4강 머신러닝 프로젝트 라이프 사이클
변성윤 마스터님이 현업에서 머신러닝 프로젝트를 여러번 하며 경험하고 느낀 내용 토대로 설명
1. 머신러닝 프로젝트 Flow
0) 문제 정의의 중요성
프로젝트 외에도, 우리 인생에서 겪는 대부분의 일은 문제로 정의할 수 있다.
문제를 잘 해결하기 위해서는 그만큼 문제를 잘 정의 해야 한다.
ex) 나는 행복하게 살고 싶어
⇒ 행복의 정의는 금전적인 부인가? 감정적으로 내면의 평화를 말하는 것인가?
문제를 정의하는 단계는 대부분의 업무에서 가장 선행적으로 이루어져야 하고, 잘 해야한다.
How 보다는 Why
“문제 정의”에 대한 정의
- 본질을 파악하는 과정
- 해결해야 하는 문제는 무엇이고, 그 문제를 해결하면 얻는 이득, 해결 방식들을 정의 하는 것.
문제 해결 Flow
현상 파악 → 문제 정의 (쪼개서 생각하기) → 프로젝트 설계 → Action → 추가 원인 분석
1) 현상 파악
현재 어떤 일이 발생하고 있고, 문제가 되고 있는 상황은 무엇인가?
문제를 어떻게 해결해 볼 수 있을까? 어떤 가설이 도움이 될까?
어떤 데이터를 사용할 수 있을까?
ex) 내가 차린 음식점의 매출이 3달째 감소하고 있다.
2) 구체적인 문제 정의
무엇을 해결하고 싶고, 무엇을 알고 싶은가?
ex) 우리 음식점에 처음 방문하는 손님의 수가 급격히 줄어들고 있다.
음식점 홍보는 마케팅 팀에게 맡기고, 우리는 손님들한테서 정보를 얻어보자
손님들을 인터뷰한 결과, 메뉴가 너무 다양하고 설명이 부족하여 메뉴 선정에 어려움을 겪고 있고, 그렇기 때문에 음식에 대한 만족도가 당연히 낮아졌다.
” 메뉴가 너무 다양하고 설명이 부족해 메뉴 선정이 어렵다! ”
→ 메뉴가 다양하니 조금 줄여볼까? (궁극적인 해결 방법일까..? 언제까지나 적은 메뉴로 장사할 수는 없어!)
→ 설명이 부족하니 설명을 더 자세히 달아볼까? (당장 수정할 수 있고, 상황에 맞춰 음식 추천 가이드를 제공!)
우선은 당장 진행 가능한 설명을 늘리는 방식을 사용하고, 병렬적으로 손님의 취향과 상황에 맞게 음식을 추천해주는 방식을 구상해보자!
설명을 늘리는 방식 : 룰 베이스 (날씨가 이런 날에는 특정 음식을 추천) = 당장의 문제 해결 가능
추천 시스템 개발 : 알고리즘을 통해 문제를 해결할 수 있는 또 다른 방법
데이터로 할 수 있는 일을 만들어서 진행하되, 현실세계에서는 시간의 제약도 분명히 있기 때문에 무조건 알고리즘을 이용한 접근이 최상이 아니라는 생각도 갖고 있어야 한다! (간단한 방법부터 점진적인 접근이 필요하다)
인지하면 좋은 내용
- 문제를 쪼개서 파악해보자
- 문제의 해결 방식은 다양하다 (정답이 하나만은 아니다)
- 해결 방식 중에서 데이터를 이용할 수 있는 방법을 고민해보자
- 점진적으로 실행하자
3) 프로젝트 설계
문제 정의 → 최적화할 Metric 선택 → 데이터 수집, 라벨 확인(Metric에 맞는) → 모델 개발 → 모델 예측 결과를 토대로 Error Analysis (잘못되니 라벨이 왜 생기는지 확인) → 다시 모델 학습 → 더 많은 데이터 수집 → 다시 모델 학습 → 모델 배포 → Metric이 올바르지 않다면 Metric을 수정 → 다시 시작
많은 시행착오를 겪으면서 프로젝트가 완성되기 때문에, 문제 정의 만큼 프로젝트 설계도 최대한 구체적으로 하는 것이 좋다!
