❖ 논문 선정 이유
이전에 S³-Rec을 분석하면서 self-supervised 학습이 추천 시스템에서 얼마나 강력한지 알게되었고, 자연스럽게 후속 연구들이 어떤 방향으로 확장되는지 궁금해졌음
그러다 contrastive learning을 시퀀스 추천에 직접 적용한 CL4SRec을 확인하게 되었고, 기존 한계를 어떻게 개선했는지 살펴보고자 본 논문을 선정함
❖1.Introduction
◆ 핵심 문제
- Sequential Recommendation(순차 추천)는 사용자의 과거 행동 시퀀스를 보고 다음 아이템을 예측하는 방식인데, 기존 모델들은 보통 supervised learning만 사용함
→ 문제는 사용자 행동이 sparse함 레이블(y)이 부족하고 모델 파라미터는 많아서 과적합되기 쉬워서 high-quality representation을 학습하기 어려움
◆ 핵심 해결 아이디어
CL4SRec은 self-supervised learning(자기지도학습) + contrastive learning(대조학습) 을 시퀀스 추천에 활용하는 최초의 시도임
- 한 사용자의 시퀀스를 augmentation 해서 서로 다른 view를 뽑고, 이 view들이 같은 사용자에서 나왔다면 representation을 가깝게 만들어서 레이블 없이도 representation 품질이 좋아지게 함
❖ 2.Related Work
◆ 2.1 Sequential Recommendation
-
초기: Markov Chain 기반
→ 바로 다음 행동만 고려하여 성능이 낮음 -
중기: RNN, LSTM, GRU 기반
→ 시퀀스 전반을 고려하지만 long-term dependency 한계 -
최근(2021 기준) : Transformer 기반 SASRec 등장
→ self-attention으로 중요한 아이템들에 집중
→ SOTA 달성 -
또 다른 라인: GNN 기반 모델
→ 그래프 구조에서 이웃 정보를 활용하나
→ computational cost 큼 + 복잡함 증가
하지만 여전히 문제는 레이블 부족 + sparse
◆ 2.2 Self-supervised Learning
- Self-supervised 는 크게 두 가지 스타일이 있음
1) Prediction-style task
-
Masked prediction(BERT)
→ 시퀀스 일부 토큰을 [MASK]로 가리고, 모델이 가려진 원래 아이템을 맞히도록 학습시키는 방식 -
Rotation prediction
→ 시퀀스를 임의로 회전(shift)시켜 순서를 섞어놓고, 모델이 원래의 올바른 시작 위치를 맞히도록 학습시키는 방식. -
Jigsaw puzzle
→ 데이터를 변형하고 원래를 맞추는 방식
2) Contrastive learning
- SimCLR
→ 같은 데이터에서 만든 두 개의 증강 뷰는 가깝게, 다른 데이터는 멀게 학습시키는 가장 기본적인 대조학습 프레임워크 - MoCo
→ 대규모 음성(negative) 샘플을 안정적으로 유지하기 위해 ‘모멘텀 큐’를 사용해 더 일관된 대조학습을 가능하게 한 방식 - 두 view가 같으면 가깝게, 다르면 멀게하는 방식이 추천 시스템에서도 중요해지고 있지만, 기존 연구들은 item-level augmentation이 많고 sequence-level self-supervised는 거의 없음
여기서 CL4SRec이 등장하여 sequence-level contrastive를 최초로 제안함
- 저번 논문에서 리뷰한 S³-Rec 은 sequence-level prediction-style SSL이 메인이고, 일부 alignment loss가 contrastive 느낌을 포함한 하이브리드 방식이여서 contrastive 모델이라기보다는 prediction-style 중심 모델
