생선 분류 문제
도미 데이터 준비하기
+ 이진 분류 : 머신러닝에서 여러 개의 종류(or 클래스(class)) 중 하나 구별해 내는 문제를 분류(classification)라고 하는데 2개의 클래스 중 하나 고르는 문제를 말한다.
35마리의 도미의 길이(cm)와 무게(g)를 파이썬 리스트로 만든다.
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]특성 : 데이터의 특징
import matplotlib.pyplot as plt # matplotlib의 pyplot 함수를 plt로 줄여서 사용
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()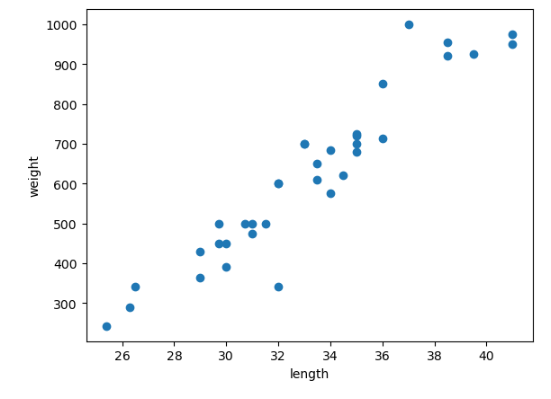
--> 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우를 선형(linear)적이라고 한다.
방어 데이터 준비하기
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weigth')
plt.show()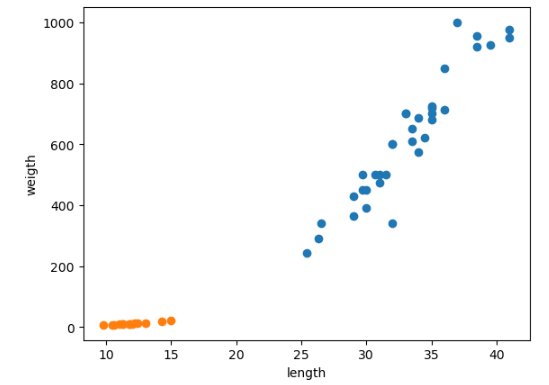
--> 빙어의 산점도도 선형적이지만 무게가 길이에 영향을 덜 받는다.
첫 번째 머신러닝 프로그램
k-최근접 이웃(k-Nearest Neighbors) 알고리즘 사용해서 빙어 데이터 구분하기.
위의 두 데이터를 하나의 데이터 리스트로 만들기
length = bream_length + smelt_length
weight = bream_weight + smelt_weight이 데이터는 앞에서부터 35개는 도미의 길이/무게, 14개는 빙어이 길이/무게가 하나로 연결하여 리스트로 저장된다.
사이킷런(scikit-learn) : 머신러닝 패키지. 2차원 리스트가 필요하다.
이 사이킷런을 사용하기 위해선 세로 방향으로 늘어뜨린 2차원 리스트를 만들어야 한다.
그러기 위해선 파이썬의 zip() 함수와 리스트 내포(list comprehension) 구문을 사용하는 것이 가장 쉽다.
fish_data = [[l, w] for l, w in zip(length, weight)]
마지막으로 각각 어떤 생선인지 답을 만드는 정답 데이터가 필요하다. 근데 이걸 왜 만들지??
-> 머신러닝 알고리즘이 구분하는 규칙을 찾길 원하기 때문에 어떤 것인지 알려줄 필요가 있다!
fish_target = [1] * 35 + [0] * 14--> 머신러닝에서 2개를 구분하는 경우 찾으려는 대상을 1로 두고 그 외에는 0으로 놓는다.
from sklearn.neighbors import KNeighborsClassifier
# KNeighborsClassifier를 임포트
kn = KNeighborsClassifier()
# 객체 만들기훈련(training)
: 이 객체에 fish_data와 fish_target을 전달하여 도미 찾기 위한 기준을 학습시킨다. 이런 과정을 머신러닝에서 부르는 용어. 사이킷런에선 fit() 메서드가 이런 역할을 한다. (모델에 데이터를 전달하여 규칙을 학습하는 과정을 훈련이라고 한다.)
kn.fit(fish_data, fish_target)fit() 메서드는 주어진 데이터로 알고리즘을 훈련한다.
