❖ 논문 선정 이유
-
요즘 추천 시스템도 재미있지만, 최근 연구 트렌드를 보면 LLM과 Agent 분야가 압도적으로 많아서 자연스럽게 관심이 더 가기 시작되었고 그래서 LLM 관련 핵심 논문들도 하나씩 읽어보려고 마음먹었고, 그 출발점으로 이 논문을 선택함
-
이 논문은 사실상 지금의 LLM 시대를 연 시작점 같은 존재라 할 수 있으며 Transformer 구조와 Self-attention이라는 개념을 처음 제시하면서 이후 BERT, GPT 계열 모델들이 등장할 수 있는 토대를 만들었음
-
학교 수업에서 Self-attention을 배울 때 교수님이 이 논문은 나중에 꼭 따로 읽어보라고 강조하셨던 것도 기억나서, 이번 기회에 첫 LLM 논문 리뷰로 선택하게 됨
❖ 1. Introduction
문제 의식
기존의 seq2seq 모델(RNN/LSTM/GRU)은 병렬처리가 안되어서 긴 시퀀스 처리 느리고 장기 의존성 잡기 어렵고 CNN 기반은 receptive field 넓히기 위해 깊어져야 해서 어려움
- 이 논문에서는 RNN 없이 오직 Attention으로만 구성한 모델 제안
❖ 2. Background
-
Intro에서 언급한 것 처럼 기존 딥러닝 모델은 순차 처리(RNN) 또는 깊은 구조(CNN) 때문에 비효율적이였고 멀리 떨어진 단어 간 관계 학습이 어렵고 비용 컸음
-
Self-Attention은 이를 한 번에 처리해서 문맥 이해를 효율적으로 함
-
Self-Attention은 기존엔 보조 기능이었지만 Transformer는 이를 모델 중심으로 사용하였고 결과적으로 입력과 출력의 의미 표현을 학습하는 최초의 sequence transduction 모델이 되었음
❖ 3. Model Architecture
◆ 3.1 Encoder and Decoder Stacks
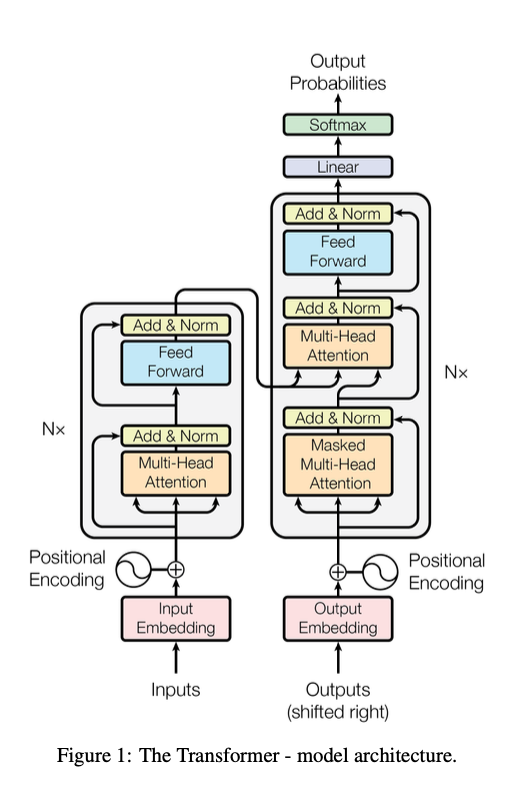
Encoder
-
역할
- 입력 문장을 이해해서 의미 벡터 Z로 변환
-
구성
- Encoder는 동일한 구조의 Layer를 6번(Stack of N=6) 반복
- 각 Layer는 2개의 Sub-layer로 구성
- Multi-Head Self-Attention
- Feed-Forward Network (FFN)
(= 토큰마다 독립적으로 적용되는 두 단계 fully-connected network)
Decoder
- 역할
- Encoder가 만든 의미 벡터 Z를 참고하여
- 출력 문장을 한 단어씩 생성 (Auto-regressive)
- 구성
- Decoder도 6개의 동일한 Layer로 구성
