Word2Vec → Item2Vec
텍스트 분석 방법인 Word2Vec에서 추천 시스템 임베딩으로 발전한 Item2Vec의 관계, 차이점에 대해 배운 강의 내용을 정리 (RecSys 5강)
Embedding에 관하여
- Sparse Representation : 원핫 인코딩 같이 1,0으로 표현되며, 아이템의 전체 가짓수와 차원 동일
- Dense Representation : 실수 값으로 표현되며, 아이템의 전체 가짓수보다 훨신 작은 차원
Word Embedding
텍스트 분석을 위해 단어를 벡터로 표현하는 방법
비슷한 단어일수록 embedding vector가 가까운 위치에 분포
이렇게 표현하기 위해서는 학습 모델이 필요하다
→ MF도 이러한 학습의 일종이라고 볼 수도 있다
Word2Vec
뉴럴 네트워크 기반, 간단한 구조라 효율적으로 빠른 학습 가능
학습 방법 : CBOW, Skip-Gram, Skip-Gram w/ Negative Sampling(SGNS)
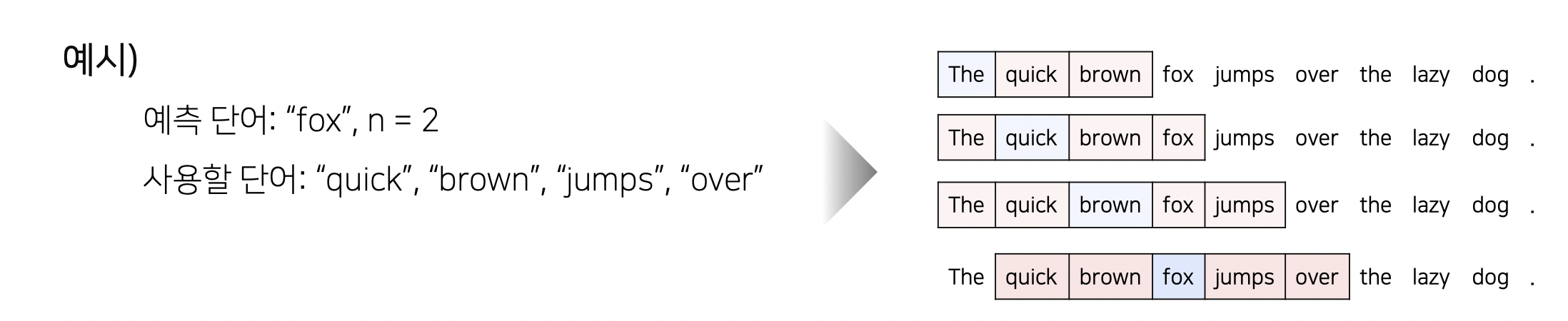
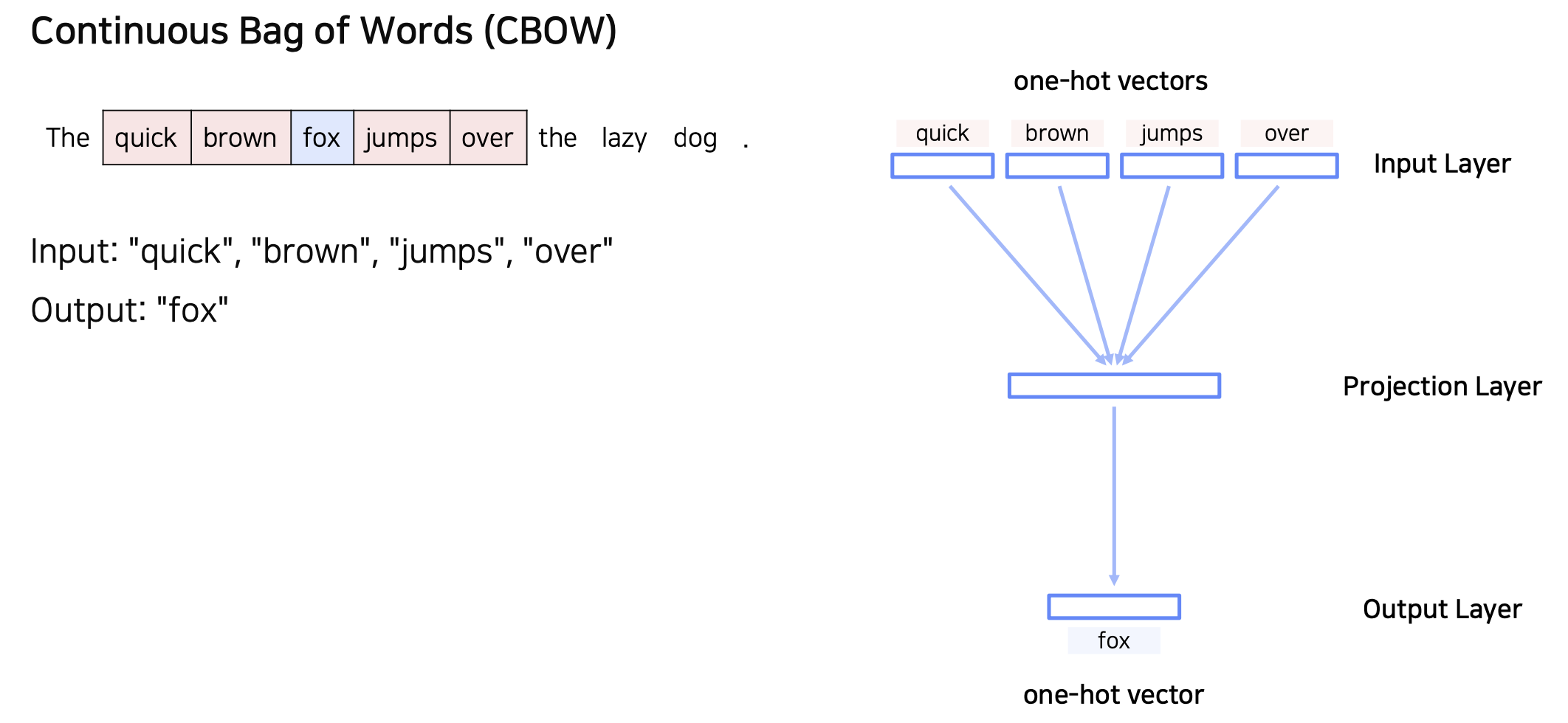
1. CBOW
CBOW
- 주변에 있는 단어를 가지고 센터에 있는 단어를 예측하는 방법
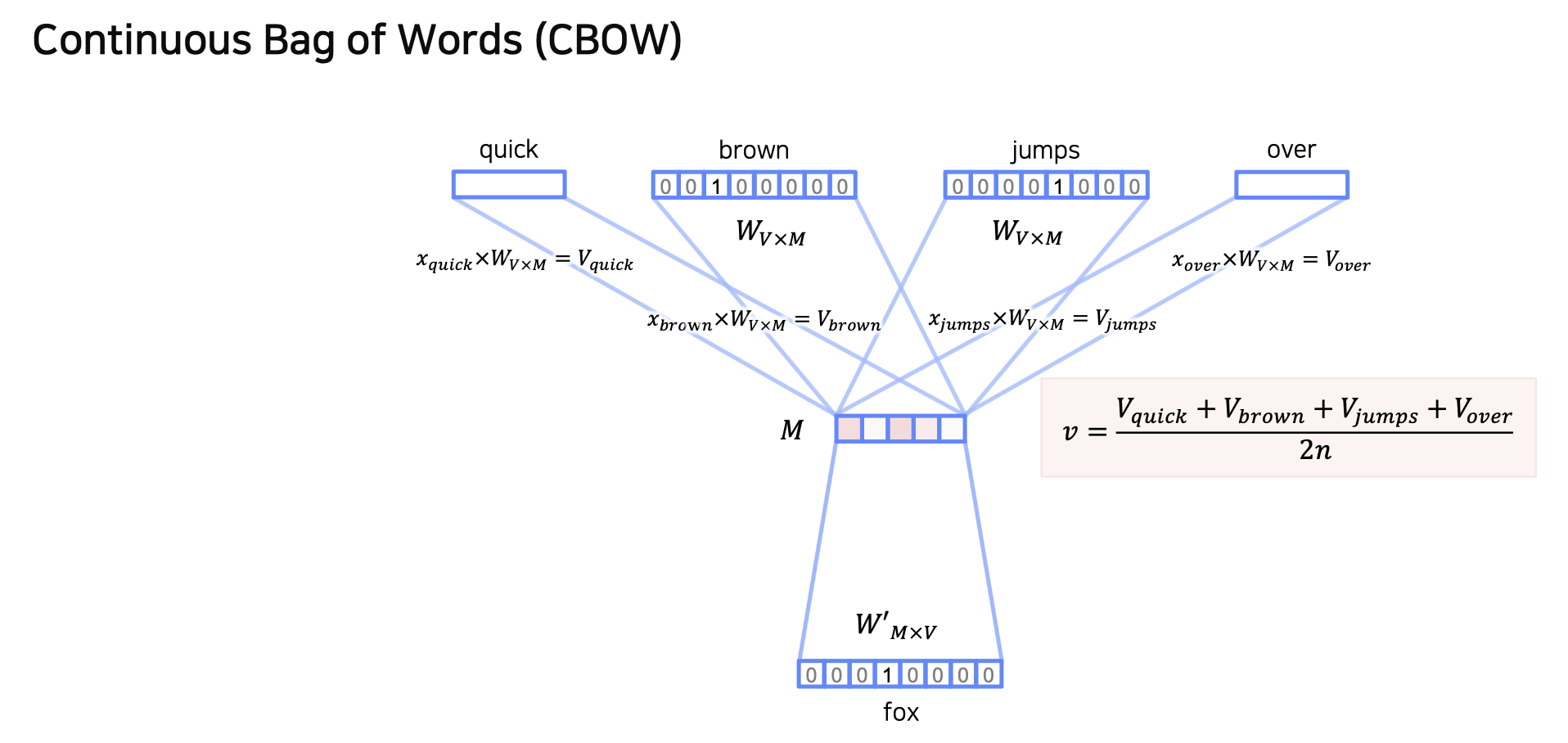
단어의 총 개수가 이고, 임베딩 벡터의 사이즈가 이라고 할 때,
input Layer에서 Projection Layer로 보내주는 Embedding matrix()와
Projection Layer에서 output layer로 보내주는 Embedding matrix()를 학습해야 한다
