1주차의 AI/Math에서의 CNN, RNN에 대한 강의와, 3주차의 DL Basic 강의중 CNN, RNN에 대한 강의를 듣고 이해한 내용을 정리하며 복습해보자
CNN
CNN 맛보기 (1주차)
-
fully connected layer와의 차이점
- FC layer는 입력 데이터에 따른 제각각의 가중치 행을 이용해 행렬 곱 연산(내적)
- CNN은 고정된 kernel을 이용해 스캔해가며 연산 (마찬가지로 선형 연산)
-
Input / Output
-
입력 데이터의 채널수와, kernel의 채널수는 같게 한다.
-
각 채널에서의 convolution 연산 결과를 더한 1개의 채널을 output 데이터로 출력한다.
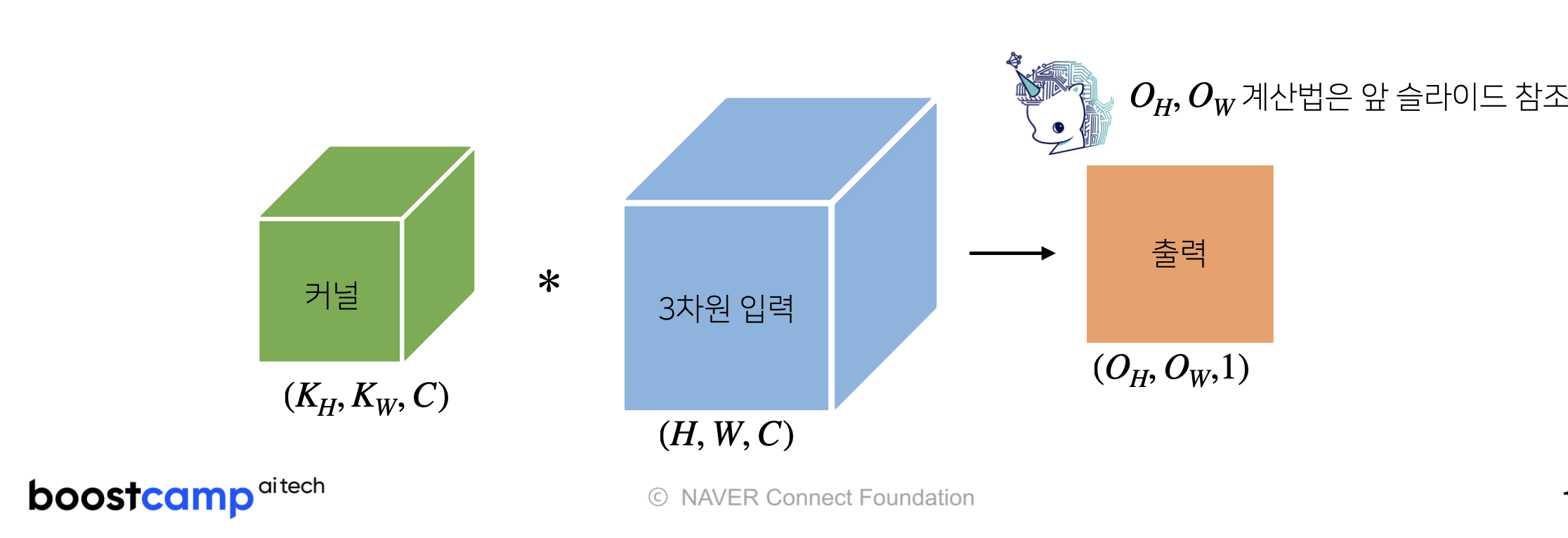
-
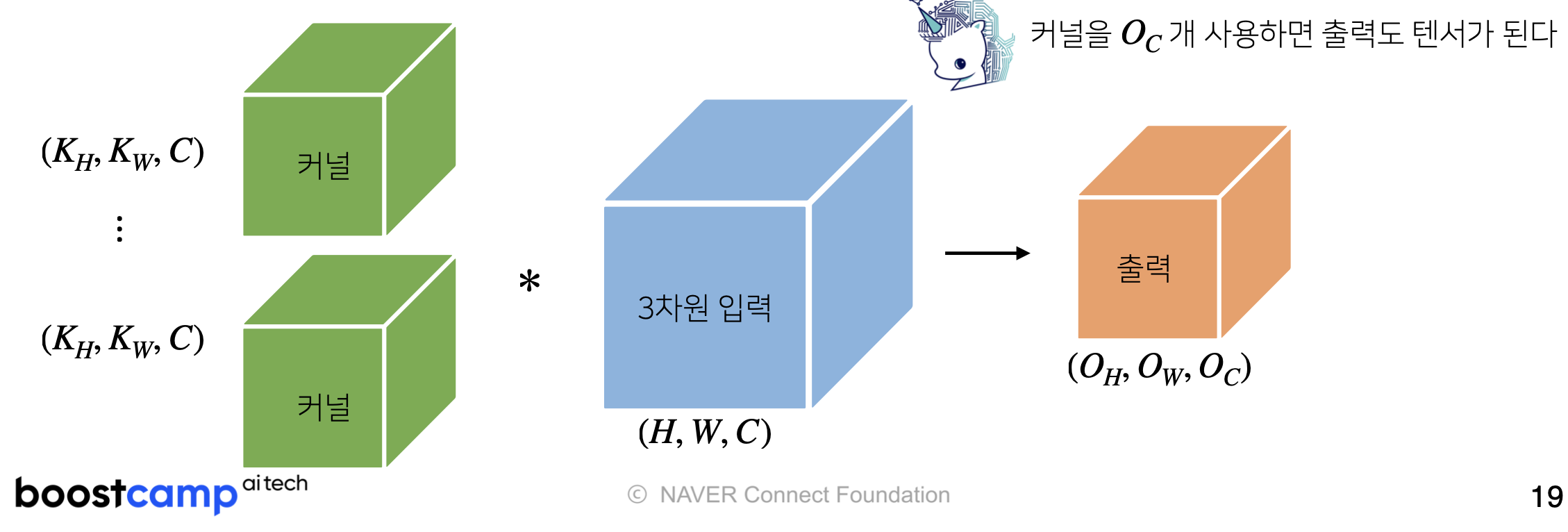
만약 여러개 채널의 output을 원한다면, kernel의 개수를 원하는 개수만큼 사용한다.
-
DL Basic - CNN (3주차)
4강 CNN
Convolution and Pooling layer를 이용하고, 최대한 Fully connected layer의 개수를 줄이면서 전체 Parameters 숫자를 줄여서 학습을 유용하게 하고, train test dataset 간의 성능차이를 줄이는데에 기여한다.