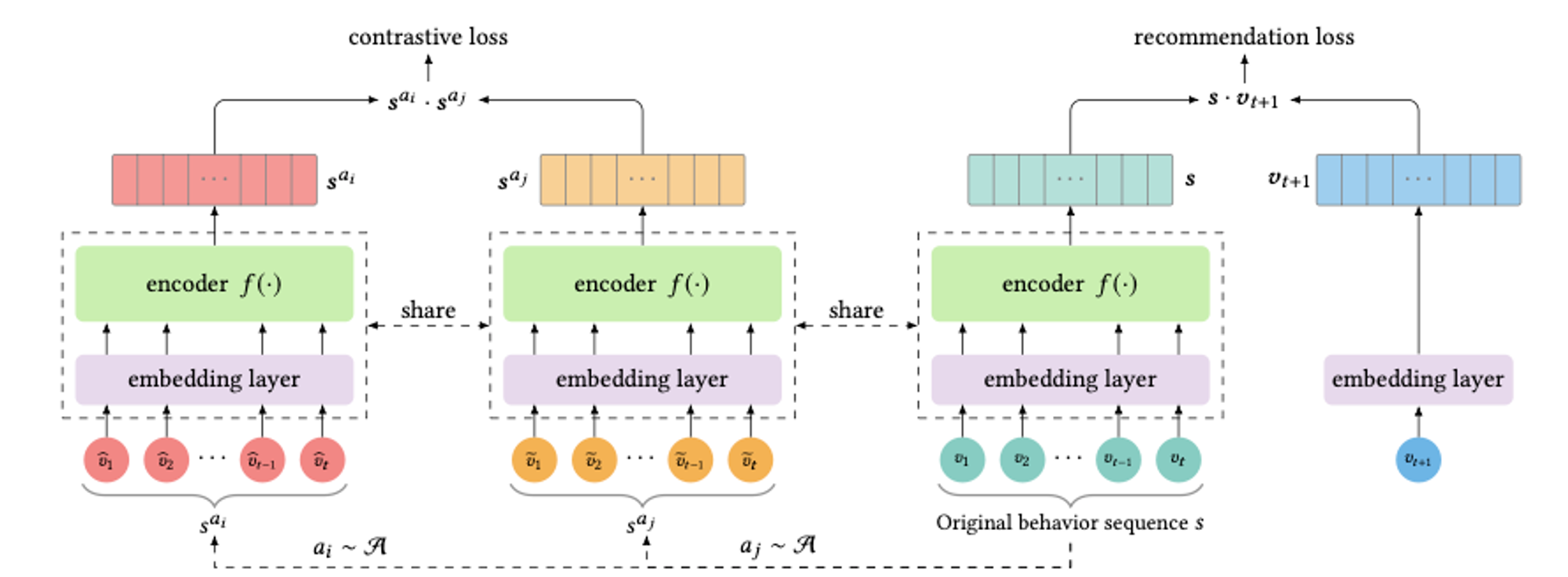
❖ 3. CL4SRec
- CL4SRec은 다음 4가지 요소로 구성됨:
◆ 3.1 Notations and Problem Satement
- 사용자 시퀀스 :
- 예측해야 할 것 :
- 즉 다음 클릭/구매 아이템 예측 문제
◆ 3.2 Contrastive Learning Framework
- 모델은 3부분으로 구성됨:
3.2.1 Augmentation Module
-
사용자의 시퀀스를 3가지 방식으로 랜덤하게 변형시켜 두 개의 correlated views 생성함
(1) Item Crop
시퀀스 일부 구간만 남기기
→ 지역적인 취향 정보 캡처(2) Item Mask
token을 [MASK]로 가리기
→ BERT의 masked LM과 유사한 효과(3) Item Reorder
아이템 순서를 일부 섞기
→ 시퀀스 순서가 조금 바뀌어도 취향은 동일하다는 가정 -
두 개의 augmentation(ai, aj)을 적용하여 두 개의 view를 생성함
3.2.2 User Representation Encoder
- Transformer encoder(SASRec 구조)를 그대로 차용하여 augmentation된 시퀀스를 임베딩
→ SASRec(2018)은 Transformer의 self-attention을 추천 시스템에 적용한 최초의 모델
3.2.3 Contrastive Loss
- 같은 사용자의 두 view는 가깝게 다른 사용자의 view는 멀게하는 것이 목적
SimCLR loss :
수식 설명
-
contrastive learning에서 사용하는 loss 값
-
이 값을 최소화하는 방향으로 학습이 이뤄짐
-
→ 같은 user u의 시퀀스에 서로 다른 augmentation 를 적용한 두 개의 view
- 두 벡터 사이의 유사도를 재는 함수이며 보통 코사인 유사도를 많이 쓰며 유사도가 클수록 두 representation이 비슷하다 봄
(temperature)
- softmax에서 분포를 얼마나 뾰족하게 만들지 조절하는 스칼라이며 작을수록 유사도 차이가 크게 반영되고 클수록 유사도 차이를 완만하게 봄
- 현재 우리가 관심있는 positive 쌍 의 similarity를 먼저 계산
- 그 값을 로 나누고 다시 exp를 취함
- softmax에서 이 쌍이 선택될 확률의 분자 역할을 함
- 두 view의 임베딩이 비슷할수록(sim이 클수록) 분자가 커짐 → 확률이 커짐 → loss가 작아짐
- 그래서 모델이 같은 유저의 augmentation된 시퀀스들은 서로 더 비슷하게 만들도록 학습하게 됨
- 첫 번째 합: 같은 anchor에 대해 고려하는 모든 positive 쌍들
- 두 번째 합: anchor와 negative 후보들(다른 user/sequence) 사이의 similarity들
- 즉, 분모 전체는 이 anchor와 관련된 모든 후보(positive + negative)를 대상으로 계산한 softmax의 분모라고 보면 됨
-
우리가 원하는 건 anchor와 진짜 positive 쌍이 선택될 확률이 최대화 하는 것인데 그 확률을 최대화하는 대신
→ 그 확률에 log를 취하고 마이너스를 붙여서그 값을 최소화하는 형태로 바꾼 것 -
그래서 학습이 진행되면서
→ positive 쌍의 similarity는 점점 커지게 만들고
→ negative 쌍의 similarity는 상대적으로 작아지도록 압박하는 구조가 됨
contrastive loss는 같은 유저 시퀀스에서 나온 두 augmentation view의 유사도가 모든 다른 시퀀스들과의 유사도보다 상대적으로 높아지도록 확률 형태로 강제하는 함수라고 보면 되며 CLS4Rec 성능의 핵심임
◆ 3.3 Data Augmentation Operators