마지막 출력 Layer에서는 sofrmax 함수를 이용해 실제 벡터와 계산된 벡터의 cross entropy를 계산 후 학습해 나가는 과정을 반복한다.

2. Skip-Gram
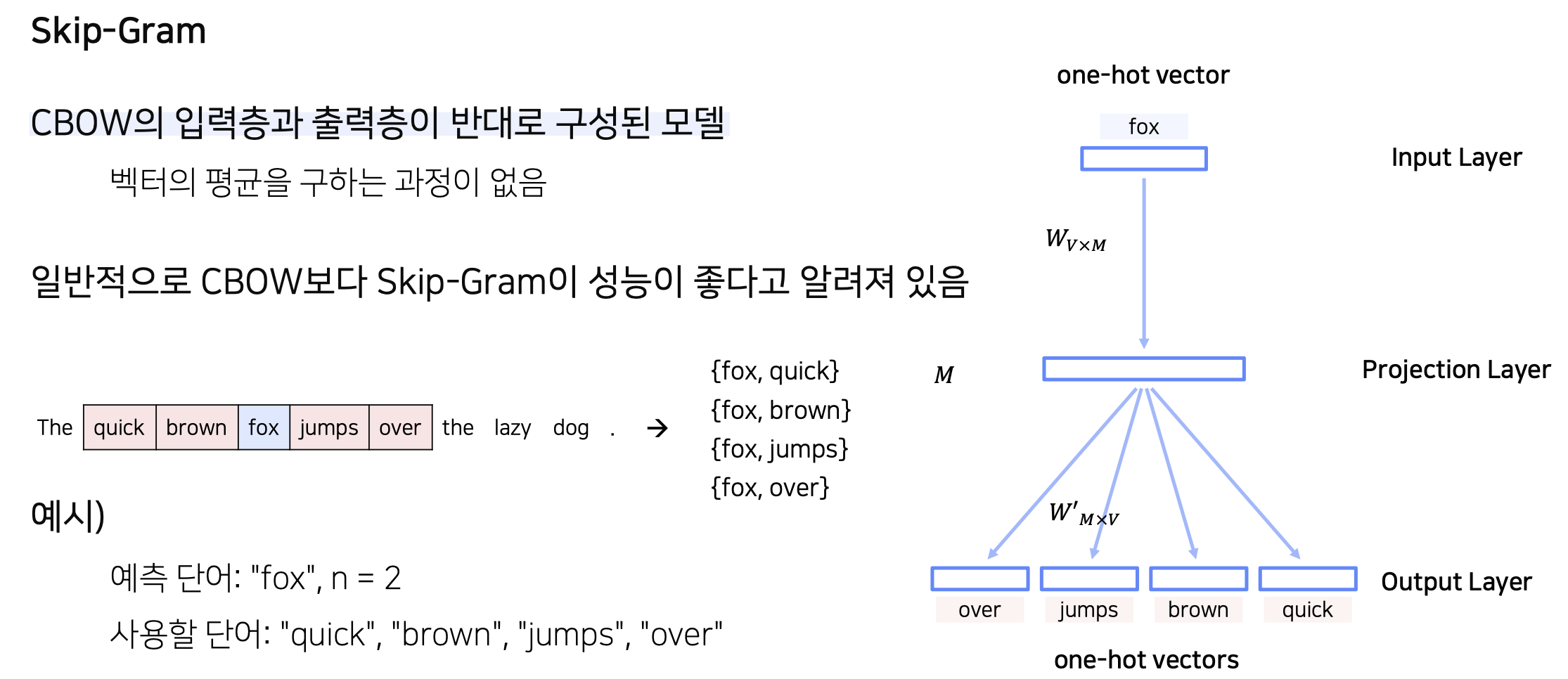
Skip-Gram
CBOW와 반대인 모델 (입력층과 출력층이 반대로)
따라서 입력과 출력의 개수가 반대
하지만 학습하는 파라미터 행렬의 차원은 같다 (Embedding size가 같다면)
일반적으로 CBOW보다 고성능
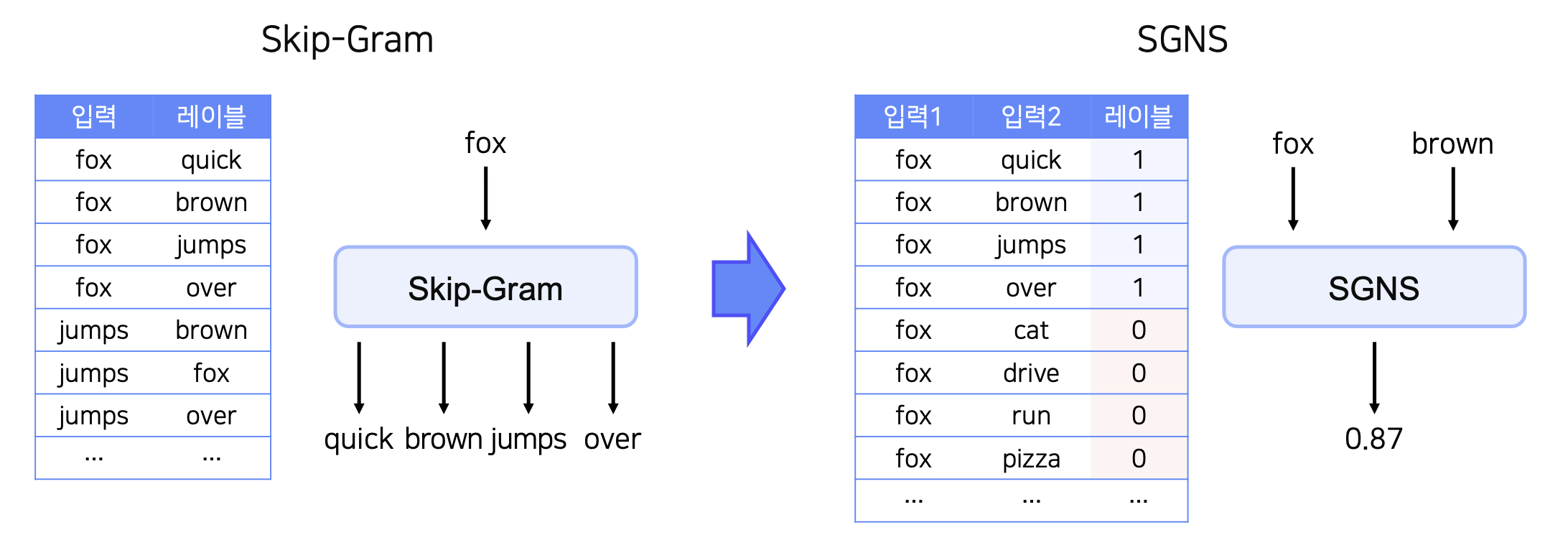
3. Skip-Gram with Negative Sampling
SGNS
Skip-Gram에서는 주변 단어의 개수를 지정해주면 그 개수만큼 output이 생기지만,
SGNS에서는 주변 단어가 맞는지 아닌지 판단하는 이진분류로 바뀌게 된다.
