - Train - Predict
위 프로세스는 컴퓨터나 서버 인스턴스에서 실행하며, 고정된 데이터를 사용하여 모델 학습 시킨다.
그렇게 학습된 모델을 앱,웹 서비스에서 사용할 수 있게 실제 세상에 배포 → Real world에 배포한다.
Production
문제 정의 - EDA - Feature Enginerring - Train - Predict - Deploy
모델에게 데이터를 먹여주면, 결과물을 출력해달라고 요구하는 것과 같다.
만약 이 단계에서 모델의 결과값이 이상하다면? 어떻게 해야할까
→ 원인 파악
→ Input data가 이상한 경우 : type이나 range가 안 맞는다면…
→ Research 단계에서는 제외하고 학습하겠지만, 현실세계에서는 반영해야할 수 도 있다.
→ ex) 모델의 조건에 맞지 않는 부적합 사용자라고 해서 그 사용자를 밴할 수는 없지 않은가
모델이 잘 배포되었다면, 성능을 모니터링 해야한다.
모델의 성능은 온라인 데이터에 의해 자주 바뀔것이다.
→ 성능을 어떻게 확인할 수 있을까? (wandb와 같은 모니터링?)
→ 예측값과 실제값을 알아야 성능도 계산이 가능한데, 비정형 데이터의 경우 정확히 알 수 있을까?
새로운 모델을 개발했는데, 이전 모델보다 성능이 안좋다면?
→ 과거 모델을 다시 사용할 수도 있다. (버전관리를 통해 롤백?)
→ 학습과정과 실제 배포과정에서 사용하는 데이터가 다르다보니 성능이 오히려 하락할 수도 있다.
머신러닝 코드를 짜는 일은 실제 머신러닝 시스템 중 아주 일부에 불과한다!!
환경 설정, 데이터 수집, 데이터 전처리, 모니터링, 모델 서빙 인프라등등 ..
이 과정에서 생기는 많은 업무들을 자동화 한 것이 MLOps
머신러닝 엔지니어링 + 데이터 엔지니어링 + 클라우드 + 인프라
모델링에 집중할 수 있도록 자동화 된 하나의 큰 공장을 만들어 내는 것이 MLOps
최근 비즈니스에서는 ML/DL을 이용한 업무들이 많아지다보니, 자연스레 더 좋은 효율을 위한(자동화와 같은) 시스템들이 생겨나기 시작했고, 그렇기에 MLOps가 탄생한 것 같다.
또한 Research 단계의 모델을 Production 환경에 배포하는 과정에서 모델의 재현율을 높이고, 가능한 실제의 리스크를 포함할 수 있어야 한다. 즉, 아이디어 구상 단계, 문제 정의 단계부터 Production 단계까지 ML 프로젝트를 최대한 적은 리스크로 진행할 수 있게끔 기술적인 마찰을 줄이는 것이 MLOps의 목표이다.
Research vs Production
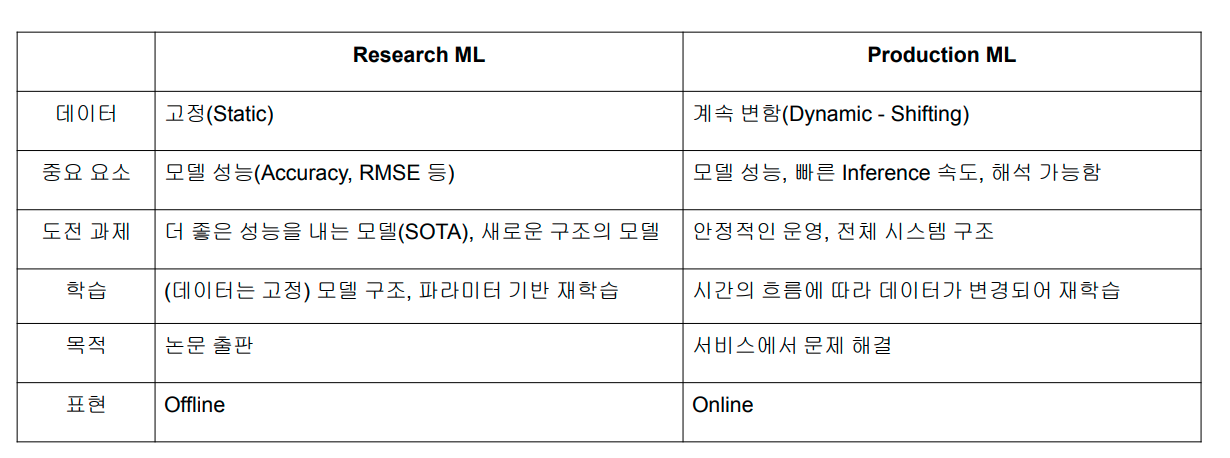
- 고정된 데이터이냐, 실시간으로 반영되어 바뀌는 데이터이냐
- 고성능의 모델이냐, 실시간 대처 가능한 안정적인 모델이냐
- 이론적이냐 실전적이냐
정도의 차이라고 볼 수 있을 것 같다.