- 하지만 Encoder와 다르게 Sub-layer가 3개
◆ 3.2 Attention
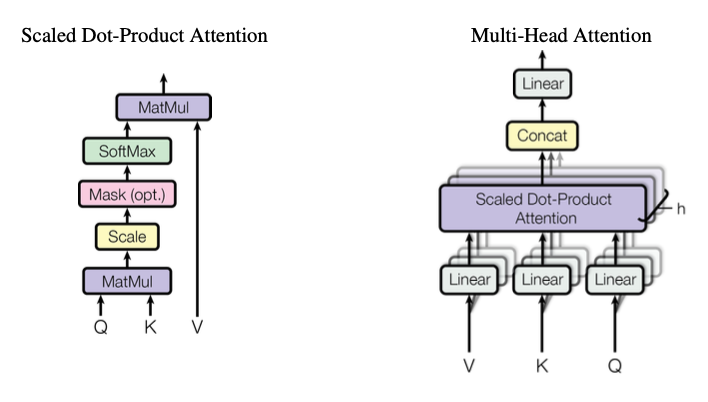
3.2.1 Scaled Dot-Product Attention
Attention이란 Query(Q), Key(K), Value(V)를 입력 받아 Value들의 가중합(weighted sum)을 반환하는 함수임
즉, 중요한 정보(Value)를 더 많이 반영하는 방식으로 문장 표현을 만드는 기술
Q,K,V
- Q : 지금 내가 알고 싶은 관점 (query)
- K : 각 단어가 가진 기준 정보 (key)
- V : 실제 포함된 의미 정보 (value)
Q × Kᵀ (MatMul)
- 각 Query와 모든 Key의 dot product 계산
→ 관심도 점수(attention score)
Softmax
- score → 확률(비율)로 변환
이해하기 위한 설명
-
위 설명이 정의이지만 논문을 읽을 때 Query(Q), Key(K), Value(V)와 Self-Attention 가 이해가 잘 되지 않아서 이해하기 쉽게 정리해보았음
-
Self-Attention을 과자 나누기로 이해하는 방법임
상황 설정은 사람 4명(A, B, C, D)이 있는데 과자 10개를 나눠줘야 하는 상황임 -
그냥 똑같이 2.5개씩 주는 게 아니라 각 사람이 얼마나 중요한지에 따라 비율을 다르게 나누고 싶은거임
1) Query / Key / Value 개념
Self-Attention에서 각 단어는 3개의 정보를 가지는데 사람으로 비유하면:
| 역할 | 의미 | 비유 |
|---|---|---|
| Q (Query) | 내가 지금 누구에게 관심/중요도를 줄 건가 | 나는 과자를 얼마나 필요로 하는가 |
| K (Key) | 다른 사람이 어떤 특성을 갖고 있는가 | 상대가 과자를 얼마나 중요하게 생각하는가 |
| V (Value) | 실제 반영될 값 | 실제로 받게 되는 과자 수 |
2) Attention 계산 과정 (단계별)
Step 1: Q × Kᵀ
A가 과자를 받을 때, A는 각 사람(B,C,D) 이 얼마나 중요한지 알아야 함
→ 그래서 A의 Q와 B,C,D의 K를 비교
A-Q × B-K = A가 B를 얼마나 중요하게 생각하는지 점수
A-Q × C-K = A가 C를 얼마나 중요하게 생각하는지 점수
A-Q × D-K = A가 D를 얼마나 중요하게 생각하는지 점수이게 dot product (점수 계산)
즉, QKᵀ는 “상대방에 대한 관심도 점수표”를 만든다고 보면 됨
Step 2: softmax