따라서 Input에는 2개의 단어가 들어가면, 그 단어들이 가까이 있는지 판단해주는 확률값이 Output이 된다.
레이블을 생성하는 과정에서, 주변에 있는 단어들끼리만 가지고 생성하면, 모든 레이블이 1이 된다.
그렇기 때문에 주변에 있지 않은 단어들 또한 레이블을 생성하는 과정에 포함되어야 하고 그러므로 “Negative Sampling”이라는 용어가 붙게 되었다.
이 때, 중심단어 하나당 몇개의 negative sampling을 할 것이냐가 하이퍼 파라미터가 된다.
학습 데이터가 적으면 5-20, 충분히 큰 경우 2-5개를 추천한다.
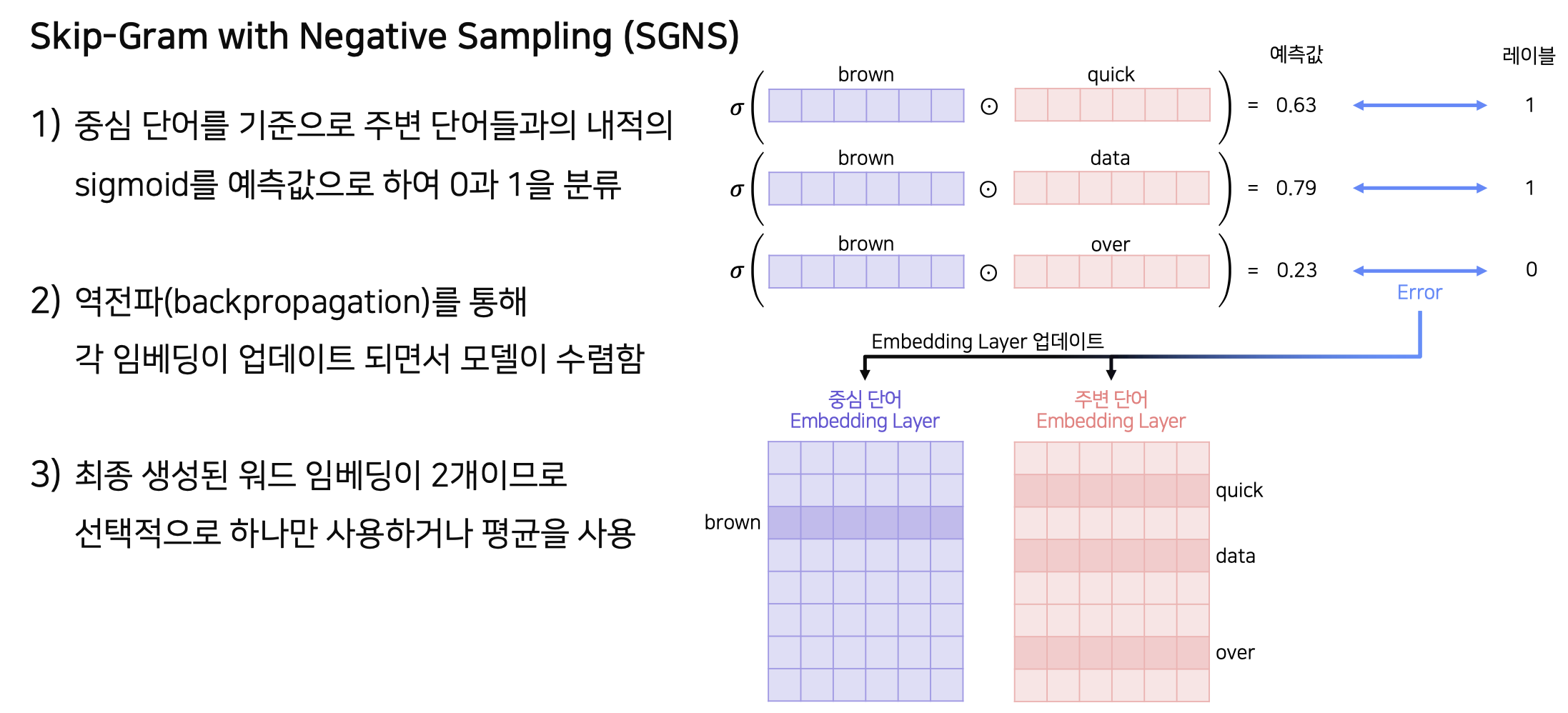
ex) fox 라는 중심단어 하나당 4개의 negative label을 sampling 한다.중심 단어와 주변 단어가 각각의 embedding matrix를 갖게 된다.