-
CL4SRec의 핵심은 사용자 행동 시퀀스를 여러 다른 관점(view)으로 변환해 self-supervised 신호를 만듦
-
이를 위해 세 가지 증강 기법을 사용함
1) Item Crop (부분 시퀀스 자르기)
-
이미지에서 crop 하듯이, 사용자 시퀀스에서 연속된 일정 길이의 sub-sequence만 남기고 나머지를 버림
-
사용자의 최근 행동 패턴에 집중하게 해주며 두 개의 서로 다른 crop을 만들면, 상호 겹치지 않을 때는 다음 아이템 예측 같은 신호도 만들어짐
-
즉, 로컬한 관심사 + 다음 행동을 더 선명하게 학습하도록 만들기 때문에 representation 품질 향상에 도움됨
2) Item Mask (아이템 마스킹)
-
NLP에서 word dropout과 비슷하며 시퀀스에서 일정 비율(η)의 아이템을 골라 [mask] 토큰으로 대체함
-
사용자가 특정 제품을 구매하려는 의도는 전체 시퀀스에 균질하게 나타나므로, 일부 아이템이 mask 돼도 중심 관심사를 유지할 수 있음
-
서로 다른 masking 결과물 두 개를 만들면 같은 사용자 시퀀스에서 나온 두 view가 동일한 선호를 나타내도록 representation을 학습할 수 있음
3) Item Reorder (순서 뒤섞기)
-
원래 순서 기반 모델은 시퀀스의 순서를 강하게 신뢰하지만, 실제로는 클릭 순서가 뒤죽박죽일 수도 있고 여러 행동이 동시에 발생하기도 함
-
reorder 증강은 시퀀스 내 일부 구간을 랜덤하게 섞어서 순서에 대한 강한 의존도를 완화함
-
모델이 순서 노이즈에 덜 민감해지고, 시퀀스 전반의 맥락을 좀 더 유연하게 파악할 수 있게 됨
◆ 3.4 User Representation Model
-
CL4SRec은 SASRec과 동일한 Transformer Encoder 구조를 사용함
-
Transformer 기반 SASRec 구조:
- Embedding layer
- Multi-head self-attention
- Position-wise feed-forward
- Stacking blocks
- User representation = 마지막 타임스텝의 hidden state
◆ 3.5 Multi-task Training
-
CL4SRec의 최종 objective는
(1) 추천용 메인 loss (sequence prediction)
(2) contrastive learning loss (representation alignment) -
두 개를 함께 학습시키는 형태임
-
1) Main Loss (L_main)
- 다음 아이템 예측
- sample softmax 기반 NLL 사용
- 사용자 u가 t+1에서 선택한 긍정 아이템 v⁺와 랜덤으로 뽑은 negative 아이템 v⁻들의 score를 비교함
-
2) Contrastive Loss (L_CL)
- 같은 사용자 시퀀스에서 만든 두 증강 view(aᵢ, aⱼ)가 가까워지도록
- 다른 사용자 view들과는 멀어지도록 InfoNCE 형태 사용
-
최종적으로 λ는 두 loss 간의 trade-off를 조절하여 prediction과 representation 간 균형을 맞추게 됨
Main Loss는 정답 맞추는 것에 Contrastive Loss는 똑똑한 표현을 만드는 것에 집중하며
두 개가 결합되면서 CL4SRec은 단순한 ranking accuracy를 넘어 더 견고하고 일반화 능력이 높은 추천 모델을 만들게 됨
❖ 4.Experiments
-
Research Questions (RQ)
논문에서는 실험을 통해 아래 5가지 질문을 해결하려고 함-
RQ1. CL4SRec은 기존 state-of-the-art sequential recommendation 모델보다 성능이 좋은가?