Number of Parameters
- input channel(i_c)과 output channel(o_c)을 우선 고려
- kernel size(k) 고려, (행렬이 같은 사이즈라고 가정)
- Number of Parameters = k k i_c * o_c
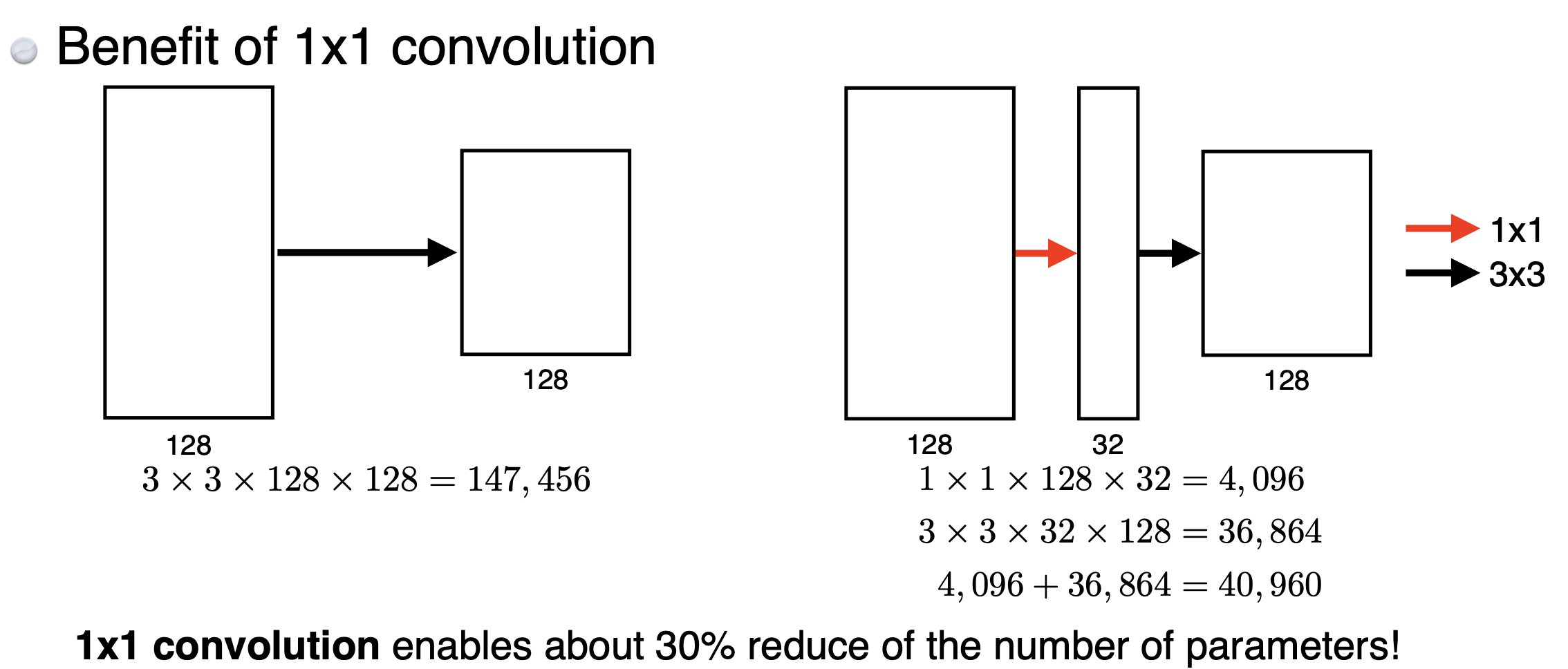
1x1 Convolution
- 256x256x128 ⇒ 1x1 Convolution ⇒ 256x256x32
- Dimension reduction을 하기 위해 수행(Parameters 수를 줄이고, 네트워크를 깊게 쌓기 위해서)
- bottleneck architecture에서 사용한다 (여러 모델에서 많이 사용하는 테크닉)
4강 CNN 실습
y_numpy = y_torch.detach().cpu().numpy()
# torch tensor to numpy array : KEY POINT!!! 이 부분이 numpy와 호환을 가능하게 해줘서 pytorch가 편하게 느껴진다!!!5강 Modern Convolution Neural Networks
1. AlexNet (2012)
부족한 GPU성능 때문에, 2개의 네트워크로 나누어 분할 학습
11x11 size의 kernel을 사용해서 5개의 convolution networks, 3개의 dense layers 사용
큰 사이즈의 커널 때문에 파라미터 개수가 많았다.
ReLU 활성화 함수를 사용 (vanishing gradient problem을 극복했다)
Data augmentaion 사용
Dropout 사용
지금 보면 당연한 수순과 당연한 학습 과정이지만, 이 때 당시에는 혁신이었다
2. VGGNet
3x3 kernel을 이용해서 깊은 layers를 쌓을 수 있었다.