Input으로 들어온 중심 단어와 주변 단어 각각의 vector를 내적하고 sigmoid 연산을 이용하여 output을 0과 1로 분류하고 발생한 loss를 이용하여 embedding matrix를 학습한다.
위 단계에서 학습한 각 단어의 Embedding Matrix, Vector가 중요한 역할을 한다.
ex) brown의 중심 단어 임베딩 벡터
Item2Vec
- 단어가 아닌 추천 아이템을 Word2Vec을 이용하여 임베딩
- 유저가 소비한 아이템 리스트를 문장으로, 아이템 리스트 안의 아이템을 단어로 가정
- 유저-아이템 관계를 사용하지 않기 때문에 유저 식별 없이 세션 단위로도 데이터 생성이 가능하다.
- SVD 기반 MF를 사용한 IBCF보다 Word2Vec이 더 높은 성능과 양질의 추천결과를 제공한다.
유저 혹은 세션 별로 소비한 아이템 집합을 생성하고, 이 때 공간/시간적 정보는 생략된다.
ex) A,C,B 순으로 소비 했더라도 순서를 고려하지 않은 집합 {A,B,C} 탄생그렇기 때문에 당연히 집합 내 모든 아이템 쌍들은 Positive sample이 된다.

ANN (Approximate Nearest Neighnbor)
- NN : 내가 원하는 Query Vector와 가장 유사한 Vector를 찾는 알고리즘
- MF 모델을 예로 들면, 유저에게 아이템을 추천해주려면 1. 유저의 벡터와 후보 아이템 벡터 2. 해당 아이템 벡터와 다른 후보 아이템 벡터 들의 유사도 연산을 통해 가장 유사한 아이템을 추천해준다는 의미에서 NN 알고리즘이 도움이 될 수 있다.
- 위의 아이디어를 이용하면, 모델 학습을 통해 구한 유저/아이템 벡터와 가장 인접한 이웃을 찾아 추천해줄 수 있게 된다.
