8강 Transformer
구조
- Encoder
- self-attention
- feed forward
- Decoder
- Linear layer and Softmax layer
Attention is All you need (2017) 논문에서 다뤘다
RNN과 마찬가지로 Sequential Data를 다루기 위한 방법론이면서, 조금 다른 방식(Attention 구조)을 가지고 있다.
Original sequence : 1, 2, 3, 4, 5, 6, 7
Trimmed sequence : 1, 2, 3, 4, 5
Omitted sequence : 1, 2, 4, 7
Permuted sequence : 2, 3, 4, 6, 5, 7
- 위와 같이 잘리거나, 순서가 바뀐 sequence data에도 잘 적용할 수 있게끔 설계가 되었으며, self attention 이라는 구조를 갖고 있다.
- Transformer 구조는 Sequential한 data를 처리하고 encoding하는 방법이기 때문에, NLP뿐만이 아니라 이미지 분류, detection에도 사용되기도 한다. 따라서 여러 분야에서 사용되는 기초 방법론이며, GPT-3 구조에서도 self attention 아이디어가 사용된다.
- 데이터의 개수만큼 재귀가 이루어지는 RNN과 달리, 한 번에 encoding 할 수 있다는 점이 있다. (Generation 할 때는 한 번에 한 단어씩 생성해낸다.)
- encoder와 decoder로 이루어져있다.
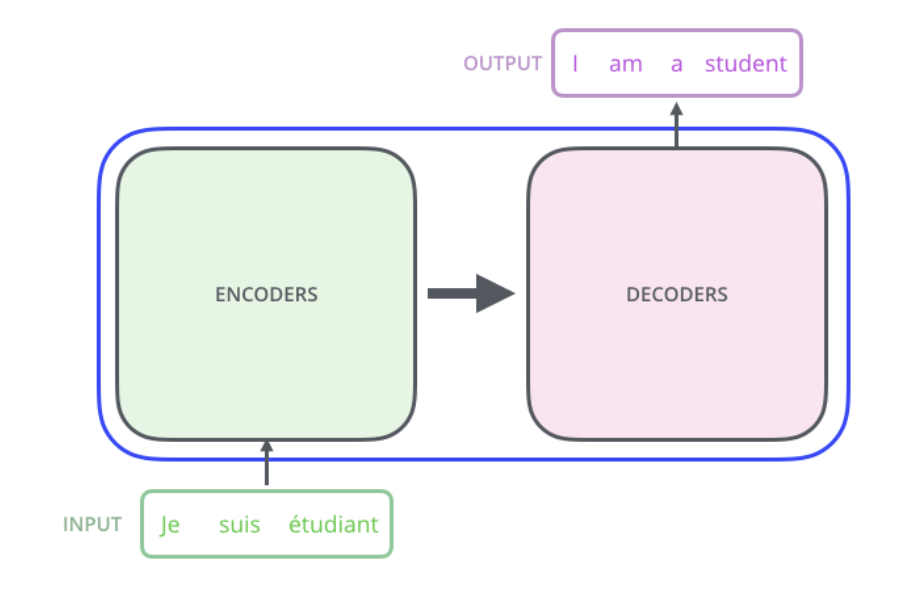
1. Encoder
- Encoder 단계에서, Self-Attention의 경우 n개의 단어가 들어오면 n개의 벡터를 생성해내는데, 자신을 제외한 다른 n-1개의 벡터들도 자신의 벡터를 생성해내는데에 영향을 준다 (dependencies를 갖는다)
- 예를들어 문장에서 대명사와 같은 단어가 등장했을 때, 대명사가 어느 단어를 나타내고 있는지의 관계를 고려하여 벡터를 생성해주는것을 도와준다
- Feed Forward Neural Network에서는 입력들끼리 independence하게 작동된다.