작은 사이즈의 커널 덕분에 깊은 layer를 쌓으면서도 # of params을 줄일 수 있었다.
3. GoogLeNet
1x1 convolution을 잘 활용해서 전체의 # of params를 줄이는 아이디어
Inception Block을 활용 (1x1 convolution)
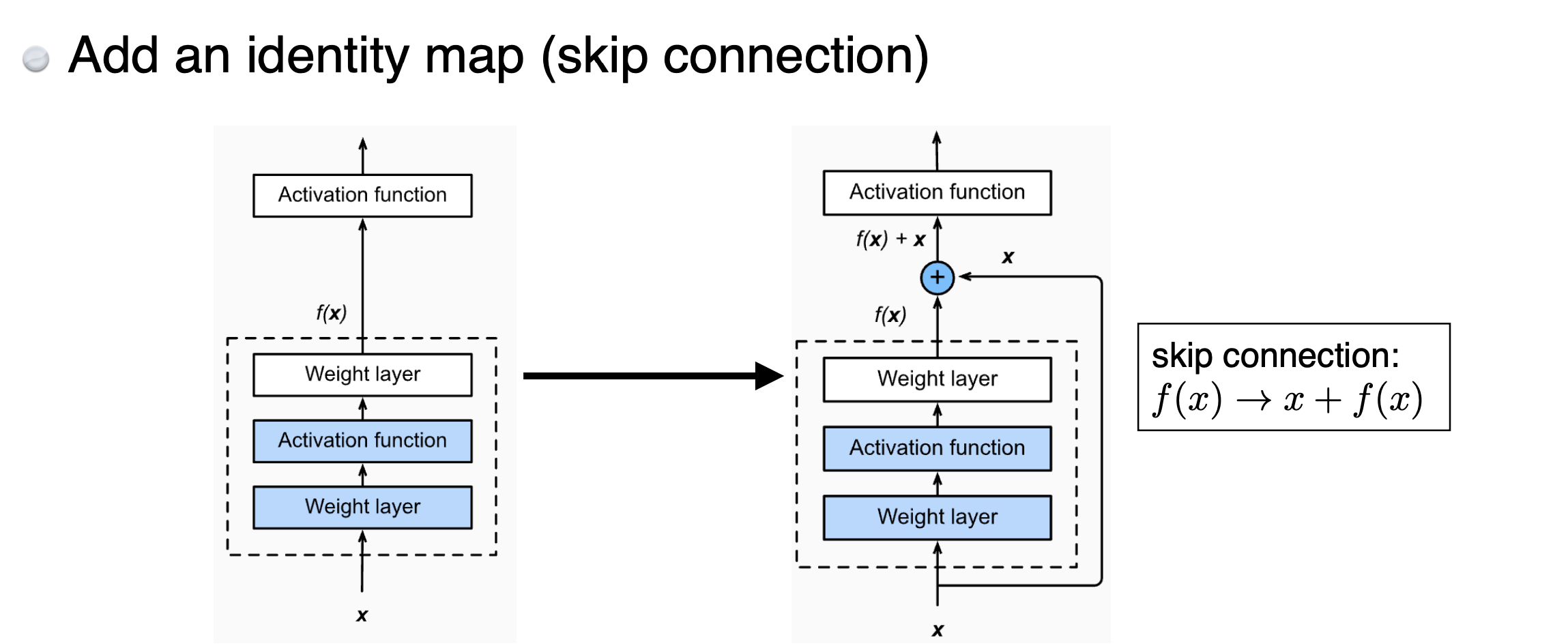
4. ResNet (Kaiming He,… 2015)
layer가 깊어질수록 train error조차 줄어들지 않는, 즉 학습 자체가 잘 되지 않는 상황을 타개하고자 함
Skip connection : →
Skip connection을 활용하여 잔차를 통한 학습이 이루어지게끔 함 (Residual → ResNet)
때문에 input 값과 output 값의 차원을 맞춰줄 수 있게끔 설계해줘야 함
(1x1 convolution을 이용하여 차원을 맞춰주는 것이 Projected Shortcut)
마찬가지로 Bottleneck architecture 사용
5. DenseNet
ResNet에서는 x와 f(x)를 더해서 이용했다면, DenseNet에서는 x와 f(x)를 concatenates 한다
자연스레 출력 크기가 계속 커진다면, channel 또한 커지게 된다
이를 막기 위해서 Batchnorm → 1x1 Conv → 2x2 AvgPooling의 과정을 거치게 된다
6강 Computer Vision Applications
1. Semantic Segmentation
이미지를 픽셀마다 구분해서 어떤 라벨에 속하는지 구분해주는 기법 (자전거와 사람, 배경을 구분한다)
자율주행에서 많이 쓰인다 (자동차, 사람, 도로, 건물 등을 구분해주니까)
-
Fully Convolutional Network 란?