dot-product 점수는 아무 숫자나 나올 수 있음
-
예) A가 각 사람에게 준 점수:
B=2.1, C=0.3, D=1.6이걸 비율로 바꿔야 과자 나눌 수 있음
→ softmax로 확률처럼 변환
B = 50%, C = 10%, D = 40%
softmax = 점수를 “과자 비율”로 바꾸는 과정
Step 3: Value(V) 반영하기
각 사람이 가진 실제 의미(Value)를 비율대로 합침
V의 초기 값은 단어 임베딩값임
- 예)
최종적으로 A는각 사람의 V 값: B=5, C=2, D=4 (실제 지식/정보) 비율: B 0.5, C 0.1, D 0.4
즉, A는 주변 사람들의 정보(V)를 중요도(softmax 비율)로 가중합한 결과를 얻음A_output = 0.5×5 + 0.1×2 + 0.4×4 = 4.3
변수 정리
QKᵀ = 누구에게 관심을 줄지 점수 계산
softmax = 점수를 비율로 바꿔줌
V = 실제 정보/내용
Output = 비율 × 값 = “중요도 조정된 결과”Self-Attention은 주변 단어들이 가진 정보를, 그 단어가 나에게 얼마나 중요한지에 따라
비율을 만들어서 가중 평균하는 방식임
3.2.2 Multi-Head Attention
- 하나의 Attention만 쓰면 모델이 문장 관계를 한 방향(한 관점)에서만 보게 되지만 Transformer는 Attention을 한 번만 계산하는 대신 여러 개(head)의 Attention을 병렬로 수행하고 결과를 합침
이를 통해 다양한 의미적 정보 포착가능하고 학습 안정성 및 generalization 향상되며 계산 비용 효율 유지가 가능함
- Multi-Head Attention이 Transformer에서 쓰이는 3곳
| 위치 | 이름 | 목적 |
|---|---|---|
| 1 | Encoder Self-Attention | 입력 문장 내부 관계 학습 |
| 2 | Decoder Masked Self-Attention | 생성 중 미래 단어 보지 않기 + 이전 문맥 유지 |
| 3 | Encoder-Decoder Attention | 입력 문장 정보(Encoder)와 생성 문장(Decoder) 연결 |
◆ 3.3 Position-wise Feed-Forward Networks
- Attention은 단어끼리 관계를 계산하는 단계라면 FFN은 그 다음에 각 단어 embedding 자체를 더 잘 가공하고 변환하는 단계임
단어 간 관계 파악(attention) → 단어 표현 자체 강화(FFN)
-