-
RQ2. 서로 다른 augmentation 방식(크롭·마스크·리오더)이 성능에 어떤 영향을 주는가?
-
RQ3. contrastive loss의 가중치 λ 값이 multi-task 학습 프레임워크에서 어떤 영향을 주는가?
-
RQ4. CL4SRec의 구성 요소들(augmentation + contrastive learning)이 각각 성능 향상에 어떻게 기여하는가?
-
RQ5. CL4SRec은 실제로 다른 모델보다 “더 좋은 user sequence representation”을 학습하는가?
-
-
전체적으로 모델 구조 + augmentation 조합 + loss weighting이 성능에 어떤 영향을 주는지 다각도로 검증하는 구성임.
◆ 4.1 Experiments Settings
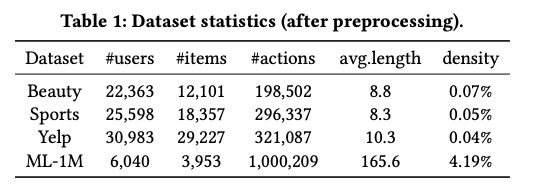
4.1.1 Datasets
- 총 4개 실제 데이터셋 사용: Beauty, Sports, Yelp, ML-1M
- 모든 interaction을 binary로 변환
- 중복 제거 뒤 시간순 정렬
- 5-core filtering 적용하여 sparse noise 제거
- 평균 시퀀스 길이는 Beauty/Sports/Yelp는 짧고 sparse, ML-1M은 길고 dense함
4.1.2 Evaluation
- Leave-one-out 전략 사용
- 마지막 item → test, 이전 item → validation
- Negative sampling은 사용하지 않고 전체 item을 대상으로 ranking
- Metric: HR@k, NDCG@k (k = 5,10,20)
4.1.3 Baselines
- Non-sequential: Pop, BPR-MF, NCF
- Sequential: GRU4Rec+, SASRec, GC-SAN, S³-RecMIP
- Embedding dim=64, Adam optimizer, early stopping 적용
◆ 4.2 Overall Performance Comparison(RQ1)
-
CL4SRec은 4개 데이터셋 모두에서 모든 SOTA baseline을 초과하는 성능을 보임
-
주요 결과:
- Sequential 모델(SASRec, GRU4Rec+) > Non-sequential 모델(BPR-MF, NCF)
- SASRec이 기존 baseline 중 최고이나 CL4SRec이 HR/NDCG 전 지표에서 뚜렷한 개선폭을 보임
- 특히 sparse 데이터셋(Beauty, Sports, Yelp)에서 향상폭이 큼
-
평균 개선:
- HR@5: +11.02%, HR@10: +9.69%
- NDCG@5: +5.52%, NDCG@10: +8.50%
→ Contrastive learning 기반 sequence augmentation이 state-of-the-art 이상의 성능을 제공함을 증명