dense layer 대신, convolution layer를 사용하는 것!
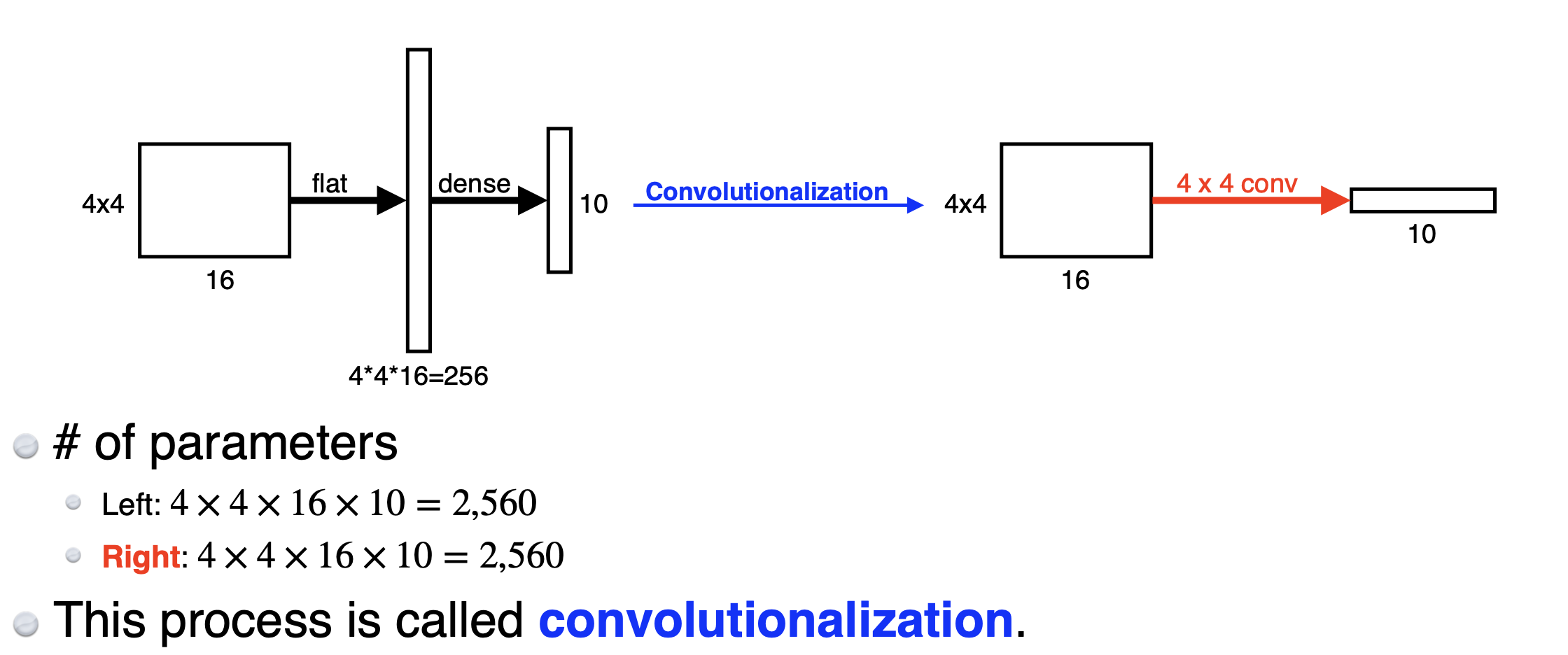
-
왜 Fully Convolutional Network를 사용하는가?