차원을 512 → 2048 → 512로 바꾸게 되는데 그 이유는 Attention을 거친 벡터는 문맥 정보가 섞였지만 표현력은 제한됨
-
그래서 모델은 FFN에서 차원을 넓혀 변환 후 다시 압축함
| 모델 요소 | 기능 |
|---|---|
| Self-Attention | 어느 단어가 중요한지 판단 |
| FFN | 각 단어 표현 자체를 더 표현력 있게 변환 |
◆ 3.4 Embeddings and Softmax
-
입력 단어(ID)를 512차원 벡터(embedding) 로 변환
-
Encoder와 Decoder가 같은 embedding weight 공유 → 파라미터 절약 + 의미 공간 통일
-
Embedding 값은 √512로 스케일링 → 값 범위 안정화 → 학습 더 잘됨
-
Decoder 마지막 출력은 Linear → Softmax를 거쳐
-
다음 단어 확률 분포를 예측함
◆ 3.5 Positional Encoding
-
Transformer는 순서 개념이 없기 때문에 단어 위치 정보를 embedding에 추가해야 함
-
그래서 sin/cos 패턴을 가진 위치 벡터(PE) 를 word embedding에 더함
-
PE는 고정된 값이며, 각 위치는 서로 다른 주파수로 인코딩됨
-
이 방식은 모델이 단어의 절대 위치 + 상대적 거리를 모두 학습할 수 있게 해줌
❖ 4. Why Self-Attention
Transformer가 RNN이나 CNN 대신 Self-Attention을 선택한 이유는 3가지임
- 1) 연산 속도와 병렬화 (Parallelization)
- RNN은 입력 순서대로 처리해야 해서 병렬 불가능하여 느리고 CNN은 병렬화는 가능하지만 멀리 떨어진 단어 관계 학습이 어려움
→ Self-Attention은 모든 단어를 한 번에 처리가 되어 완전 병렬화가 가능함
- RNN은 입력 순서대로 처리해야 해서 병렬 불가능하여 느리고 CNN은 병렬화는 가능하지만 멀리 떨어진 단어 관계 학습이 어려움
-
2) Long-range dependency (장거리 의존성 학습 능력)
- 자연어에서는 멀리 떨어진 단어끼리 의미적으로 연결되는데 RNN은 이런 관계를 학습하려면 여러 단계 거쳐야 하고 정보 희석되고 CNN도 여러 층 필요함
→ Self-Attention은 어느 단어든 한 단계 안에 바로 연결되기 때문에 장거리 문맥 이해에 매우 강함
- 자연어에서는 멀리 떨어진 단어끼리 의미적으로 연결되는데 RNN은 이런 관계를 학습하려면 여러 단계 거쳐야 하고 정보 희석되고 CNN도 여러 층 필요함
-
3) 연산 비용 효율성 (Complexity vs Sequence Length)