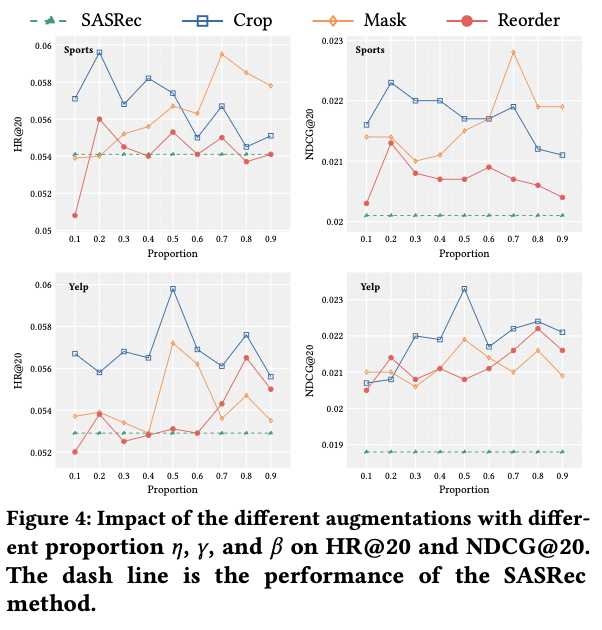
◆ 4.3 Comparison of Diifferent Augmentation Methods(RQ2)
- crop, mask, reorder 세 augmentation을 각각 적용하여 성능을 비교
-
결과 요약:
-
어떤 augmentation 방식도 대부분 SASRec보다 우수함
-
dataset마다 가장 효과적인 augmentation은 다름
Sports → Mask
Yelp → Crop -
augmentation 비율(0.1~0.9)에는 최적 구간이 존재
→ 너무 적으면 self-supervised 신호 부족
→ 너무 많으면 원본 변형이 커져 정보 손실 발생
→ 적절한 변형 수준이 contrastive learning 성능을 극대화함
-
◆ 4.4 Input of Contrastive Learning Loss(RQ3)
- contrastive loss 가중치 λ를 변경하며 성능 변화를 관찰
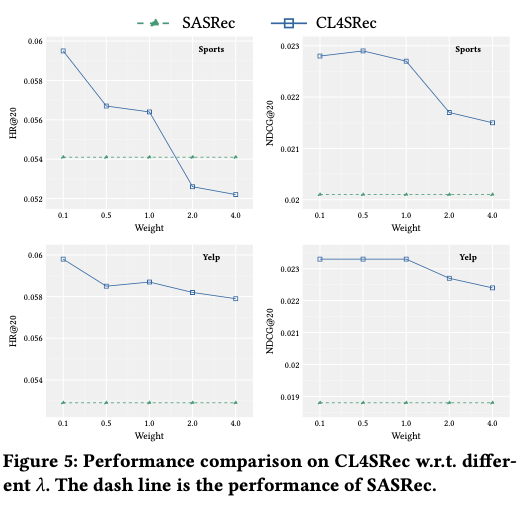
-
핵심 패턴:
- λ가 너무 크면 contrastive loss가 dominate되어 성능이 하락
- λ가 적당한 범위(0.1~1.0)일 때 SASRec 대비 안정적으로 우수한 성능
- λ가 커질수록 HR/NDCG는 감소 → sequence prediction을 해치는 trade-off 발생
-
Contrastive learning은 “적당히” 섞여야 효과적이며, representation quality와 prediction 사이의 밸런스가 중요함
◆ 4.5 Ablation Study(RQ4)
-
모델 비교:
- SASRec
- SASRec_aug (augmentation만 적용)
- CL4SRec (augmentation + contrastive)
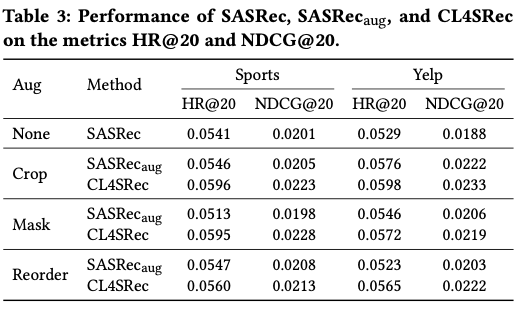
-
결론:
-
SASRec_aug > SASRec
→ augmentation만으로도 학습 generalization이 개선됨 -
CL4SRec > SASRec_aug
→ contrastive loss가 representation 품질을 크게 향상 -
Figure 6을 통해 CL4SRec embedding이 더 의미 있는 구조를 형성함을 시각적으로 확인
-
◆ 4.6 Quality of User Representation(RQ5)
-
Yelp의 “친구 관계(friend links)” 데이터를 이용해 latent space에서의 유저 유사도를 측정
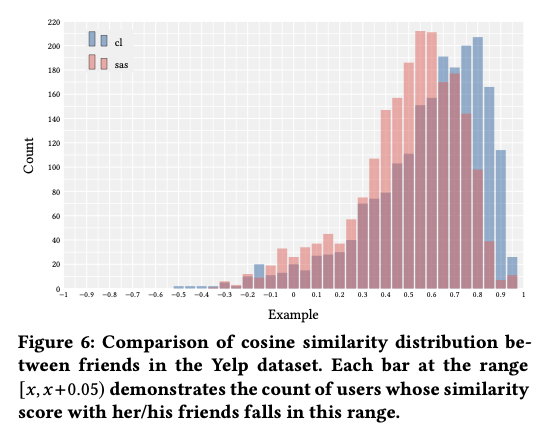
-
결과:
-
평균 cosine similarity
→ SASRec: 0.5198
→ CL4SRec: 0.6100 -