score() 메서드 : 사이킷런에서 모델을 평가하는 메서드. 0에서 1 사이 값을 반환. 1은 모든 데이터를 정확히 맞혔다는 의미.
kn.score(fish_data, fish_target)
1.0--> 모든 fish_data의 답을 정확히 맞췄다. 이를 정확도(accuracy)라고 부른다.
k-최근접 이웃 알고리즘
: 어떤 데이터에 대한 답을 구할 때 주위의, 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용.
kn.predict([[30, 600]])
array([1])predict() 메서드 : 새로운 데이터의 정답을 예측. 리스트의 리스트를 전달해야 한다.
k-최근접 이웃 알고리즘은 새로운 데이터에 대해 예착할 때는 가장 가까운 직선거리에 어떤 데이터가 있는지를 살피기만 하면 된다. 하지만 데이터가 아주 많은 경우엔 사용하기 어렵다는 단점이 있다. 데이터가 크기 때문에 메모리가 많이 필요하고 직선거리를 계산하는 데도 많은 시간이 필요하다.
KNeighborsClassifier 클래스는 가까운 데이터를 기본값으로 5를 가진다. n_neighbors 매개변수로 바꿔줄 수 있다.
kn49 = KNeighborsClassifier(n_neighbors = 49)
# 참고 데이터를 49개로 한 kn49 모델
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
0.7142857142857143n_neighbors를 49로 두는 것은 예측이 좋지 못하다. 결국 5가 제일 좋다!
도미와 빙어 분류
전체 소스 코드
"""# 마켓과 머신러닝"""
"""## 생선 분류 문제"""
"""### 도미 데이터 준비하기"""
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
# matplotlib의 pylot 함수를 plt로 줄여서 사용
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
"""### 빙어 데이터 준비하기"""
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
"""## 첫 번째 머신러닝 프로그램"""
length = bream_length+smelt_length
weight = bream_weight+smelt_weight
fish_data = [[l, w] for l, w in zip(length, weight)]
print(fish_data)
fish_target = [1]*35 + [0]*14
print(fish_target)
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)
"""### k-최근접 이웃 알고리즘"""
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
kn.predict([[30, 600]])
print(kn._fit_X)
print(kn._y)
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
print(35/49)
<정리>
- 특성 : 데이터를 표현하는 하나의 성질.
- 훈련 : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정. 사이킷런에서는 fit() 메서드가 하는 역할.
- k-최근접 이웃 알고리즘 : 가장 간단한 머신러닝 알고리즘 중 하나. 전체 데이터를 메모리에 가지고 있는 것이 전부.
- 모델 : 머신러닝 프로그램에서 알고리즘이 구현된 객체.
- 정확도 : 정확한 답을 몇 개 맞혔는지 백분율로 나타낸 값. 사이킷런에선 0-1 사이 값으로 출력.
정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
핵심 패키지와 함수
-
matplotlib
- scatter() : 산점도 그리는 맷플룻립 함수. c매개변수로 색깔 지정. 지정하지 않을 경우 10개의 기본 색깔을 이용해 그래프 그린다.
marker 매개변수로 마커 스타일 지정. 기본값은 o(circle, 원). -
scikit-learn
KNeighborsClassifier() : k-최근접 이웃 분류 모델 만드는 사이킷런 클래스. n_neighbors 매개변수로 이웃의 개수 정함. 기본값은 5.
p 매개변수로 거리 재는 방법을 지정. 1 : 맨해튼 거리, 2: 유클리디안 거리 사용. 기본값은 2.
n_jobs 매개변수로 사용할 CPU 코어를 지정할 수 있다. -1로 설정하면 모든 CPU 코어를 사용. 이웃 간 거리 계산 속도 높일 수 있지만 fit() 메서드에 영향 X. 기본값은 1fit() : 사이킷런 모델 훈련할 때 사용하는 메서드. 처음 두 매개변수로 훈련에 사용할 특성과 정답 데이터를 전달한다.
predict() : 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드. 특성 데이터 하나만 메개변수로 받는다.
score() : 훈련된 사이킷런 모델의 성능을 측정. 처음 두 매개변수로 특성과 정답 데이터를 전달. 이 메서드는 먼저 predict() 메서드로 예측 수행한 다음 분류 모델일 경우 정답과 비교하여 올바르게 예측한 개수의 비율을 반환.