프로젝트 설계 단계
- 0) 문제 구체화 : 문제 정의 단계에서 어느정도 해결
- 1) 머신러닝,AI 문제 타당성 확인
- 2) 목표 설정, 지표 결정
- 3) 제약조건 점검, 파악
- 4) 베이스라인, 프로토타입
- 5) 평가 방법 설계
1) 머신러닝 문제 타당성 확인
머신러닝 문제를 고려할 때는 재미,흥미 위주가 아니라 비즈니스적인 가치가 있는지에 대해 고려한다!
결국 데이터가 중요하기 때문에 데이터 먼저 확인 하고, 비슷한 문제를 해결한 SOTA 모델이 있는지 확인
머신러닝이 마스터키는 아니기 때문에 간단한 해결방법도 있는지 확인 후 간단한 해결방법으로 머신러닝 프로젝트를 진행할 시간을 버는 방법도 유용하다
현업에서는 유연한 사고가 필요하다
"머신러닝이 사용되면 좋은 경우는 뭐가 있을까?"
1. 학습할 수 있는 패턴이 있는가?
예측값을 생성하는 방식에 패턴이 없다면 학습할 수가 없다.
예를들어 주식 가격이 완전히 무작위에 의해 정해진다고 가정하면 학습할 필요가 없는 것.
2. 목적함수를 만들 수 있는가?
정답 레이블과 예측결과의 차이 등을 이용하여 목적함수를 정의할 수 있는가에 집중한다.
3. 패턴이 어느정도의 복잡성을 갖고 있는가?
너무 단순하면 머신러닝이 필요하지 않고 룰 베이스, 단순한 방법론도 가능
4. 학습할만한 데이터가 존재하는가?
데이터 수집이 가능하거나, 이미 존재 하는가에 대한 여부도 확인해야 한다.
데이터가 없다면 룰베이스 알고리즘을 만든 후, 데이터 수집 계획부터 수립하는 것이 좋다.
5. 반복적인가?
작업의 반복성은 곧 패턴이 존재한다는 의미 패턴이 있으면 학습이 가능하다
사람의 노동을 기계의 노동으로 치환가능하다.
"그럼, 머신러닝이 사용되면 안 좋은 경우는 뭐가 있을까?"
비윤리적인 문제 (인종, 성 문제 등)
간단히 해결할 수 있는 문제
좋은 데이터를 얻기 어려운 경우
예측 오류가 치명적인 결과를 불러오는 경우 (금액 오류 등)
시스템의 결정이 설명 가능해야 하는 경우 (머신러닝도 설명이 가능하지만, 모든 결정에 대한 근거가 필요한 경우)
비용이 효율적이지 않은 경우 (리소스 대비 성능 개선 정도 등)
2) 프로젝트의 목표,지표 설정
Goal : 프로젝트의 큰 목적
Objectives : 목적을 달성하기 위한 세부 단계의 목표
ex)
Goal : 랭킹 시스템에서 고객의 참여(Engage)를 최대화 하고 싶다. (잘못된 정보의 확산을 최소화 하며)
Objectives
1) NSFW(Not Safe For Work) 컨텐츠 필터링을 통해 사용자의 불쾌감을 줄인다.
2) 사용자가 클릭할 가능성이 있는 게시물을 추천하여 만족감을 높인다.
3) 잘못된 정보를 필터링 (건전한 뉴스피드를 위해)
4) 좋은 품질인 게시물을 추천 (건전한 뉴스피드를 위해)
Netflix 소셜 딜레마
극단적으로 클릭을 유도하기 위해 자극적인 컨텐츠만을 노출시킬 수도 있다는 윤리적인 문제도 존재.
또한 목표 설정 단계에서 지표도 설정하여 데이터를 확인해야한다.
ex) 부정거래 탐지를 위해 부정거래자의 라벨링을 어떻게 할 것인가?
유사 라벨링을 통해 학습을 위한 라벨링 방법도 있다.
ex) 음악 스트리밍 서비스에서 그 음악을 일정시간 이상 들었으면 선호, 건너뛰기 했다면 비선호
ex) Self Supervised Learning
Multiple Objective Optimization
앙상블 기법, 여러개의 loss에 가중치를 둬서 결합 등 방법론 생각
모델을 재학습하지 않도록 분리하는 것이 좋다.