- 정확히 가장 인접한 벡터를 찾으려면 연산량이 많아 시간적 손해를 보기 때문에, 정확도를 약간 포기하더라도 빠른 시간내에 찾는 방법을 고려해 나온것이 ANN
- 200ms, 100% 정확도 X
- 1ms, 90% 정확도
- 2-3ms, 99% 정확도 O
ANNOY : spotify가 개발한 tree-based ANN
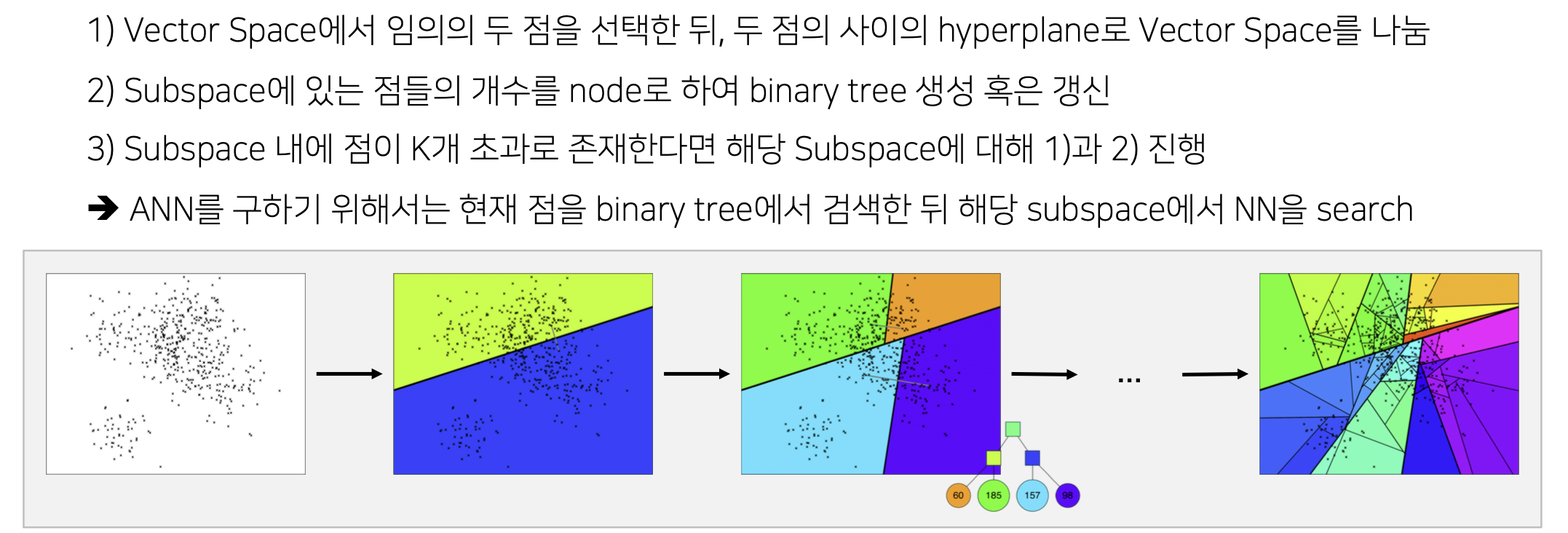
ANNOY 작동 원리
이진 분류를 반복하며 tree 구조를 갖게 된다.
가장 가까운 벡터가 속한 subspace를 O(logn)의 속도로 찾을 수 있다.


ANNOY 특징
- Search Index를 생성하는 것이 다른 ANN 기법에 비해 간단하고 가벼움 (GPU연산은 불가능)
- 아이템 개수가 많지 않고 벡터의 차원이 낮은 경우(d<100) 사용하기에 적합
- Search 해야 할 이웃의 개수를 알고리즘이 보장함
- 파라미터 조정을 통해 accuracy와 speed 간 trade-off를 조정할 수 있음 (num_tree, search_k..)
- 새로운 데이터를 추가하려면 새로운 tree를 생성 및 학습해야 함
게시글에 사용된 이미지와 자료는 Boostcamp AI Tech의 강의 자료, 출처를 참고하였습니다.
출처 : https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup