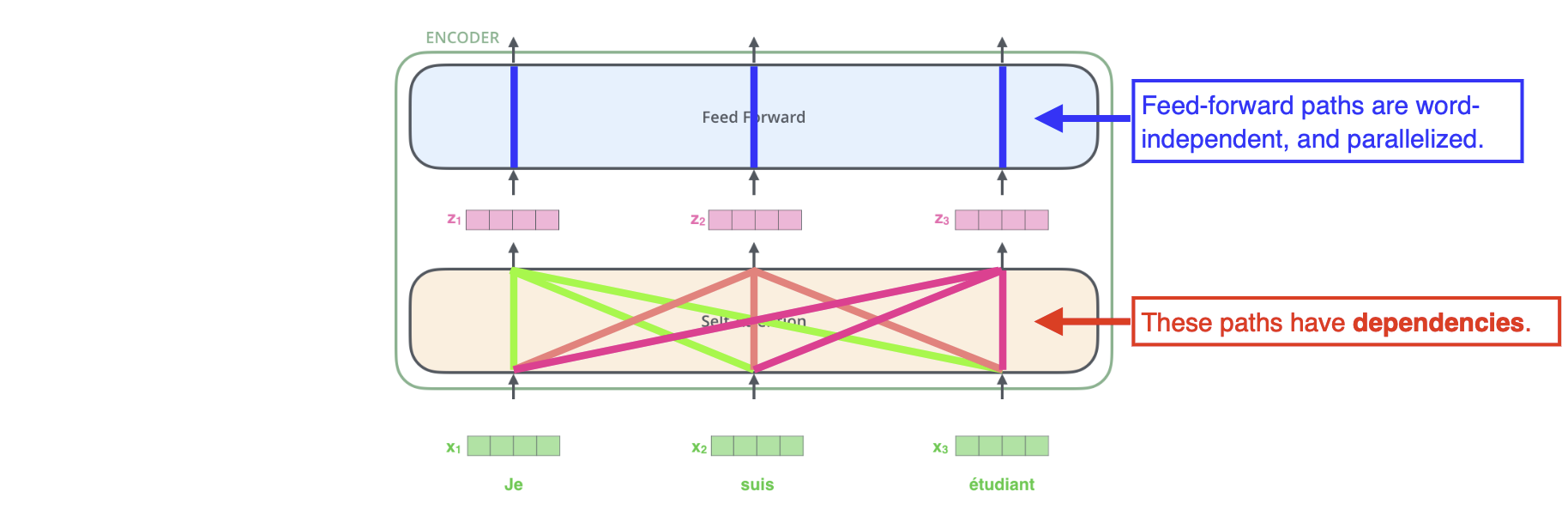
Self-Attention 구조 자세히 뜯어보기
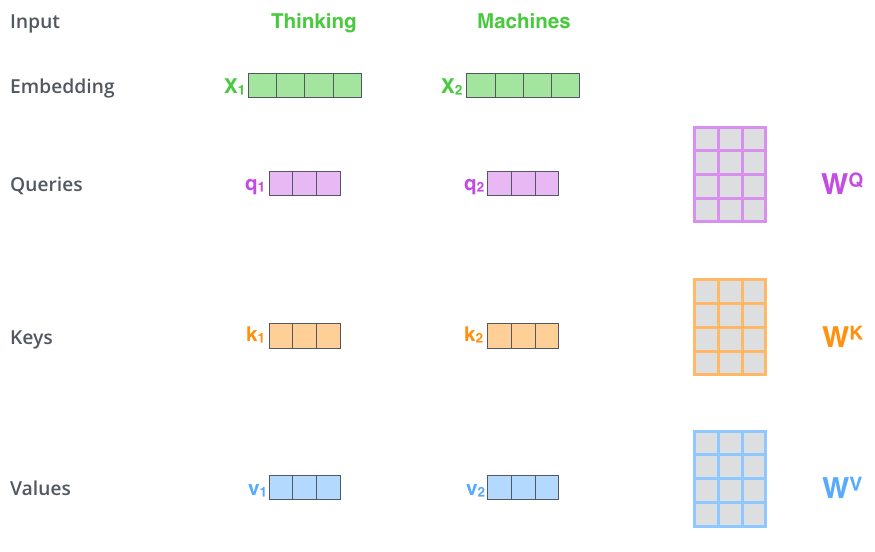
- 입력받은 단어를 Word2vec 등의 방법을 이용하여 embedding 시켜 벡터를 생성한다.
- 각 벡터마다 Queries, Keys, Values 벡터를 생성한다.
- 이 때, 각 벡터는 embedding 벡터와 각각의 가중치 행렬과의 행렬 곱 연산을 통해 만들어진다.
- 생성된 Queries 벡터와 Keys 벡터간의 내적으로 모든 단어의 Score를 생성한다.
- Scores를 정해진 값으로 나눠준다.
- 4번에서 구한 값을 토대로 Softmax 연산을 수행한다.