요즘MLOps는 춘추전국시대로 할 수 있을만큼 정형화된 라이브러리가 있지는 않고 그렇기 때문에 문제를 어떻게 해결하려고 하는지에 대해 중점을 두고 공부를 하면 좋을 것 같다.
MLOps 학습 방법
각 Component는 왜 생겨났는지 이해하고 어떤 문제를 풀기 위함이며 문제를 해결하기 위한 방법으로는 어떤 방식을 활용하는지에 대해 학습하는 것을 추천한다. (어차피 라이브러리는 계속 나올 것이고, 바뀔 것이기 때문에 특정 라이브러리를 익히기 보다는 개념에 대해 확실히 이해하는 것이 변화하는 시장을 따라가기 좋을 것이다)
MLOps Component
어떤 요리를 예로 들어보자.
내가 만든 요리가 너무 맛있어서 사람들에게 알리고 싶고 어떻게 하면 좋을지 고민하다가 가게를 차리기로 했다.
집 : Research, 가게 : Production
-
초기단계에서는 집에서 사용하던 재료를 이용하거나, 전문 회사에서 납품을 받는다.
-
집에서는 그냥 내가 만들어 먹으면 됐는데, 가게에서는 팔아야하기 때문에 장사 하기 적합한 장소를 조사하고 선정한다.
1) 유동인구가 괜찮은가? (=트래픽이 어느정도 될까?)
2) 가게의 크기는 어느정도로 할 것인가(주방, 홀,..) (=서버의 CPU, Memory성능은 어느정도?)
3) 점포 확장이 가능할까? (=스케일 업, 스케일 아웃이 가능할까?)
4) 가게를 위한 건물을 사는게 나을까? 월세로 들어가는게 나을까? (=자체 서버를 구축한다 vs 클라우드 서비스를 이용한다)
참고로, 금융권과 같은 경우는 규정때문에 클라우드 서비스를 활용하지 못한다. 이외의 대부분은 클라우드 서비스를 이용한다. -
요리 도구들은 어떻게 할까?
집에서는 내 도구를 사용하면 되는데 (로컬 GPU, Colab) 가게를 차리면 요리 도구들을 임대해서 사용할 수도 있다. (AWS, GCP, Azure, NCP …) -
요리를 만들었다면 손님에게 제공해야한다 (서빙)
1) 일정 주기 별로 미리 음식을 만들거나, 일정 양의 음식을 미리 만들어서 한번에 제공 : Batch Serving
(Jupyter Notebook에서 흔히 해왔던 과정들, 즉 여러 데이터가 합쳐진 df를 통해 예측을 제공하는 것)
2) 주문 받자마자 실시간으로 제공 (Online Serving)
동시에 여러 주문이 들어와도 병목이 없어야 하고 확장 가능해야 한다. -
신메뉴를 개발하고 싶다거나, 정말 맛있는 요리를 계속해서 먹고 싶을 때는 레시피를 기록해야 한다.
1) 하이퍼파라미터 혹은 모델 구조등을 이용해서 베스트 조합을 찾는 실험을 반복한다.
2) 성능이 좋았던 모델들을 Production 단계로 전달한다.
3) 모델 Artifact, 이미지(Fearture Importance)등 부산물도 저장한다.
4) 어떤 버전의 모델이고, 성능은 어느정도이고, 사용 데이터나 모델의 메타 정보를 기록해둔다.
(참고) 협업하거나 실험 할 때, MLflow와 같은 라이브러리를 이용하면 학습 파라미터와 loss, metric 등을 효율적으로 기록할 수 있다. -
요리별로 사용되는 중복되는 재료들 혹은 양념들은 미리 만들면 편하다.
머신러닝 Feature를 집계한 Feature Store는 공통된 재료를 가공해서 냉장고에 미리 넣어놓는 과정과 같다.
전처리 과정을 줄이고 바로 모델링에 들어갈 수 있다.
(이 부분은 Tabular data, 즉 정형 데이터의 경우는 수월하지만, 딥러닝등에 많이 사용되는 이미지, 텍스트 데이터와 같은 비정형 데이터에서는 아직..) -
가게의 환경을 집에서 만들 때와 완벽하게 같도록 구축하면, 가게를 이전할 때도 좋고 Batch, Online serving간 좋은 효과를 보일 수도 있다. (동일한 Feature Store)
-
집에서의 재료와 가게에서의 재료의 신선도, 품질등을 잘 체크 해야 한다.