3) 제약 조건 고려
일정 : 프로젝트 완성까지 사용할 수 있는 시간
예산 : 사용할 수 있는 최대 예산 고려 (Data 확보 vs Model 학습을 위한 resource)
개인정보 보호 : 개발한 서비스의 사용자의 개인정보를 보호해줘야 한다. (법률 준수)
기술적인 제약 : 기존에 운영하고 있던 개발 환경과의 의존성
윤리적인 이슈
성능적인 측면
- Baseline : 새로 만든 모델과 비교할 기존의 방법 (사람이 작업할 때와 비교 or 간단한 회귀,예측 모델과의 비교)
- Threshold : 분류 모델에서 확률값이 0.5 이상일 경우를 강아지라고 할 것이냐, 0.7 이상일 경우를 강아지라고 할 것 이냐
- Performance Trade-off : 속도가 빠르지만 Acc 0.93 vs 속도가 조금 더 느리지만 Acc 0.95
- 해석 가능 여부 : 결과 예측에 해석이 필요할까? vs 해석이 필요한 경우는 어떤 경우일까? (머신러닝을 모르는 사람에게는 어떻게 설명할 것인가)
- Confidence Measurement : False Negative가 있어도 괜찮은가? 오탐이 있으면 안되는가?
4) 베이스라인, 프로토타입
-
베이스라인
모델의 성능을 판단하기 위해 허수아비 모델을 하나 선정해야 한다.
꼭 모델이 아니어도 가능하며, 사람이 판단하거나 룰 베이스 모델을 선정할 수도 있다.
ex) book rating prediction 문제에서, 표본 평균 평점을 모든 데이터에 대한 예측치로 했을 때, rmse가 어느정도인지 기준점을 잡아놓는다.
우리와 비슷한 문제를 해결한 SOTA 논문에서는 어떤식으로 베이스라인을 잡는지 참고해도 좋은 방식이다. -
프로토타입
베이스라인 이후에 간단한 모델을 만들어 피드백을 들어보면 좋다
회사의 동료들에게 모델을 체험할 수 있는 환경을 준비
프로토타입을 만들어서 제공
ex) Volia, Streamlit, Gradio (좋은 디자인을 가지기 보다는, 모델이 잘 동작하는지 확인)
5) 평가 방법 설계
모델의 성능 지표와 별개로 비즈니스 목표에 영향을 파악하는 것도 중요하다
ex) 모델의 성능 지표 : RMSE, 비즈니스 지표 : 매출,고객의 재방문율 …
지표를 정의하고 A/B Test를 통해 우리의 Action이 기존보다 더 성과를 냈는지 아닌지를 파악할 수 있음
내가 만든 모델이나 프로그램이 비즈니스적인 측면에 어떤 임팩트를 주었는지 고려하는 사람이 되면 좋겠다.
대부분의 기업은 이익의 증가, 극대화를 목표로 한다. (쉽게 말해 돈이 되는가?)
내부 : 직원의 리소스 효율 극대화로 인한 비용 절감
외부 : 고객의 만족도를 높여 매출을 증가
4) Action
모델 개발 후 배포 & 모니터링 단계
에러 분석을 하면서 지표의 변화에 집중을 한다.
5) 추가 원인 분석
새롭게 발견한 상황을 토대로 어떤 Action을 취할 것인지 결정
특정 단계에서 문제점을 보완하여 프로젝트를 재실행 할 수도 있고, 일정 시간을 두고 다시 프로젝트를 진행 할 수도 있고
2. 비즈니스 모델
회사에서 실제 업무할 때 중요한 것은 비즈니스 모델(매출이 발생하는 진원지)을 잘 파악하는 것
비즈니스에 대한 이해도가 높으면 문제 정의를 잘 할 수 있다.
해당 비즈니스 모델에서 어떤 데이터가 존재하고, 그 데이터를 기반으로 어떤 것을 만들 수 있을지 생각
1) 회사의 비즈니스 파악하기
회사가 어떤 서비스, 가치를 제공하고 있는가?
2) (Input) 데이터를 활용할 수 있는 부분은 어디인가?
어떤 데이터가 존재하는가? (센서, 이미지, NLP …)
데이터로 무엇을 할 수 있을까?
데이터가 신뢰할만한가? 정합성은 맞는가? 라벨링이 잘 되어있는가? 꾸준히 받을 수 있는가?
무엇을 해볼 수 있을까?
왜 해야 할까?
3) (Output) 모델을 활용한다고 하면 예측의 결과가 어떻게 활용되는가?
고객에게 바로 노출 가능한가? (스노우 카메라 필터)
내부 인원의 노동을 간소화 할 수 있는가?
Special Mission
- 부스트캠프 AI Tech 혹은 개인 프로젝트를 앞선 방식으로 정리해보기
- 실제로 회사에서 한 일이 아니더라도, 특정 회사에서 활용했다고 가정하거나 아예 크게 문제 정의해서 구체화해보기
- 이 모델이 회사에서 활용되었다면 어떤 임팩트를 낼 수 있었을까? 고민해서 정리해보기!