Fully Convolutional Network를 사용하면, input image의 크기가 변경되어도 그대로 연산할 수 있다. 단지 output의 크기나 모델 뒷부분의 크기가 조금 더 커지는것 뿐이다. convolution은 input size가 커져도, 동일한 filter가 찍어내는 output의 크기만 커지기 때문이다. 그것이 heat map의 역할을 할 수 있다.
주의할 점
이처럼 FCN을 이용하면, 고양이 사진에서 고양이가 어디있는지 등의 heat map을 뽑아낼 수 있다. 하지만 그만큼 출력 dimention이 입력 dimention과는 다르게 되고, 그를 복원하는 작업이 필요하긴 하다.
그 중 한 기법으로는 Deconvolution이 있다. 그치만 3+7 = 10 이라는 수식에서 10이라는 결과값은 4+6, 5+5등의 값으로도 표현이 가능하기 때문에 이를 완벽히 재구성하기는 어렵고, 단지 출력의 크기를 입력의 크기로 다시 재조정 한다는 개념으로 이해해야 한다.
2. Detection
이미지 내에서 Bounding Box를 찾는 과정
- R-CNN
- SPPNet
- Fast R-CNN
- YOLO
RNN
RNN 맛보기 (1주차)
- 소리, 문자열, 주가등의 시퀀스 데이터(Sequence data)를 다룬다. 즉 시계열 데이터(Time-Series)는 시퀀스 데이터에 속한다 (이벤트의 발생 순서가 중요한 자료형들)
- 시퀀스 데이터의 표현 with 조건부 확률
- 표현식을 보면, 과거의 모든 데이터가 다음 시퀀스의 데이터를 예측하는데에 필요한 것처럼 보이지만, 실제로는 과거의 모든 데이터가 영향을 주지는 않는다 (시계열 분석에서, 현 시점에서 부터 오래 떨어진 자료일수록 가중치가 적게 들어가는 영향)
DL Basic - RNN (3주차)
Short-term dependencies : 긴 과거일 수록 정보가 손실된 채로 전달되는 현상
****이러한 현상을 방지하기 위해 LSTM을 사용한다. (비슷한 이유로 ReLU를 선호하지 않는다)
LSTM : 이전 단계에서의 output과, 이전 cell에서 넘어온 state(입력 데이터들이 컨베이어 벨트에 올려지며 조작 된다)가 같이 전달된다.
크게는 input, output, forget의 세가지 gate로 나누어져 있다.