- 5번에서 나온 단어별 Softmax 값과 Values 벡터를 곱해준다. (스칼라와 벡터의 곱 연산)
- 6번의 결과로 나온 모든 벡터들을 더해준다. (벡터끼리 합 연산)
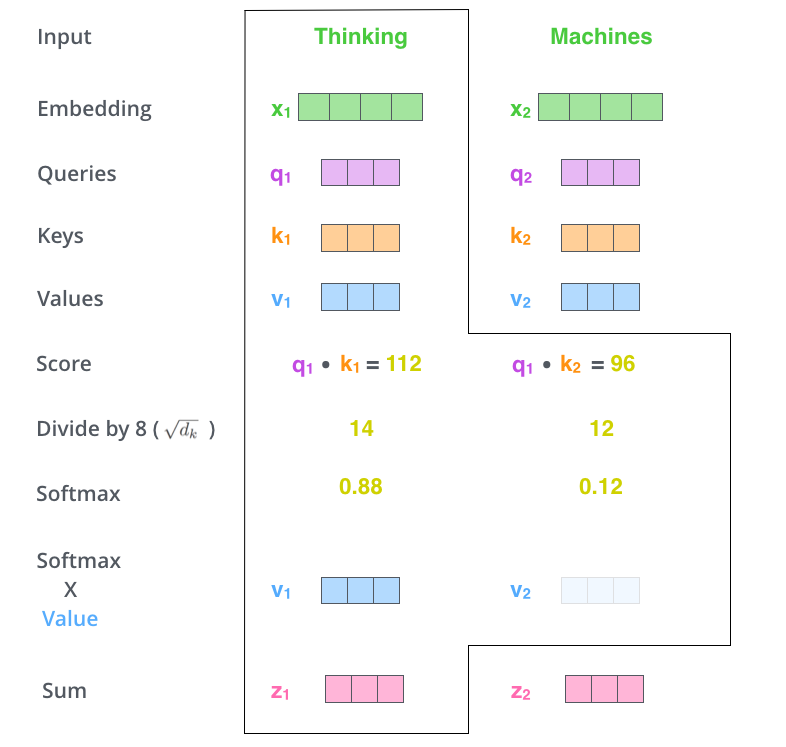
위의 7단계를 거쳐서 나온 z벡터를 feed-forward 신경망에 전달하여 이 때 부터는 각각의 연산이 따로 이루어진다. 참고로 위의 7단계 연산은 행렬식으로 표현하면 아주 간단하게 표현 할 수 있다.
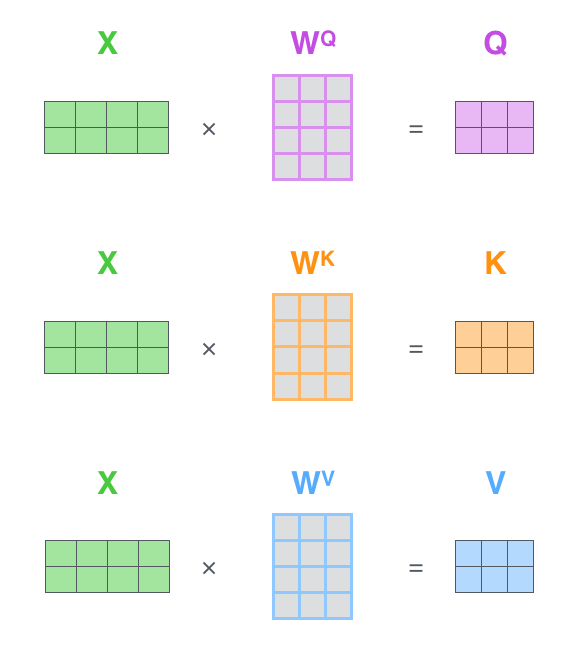
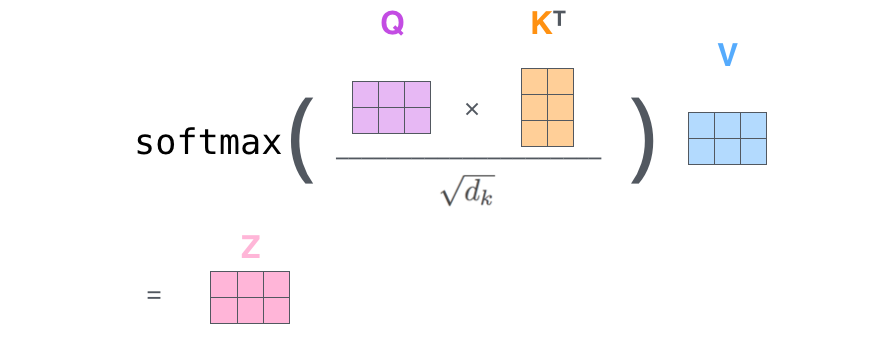
X는 입력된 각각의 벡터들을 concatenate 하여 행렬로 만든 것이고, 그렇게 하면 각각의 벡터 연산들을 묶어 한 번에 행렬연산으로 수행 할 수 있다.