Research 환경과 Production 환경의 Data, Feature 분포들을 체크해야 한다.Data Drift, Model Drift, Concept Drift

Tensorflow Data Validation을 이용한 Data, Featuer 분포 체크
-
새로운 음식을 만들어야 할 때는 언제인가?
1) 사람들이 갑자기 싫어해서 매출이 줄어들 때 (Online data들이 들어옴에 따라 기존 model의 metric이 떨어질 때)
2) 신선한 재료가 공급이 되었을 때 (새로운 데이터가 들어올 때)
3) 고객이 요청할 때
4) 일정 주기마다 -
매출, 손님 수, 대기열 등을 파악해서 기록해둬야 한다. (추가적인 인사이트를 얻기 위해서)
트래픽이 언제 많이 발생하는지, 사용자가 어느정도 인지.. -
밀키트를 만들거나 에어프라이어를 이용한 조리법을 통해 사용자 혹은 가맹점에게 제공할 수도 있다.
AutoML
앞으로 MLOps는 꾸준히 발전해 나갈 것이고, 더 효율적으로 발전하기 위해 어떤 방법을 이용하면 좋을지 등등 생각해보자!
ex) 밀키트 : Pre-trained model
모든 업무를 처음부터 MLOps component에 빗대어 준비하기 보다는, 처음엔 *MVP(Minimal Value Product)에서 시작하여 점점 운영 리소스가 많이 소요될 때 하나씩 구축하는 방식을 활용하는 것이 효율적일 수도 있다.
Special Mission
1. MLOps가 필요한 이유 이해하기
2. MLOps의 각 Component에 대해 이해하기(왜 이런 Component가 생겼는가?)
3. MLOps 관련된 자료, 논문 읽어보며 강의 내용 외에 어떤 부분이 있는지 파악해보기
4. MLOps Component 중 내가 매력적으로 생각하는 TOP3을 정해보고 왜 그렇게 생각했는지 작성해보기
3강 Model Serving
1. Model Serving
Serving 이란?
Production 환경에 모델을 배포하는 것
머신러닝 모델을 개발해서, 실제 사람들이 사용할 수 있게 앱,웹 서비스로 뿌리는 것
Input이 주어지면 Output을 반환한다.
용어 정리
Serving : 모델을 앱/웹 서비스에 배포하는 과정, 모델을 활용하는 방식, 모델을 서비스화 하는 관점
Inference : 모델에 데이터가 제공되어 예측하는 경우, 사용하는 관점
Online Serving 과 Online Inference는 구분되는 경향
Batch Serving안에 Inference 개념이 포함되기도 한다
2. Online Serving
- Web Server Basic
웹 서버는 쉽게 설명하자면, 가게에서 손님에게 음식을 직접적으로 제공하는 서버(종업원) 역할
ex) 손님(Client)이 종업원(Server)에게 음식을 주문(Request), 종업원이 손님에게 음식을 반환(Response)
즉, 웹 서버는 Client의 다양한 요청을 처리해주는 역할을 한다.
그럼 머신러닝 서버는? 데이터 전처리, 모델을 기반으로 예측하는 등의 요청을 처리해주는 역할을 한다.
웹 서버의 개념에 머신러닝 서버가 포함되는 느낌
ex) 고객이 쇼핑몰에게 회원가입 요쳥을 하면(Request), 서버는 검사를 하고 확인을 해준다(Response)
- API
운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
쉽게 말하면 TV의 리모컨은 사용자와 TV를 연결 시켜주는 소통 창구 역할을 할 수 있고, 이것또한 API 예시이다
특정 서비스에서 기능을 사용할 수 있게끔 외부로 노출해주는 것 : 기상청 API, 구글맵 API …
라이브러리의 함수 : Pandas, Tensorflow, PyTorch 공식문서 Documents에서 확인 가능
자세한 내용은 FastAPI 강의에서..
- Online Serving Basic
요청이 오면 바로 실시간 예측을 해주는 것
단일 데이터 실시간 예측 예제
건물 입구에서 사람의 발열을 체크해 안전한지 아닌지 확인해주는 센서,
해당지역의 과거 평균 배달 시간, 실시간 교통 정보, 음식 데이터등을 기반으로 음식 배달 시간을 예측해주는 어플
ML 모델 서버 / 전처리 서버 분리도 가능, ML 서버를 서비스 서버에 포함 시킬수도 있고 아닐 수도 있고 ..
Online Serving을 구현하려면?
1) Flask, FastAPI등을 이용해 직접 API 웹 서버를 개발하는 것.
- 서버 자체 개념에 대한 이해가 충분하지 않다면 어려울 수도 있다.
2) AWS의 SageMaker, GCP의 Vertex AI 등을 활용해 클라우드 서비스를 활용하는 것.
- 비용이 조금 들 수도 있고, 익숙해야 사용할 수 있다는 단점도 있지만, 클라우드 서비스에선 어떤 방식으로 AI 제품을 만들었는지 확인할 수 있다는 장점도 있다.
3) Tensorflow Serving, Torch Serve, MLFlow, BentoML등의 라이브러리를 활용하는 것
- 비교적 사용하기 쉽다는 장점이 있다. 서버를 만들기 위한 추상화된 패턴을 잘 제공해주기 때문에 이해하기 쉽다
왜 이번 강의에서는 Serving 라이브러리를 학습하지 않을까?
- 사용하기엔 편하지만, 툴이나 라이브러리 자체를 학습하는 것이 아닌 점진적인 문제 해결을 추구
- 여러가지 방법중 왜 이 방법인가? 에 대한 인식을 키워주고 싶어서
- 오픈소스는 계속 좋은 발전이 이루어지고 있다 (=하나의 라이브러리에 종속되지 않기)
- High level 보단 Low level 먼저
- 서버 프로그래밍은 필수적이기 때문에 먼저 해보고 그 다음 라이브러리 활용
Online Serving 에서 고려할 부분!
Serving 할 때 Python 버전, 패키지 버전 등의 Dependency가 굉장히 중요하다
또한 직접 서비스를 제공하기 때문에 반드시 재현 가능해야 한다.
관련 작업을 할 수 있는 Virtualenv, Poetry, Docker도 학습할 예정이다.
Latency를 최소화 해야한다. (loading 시간을 줄여야 하는 것과 유사)
1) Input data 기반으로 DB에 있는 data를 추출하여 모델에 넣어 예측 하는 경우
→ 데이터를 추출하기 위한 쿼리를 실행, 그 결과를 받고 모델에 넣기 때문에 latency가 길다
2) 모델이 수행하는 연산
RNN, LSTM 등의 모델은 연산 시간이 오래걸린다. 따라서 모델의 경량화는 어느정도 필요하며 복잡한 성능이 좋은 모델보다 성능은 조금 손해보더라도 간단한 모델을 사용하는 경우도 있다. (딥러닝 모델인 ANN에서 시간을 대폭 감소시키면서 성능은 그에 비해 약간만 저하되는 trade-off를 선택하는 예시)
3) 결과 값에 대한 보정
양수의 값만 예측해야 하는데 음수의 값이 나오는 경우등을 처리하기 위한 코드
이상치를 방지하기 위한 단계가 필요하다 (실제 사용자들에게 제공하기 때문에)
3. Batch Serving
항상 모든 경우에서 Online Serving이 Batch Serving보다 좋지는 않다. (Batch Serving도 좋다)
Workflow Scheduler 등을 이용해서 특정 단위(1시간, 하루) 마다 실행해서 다량의 Input을 이용해 다량의 Output을 만들어 낸다.
Batch 단위로 묶어서 최신 데이터를 이용해 학습을 하기도 한다.
Batch Serving 관련한 라이브러리는 딱히 없고, Airflow, Cron Job 등으로 스케쥴링 작업을 할 수 있다.
학습과 예측을 별도로 설정하기도 한다. (주로 실제로 그럴 것 같다)
학습 : 1주일에 1번
예측 : 10분, 30분, 1시간에 한 번 등등
실시간이 필요없는 대부분의 방식에서 활용하면 좋다.
장점으로는 Online Serving 보다 훨씬 수월하고 (main.py 파일등을 반복적으로 돌려주기만 하면 되니까) Latency 문제가 없다 (한 번에 다량의 예측량을 던져주는 것이기 때문에)
단점으로는 Cold Start 문제가 있다. (실시간 데이터를 반영하지 못하기 때문에 생기는 현상이기도 하다)
스포티파이의 추천 알고리즘 (Discover Weekly)
Batch단위(1주일)로 학습 후 예측하여 추천곡을 제공 : 꼭 실시간 만이 답은 아니다.
Online vs Batch
- Input data 관점
- 데이터를 하나씩 요청, 실시간 반영 - Online
- 데이터를 Batch로 요청, 실시간 요구 x - Batch
- Output data 관점
- API 형태로 바로 결과를 반환, 서버와 통신이 필요 - Online
- 1시간에 1번 예측해도 괜찮다 - Batch
처음부터 API 형태의 Online Serving을 만들어야 하는것은 아니다
실시간 모델 결과가 어떻게 활용되는지 고려해봐야 한다. 실시간으로 예측을 해주더라도 그 즉시 활용이 되지 않는다면 Batch로 진행해도 무방하다.
위 게시글의 내용은 Boostcamp AI Tech 4기 강의내용(변성윤 마스터님)을 참고하여 작성하였습니다.