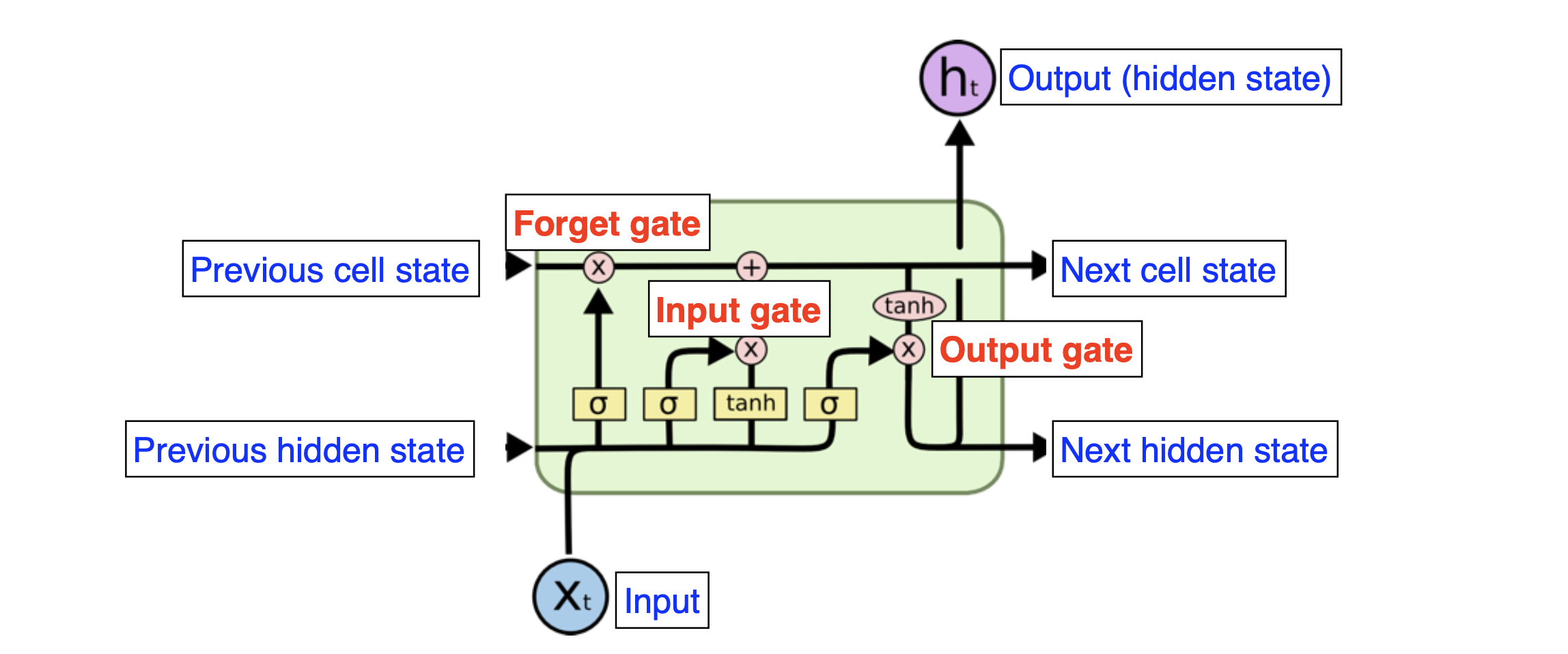
- input gate : 현재 정보와 이전 출력값들을 이용해 cell state에 올릴 정보를 결정
- forget gate : 현재 입력과 이전의 출력을 이용해서 cell state에 올리지 않고 버릴 정보를 결정한다
- update cell : forget gate와 input gate에서 나온 값들을 토대로 cell state에 update 하는 역할을 한다
- output gate : 어떤 값을 출력할지에 대한 결정을 한다
값의 조작과 취합은 sigmoid, tanh 활성화 함수를 통해 이루어진다
GRU (Gated Recurrent Unit) : LSTM과 비슷한 역할을 하지만, 들어오고 나가는 게이트 단 두개만 존재한다
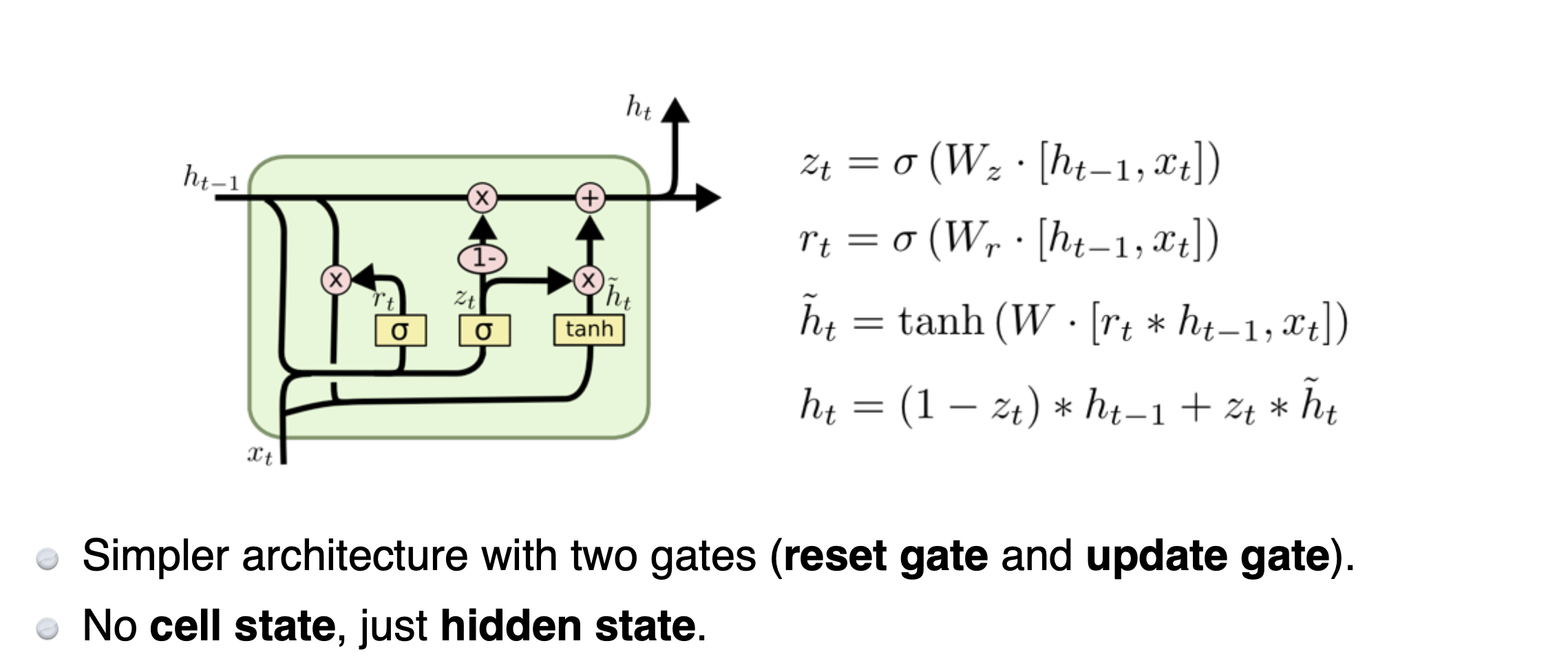
느낀점 및 정리
CNN 모델의 파라미터 수를 계산하여 대략적인 단위수를 알면 모델 설계에 도움이 되기 때문에 꼭 알아둬야 할 것 같다.
실습 및 과제에서 레이어를 쌓는 방법에 대해서 많이 익힌것 같았다. 아마 이번 실습 및 과제에서 익힌 코드 작성 방법들을 후에 모델을 설계하거나 프로젝트를 진행할 때 많이 쓸 것 같다는 느낌을 받았다. 꼭 복습해야겠다.
여러 CNN 계열 모델들의 발전 방향과 원리를 이해하게 된 수업내용이었다.
파라미터의 개수를 줄여가면서 더 깊은 layer들을 쌓을 수 있게 되고, 그럼에서 성능개선이 이루어져가며 모델들이 발전했다는것을 알게되었다.
특히 ResNet의 Skip connection을 활용한 잔차를 통한 학습방법이 인상깊었다.
ResNet의 경우, 다음주에 논문 리뷰를 통해 더 자세히 알아볼 예정이다.
게시글에 사용된 이미지와 수식은 Boostcamp AI Tech의 강의 내용을 참고하였습니다.