출처 : https://nlpinkorean.github.io/illustrated-transformer/
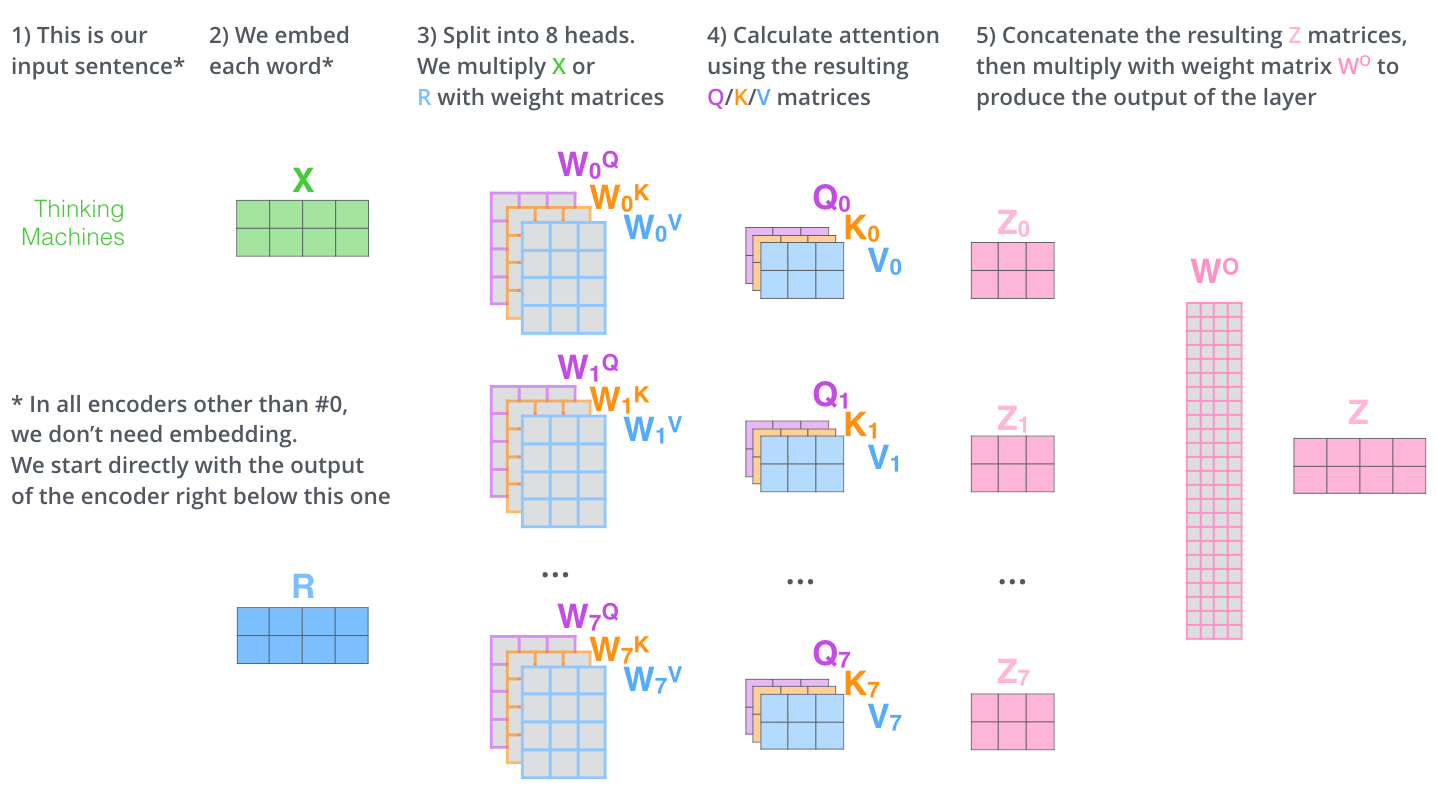
Multi-headed Self-Attention 구조
Self-Attention 구조에서, 가중치 행렬인 들을 여러개 만들어서 여러개의 encoding 결과물을 만들어낸 후, 그것들을 concatenate 하여 계산한다. 결국 가중치 행렬의 개수 차이 말고는 Self-Attention 구조와 대동소이하다.