- RNN, CNN에 비하여 연산 효율성이 좋음
→ 특히 sequence 길이가 길수록 Self-Attention가 효율적인 모습을 보임
- RNN, CNN에 비하여 연산 효율성이 좋음
❖ 5. Training
◆ 5.1 Training Data and Batching
-
데이터: WMT14 EN-DE(450만 문장), EN-FR(3600만 문장)
-
토크나이징: BPE(Byte-Pair Encoding)
-
배치 구성: 문장 길이 비슷하게 묶음 → padding 낭비 감소
-
배치 크기: 약 25k source + 25k target tokens
◆ 5.2 Hardware and Schedule
-
환경: NVIDIA P100 × 8 GPU
-
Base 모델: 100k steps (~12 hrs)
-
Big 모델: 300k steps (~3.5 days)
◆ 5.3 Optimizer
-
Optimizer: Adam
- β1=0.9, β2=0.98, ε=1e−9
-
학습률 스케줄:
- 초기: Warmup 4000 steps → 점진적 증가
- 이후: step^-0.5 감소
→ 안정적 학습 + 빠른 적응
◆ 5.4 Regularization
-
Residual dropout (p=0.1) → attention/FFN 출력에 적용
-
Embedding + positional encoding dropout
-
Label smoothing (ε=0.1) → 모델 확신 ↓, BLEU ↑
-
결과 (성능 비교)
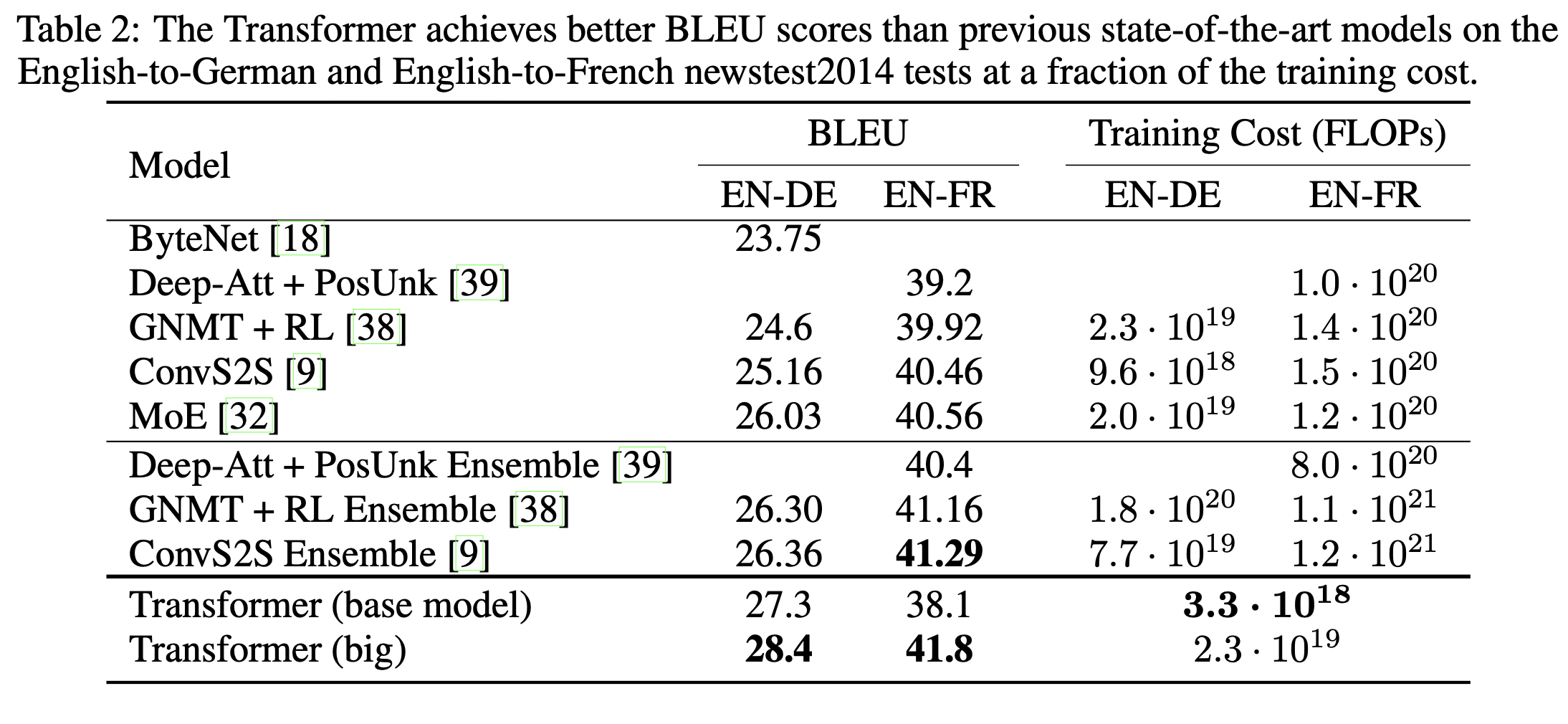
-
Transformer(Base): 27.3 (EN-DE), 38.1 (EN-FR)
-
Transformer(Big): 28.4 (EN-DE), 41.8 (EN-FR)
→ 기존 RNN/CNN 기반 모델보다 더 높은 BLEU + 더 적은 계산비용
❖ 6. Results
◆ 6.1 Machine Translation
-
Transformer(Big)은 WMT14 EN→DE 기준 BLEU +2.0 이상 개선함
-
Training 비용은 기존 SOTA 모델 대비 더 적은 FLOPs로 더 좋은 성능을 보임
-
EN→FR에서도 Transformer(Big)가 최고의 BLEU 성능 달성함
-
Label smoothing(ε=0.1)이 성능 향상에 효과적임
◆ 6.2 Model Variations
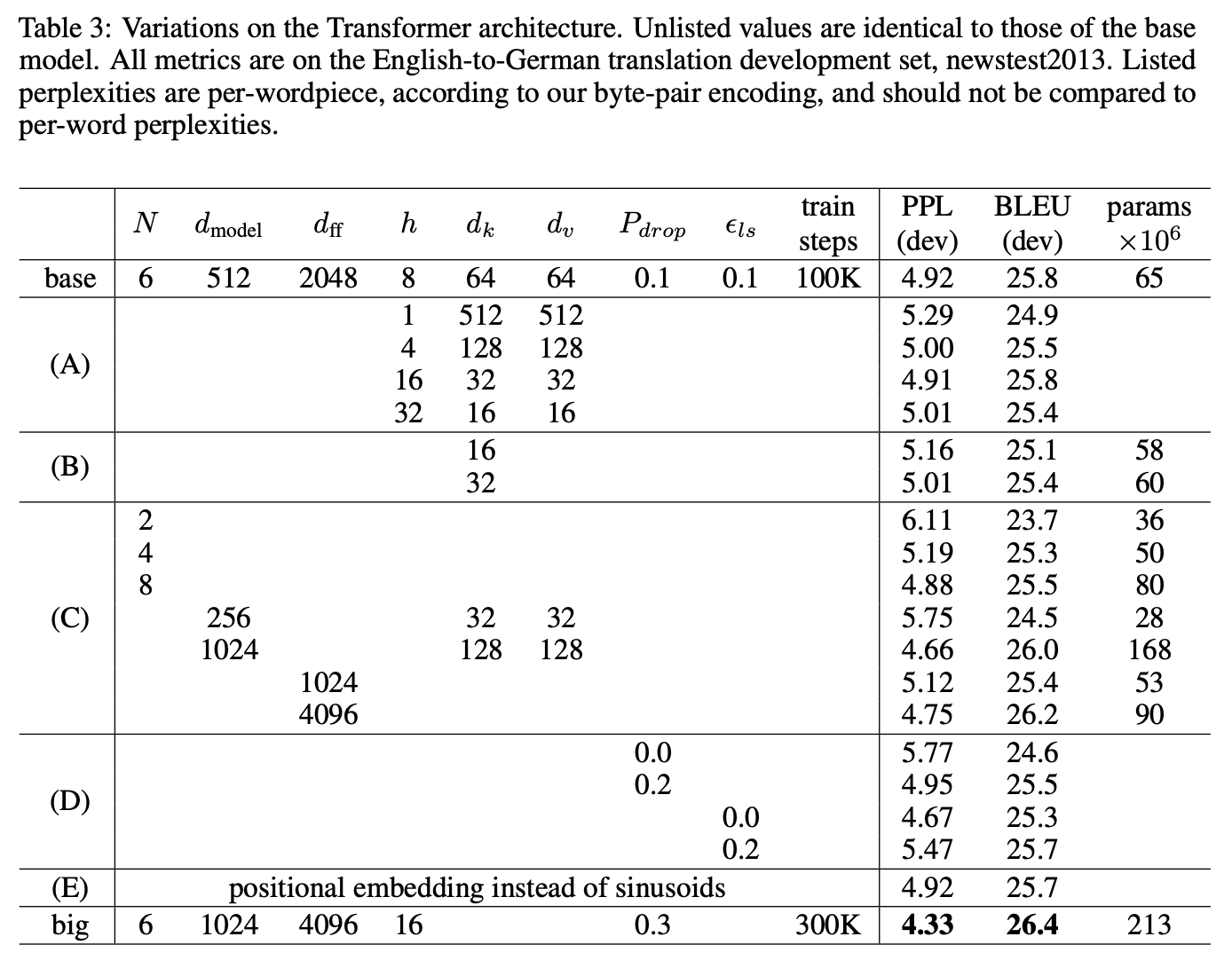
| 변경 요소 | 결과 |
|---|---|
| Head 수 변화 (A) | single-head는 성능 저하 → Multi-head 필수 |