- 직접 일상의 문제라도 하나씩 정의하기
5강 Voila를 이용한 프로토타입
실습 코드 작성하며 정리
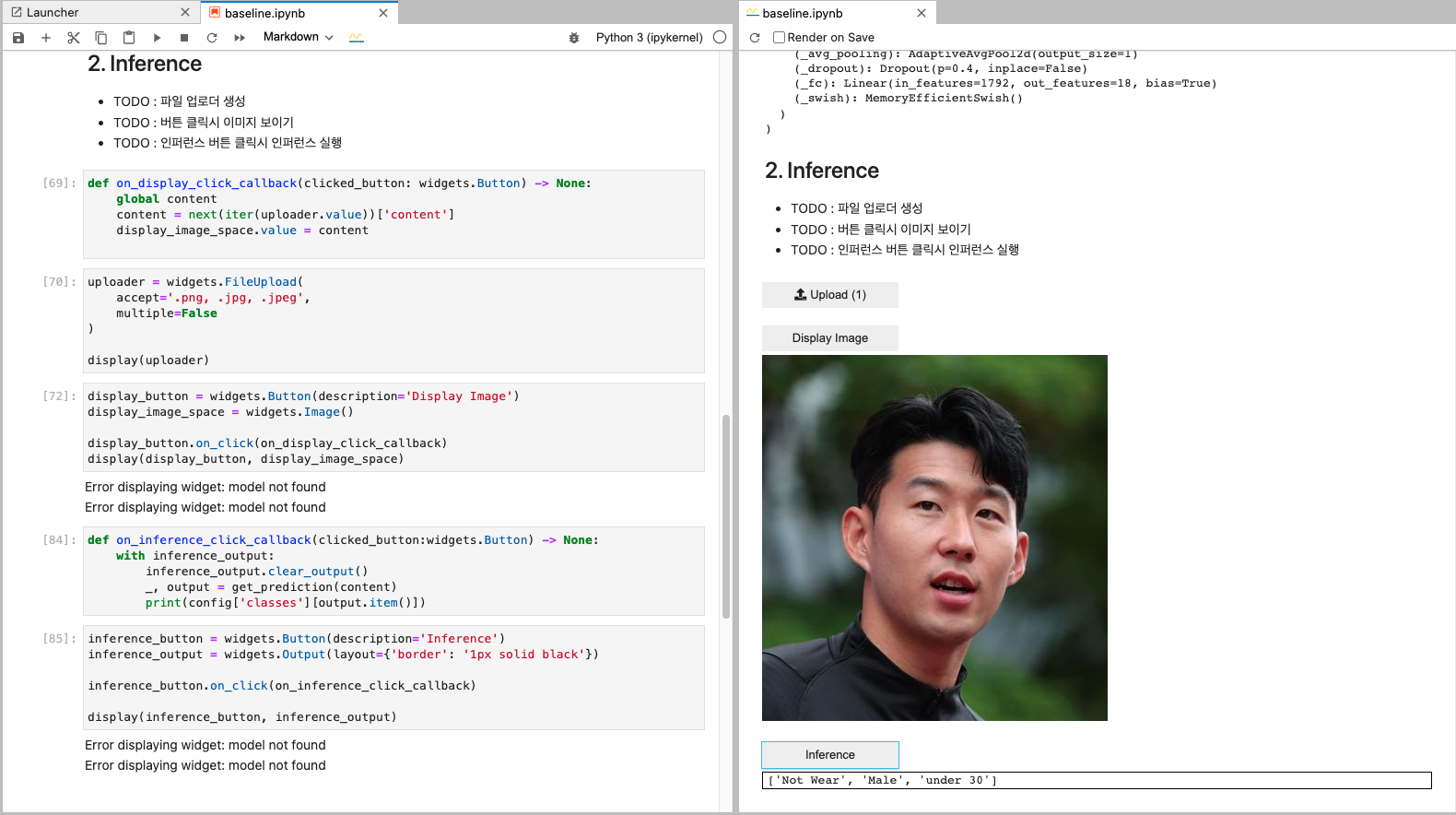
손흥민 선수 사진을 이용한 실습 예시 (마스크 썼는지 안썼는지 분류, 성별, 연령대 예측)
위 게시글의 내용은 Boostcamp AI Tech 4기 강의내용(변성윤 마스터님)을 참고하여 작성하였습니다.