Positional Encoding
위의 과정에서 의문점이 드는 것은 Transformer는 입력의 순서에 따라 출력물이 달라진다고 알고 있는데, 앞의 단계에서는 전혀 입력의 순서를 고려하지 않고 있다. (independent하다.) 그래서 이용되는 것이 Positional Encoding이며, 임의의 값을 embedding 벡터에 더해주는 것으로 순서를 고려할 수 있게 만든다.
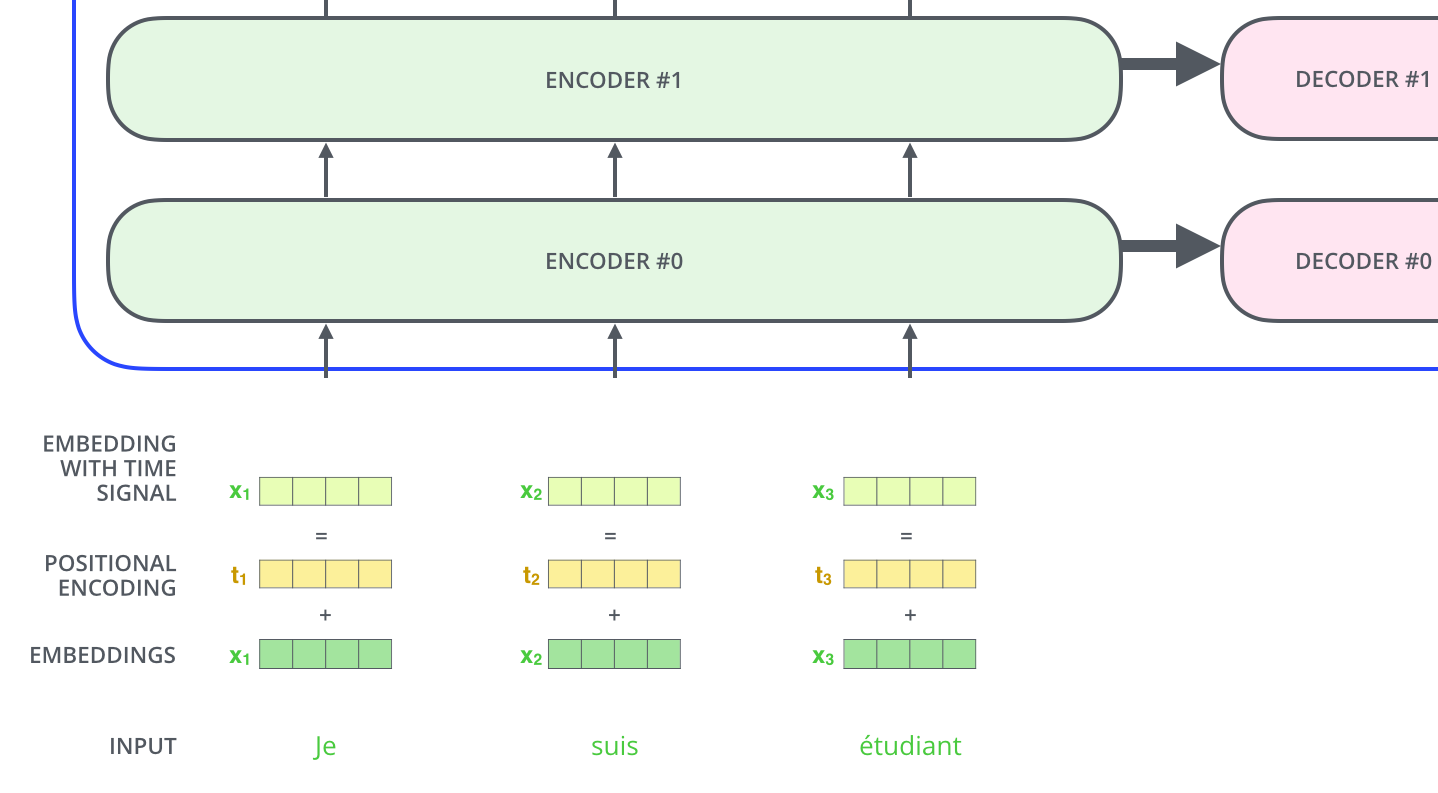
여기까지의 과정을 한 그림으로 생략하자면 다음과 같다.