| Attention dimension 감소 (B) | dₖ나 dᵥ 줄이면 성능 감소 → 충분한 차원 필요 |
| 모델 크기 증가 (C) | 더 큰 모델이 더 좋은 성능 |
| Dropout/Label smoothing 조정 (D) | 너무 적거나 많으면 성능 저하 → 적정값 존재 |
| Positional embedding 교체 (E) | 학습형 positional encoding ≈ sin/cos → 거의 동일 |
→ 모델 크기 증가 + 적절한 dropout + multi-head 구조가 최적
◆ 6.3 English Constituency Parsing
- 번역 외 task에서도 Transformer가 RNN-based parsing 모델들과 경쟁 가능한 결과 기록하였고 Semi-supervised setting에서는 기존 최고 모델과 거의 동일하거나 더 좋은 성능을, Task-specific tuning 없이도 높은 generalization 성능을 보임
❖ 7. Conclusion
Transformer는 RNN이나 CNN 없이, 오직 Self-Attention만 사용하는 최초의 Seq2Seq 모델아며 번역 작업에서 학습 속도는 훨씬 빠르면서도 기존 SOTA 모델보다 더 높은 BLEU 성능을 기록하였으며 구조적 단순함 + 높은 성능 덕분에 다른 task(텍스트 외 이미지·오디오·비디오 등)로 확장 가능성 높음
❖ 논문 후기
-
요즘 나오는 챗봇 AI들을 보면 정말 놀라울 정도의 성능을 보여주는데 사실 그 시작점이 바로 이 논문이라고 해도 과언이 아니라고 생각함
-
물론 최근 발표되는 모델들은 훨씬 복잡하고 뛰어난 성능을 내지만 결국 그 모든 발전의 기반에는 Transformer 구조가 존재하며 이 논문이 그 출발점이라는 생각을 하게 됨
-
추천 시스템을 공부할 때도 초창기 논문부터 흐름을 따라가며 읽었듯이 LLM과 Agent 분야도 이렇게 기초부터 차근차근 읽어가면 앞으로 최신 연구를 이해할 때 훨씬 수월해질 거라고 느꼈음
-
대학원 준비 과정에서도 이 흐름을 이해하고 있다는 점이 큰 장점이 될 것 같아서 이번 논문을 시작점으로 앞으로 관련 논문들을 꾸준히 이어서 읽어볼 계획임
논문 만족도 : ⭐️⭐️⭐️⭐️ (self attention이란 개념의 등장이 얼마나 대단한지 체감)
논문 이해도 : ⭐️⭐️⭐️⭐️ (대학 강의에서도 들었었고 이해하기 쉽게 정리도 같이 해서 잘됨)
LLM 관심도 : ⭐️⭐️⭐️⭐️ (추천시스템과 LLM 두개를 가장 관심있게 공부할 계획)