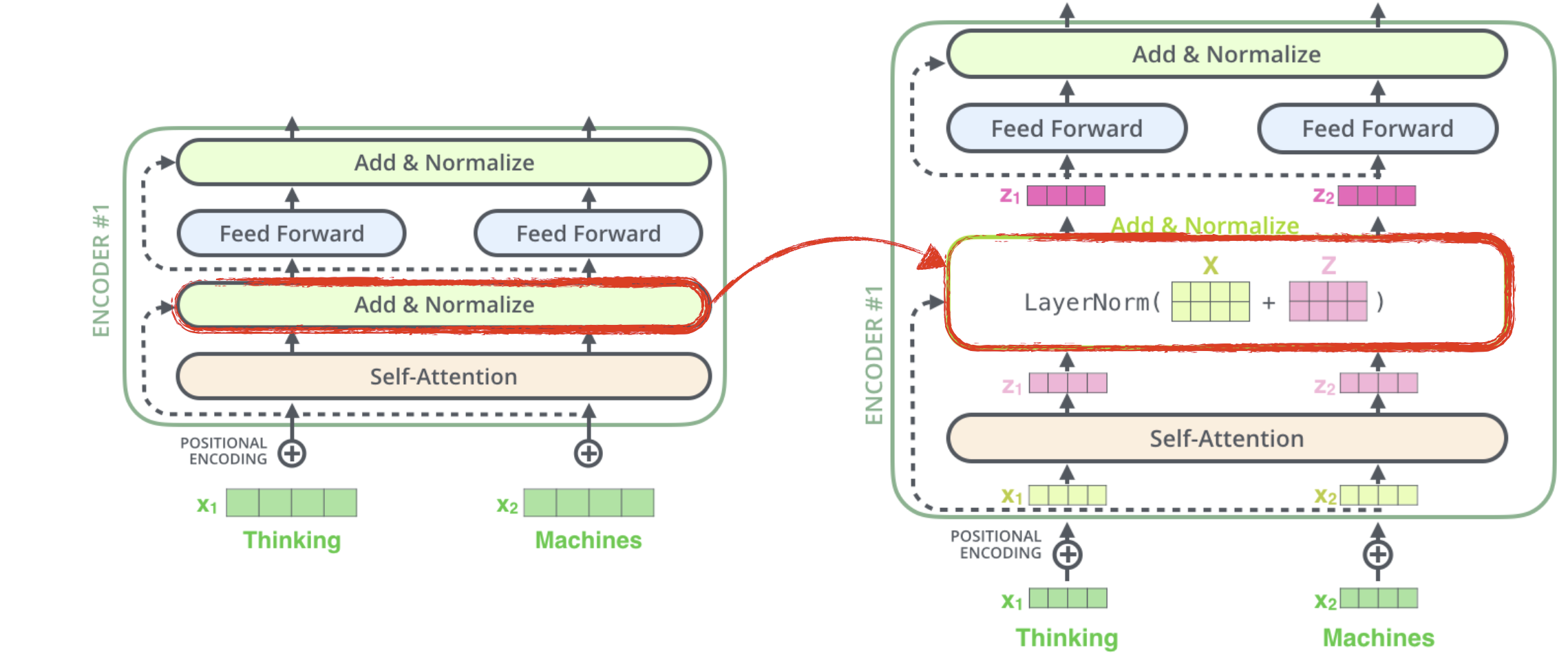
Encoding 단계에서 Layer normalization 단계가 추가로 들어간다는 사실만 알고 넘어가면 될 것 같다.
2. Decoder
Decoder에서는 단어를 생성하기 위해서 Encoder 단계에서 생성되고 쓰였던 Keys, Values 벡터(행렬)를 이용한다.
Decoder Side가 작동 하는 방법은 아래 페이지에서 gif 파일을 보며 쉽게 이해할 수 있다.
단어가 하나씩 순차적으로 Decoder를 통해 생성이 되는 것을 확인할 수 있다.
최근들어 Self-Attention의 원리와 작동방법을 이미지 데이터에도 사용하기 시작했다.
DALL-E가 그 예시이며, DALL-E는 문장을 토대로 이미지를 생성하는 모델을 뜻한다.(GPT-3 를 이용한 모델)
게시글에 사용된 이미지는 Boostcamp AI Tech의 강의 내용, 출처 블로그를 참고하였습니다.
출처 : https://nlpinkorean.github.io/illustrated-transformer/