CL4SRec의 embedding은 비슷한 취향(친구 관계) 사용자끼리 더 가깝게 위치
-
학습 중 friend 정보는 사용하지 않았음에 embedding 구조가 더 semantic하게 형성됨
-
-
CL4SRec은 단순 추천 정확도뿐 아니라 user representation quality 자체가 개선됨
❖ 5.Conclusion and Future Work
-
본 논문에서는 Contrastive Learning for Sequential Recommendation (CL4SRec) 라는 새로운 모델을 제안하였으며 CL4SRec은 interaction 데이터만으로도 효과적인 사용자 표현 학습이 가능하도록 설계되었음
-
contrastive learning 프레임워크를 활용하여 추가 레이블 없이 raw sequence로부터 self-supervised 신호를 추출하고 crop, mask, reorder의 세 가지 data augmentation 전략을 제안을 함
-
네 개의 공개 데이터셋(Beauty, Sports, Yelp, ML-1M)에서의 실험 결과 CL4SRec은 기존 SOTA 모델들보다 일관적으로 우수한 성능을 보이며 contrastive learning이 sequential recommendation에서 매우 효과적임을 입증함
❖ 논문 후기
-
지난주에 리뷰했던 S³-Rec 논문에 이어, 이번에는 또 다른 추천시스템 관련 연구를 선택하여 리뷰하였음
-
BERT4Rec → S³-Rec → CL4SRec 으로 이어지는 흐름을 따라가며, 추천 모델이 어떻게 발전해 왔는지 살펴보니 새로운 모델을 제안할 때 어떤 관점에서 성능을 개선하려 하는지 점점 더 이해하게 되는 느낌이음
-
특히 이번 논문에서는 contrastive learning을 추천 시스템에 적용한다는 점이 가장 인상적이었는데 contrastive learning은 현재 다양한 영역에서 활용되는 핵심 기법이며 이를 sequential recommendation에 효과적으로 녹여낸 방식이 매우 흥미로웠음
-
그래서 이번 리뷰에서는 다른 논문들보다 관련 수식과 학습 구조를 좀 더 깊이 정리하는 데 집중하였는데 이유는 수식을 이해하는 것이 CL4SRec의 핵심이라고 판단했기 때문임
-
물론 2021년 논문이라 최신 연구는 아니지만, 당시 기준으로는 충분히 의미 있는 임팩트를 가진 연구라고 생각하며 앞으로도 최신 논문까지 연속적으로 리뷰하며, 추천 시스템 분야의 흐름을 계속 따라가 보고자 함
++ 그리고 추천뿐 아니라 다른 분야 논문도 가끔 탐색하며 시야를 넓히는 것도 좋을 것 같음!
논문 만족도 : ⭐️⭐️⭐️ (contrastive learning을 활용한 점이 인상깊었음)
논문 이해도 : ⭐️⭐️⭐️⭐️ (논문 핵심이라 생각한 수식을 자세히 리뷰하니 이해가 더 잘됨)
추천시스템 관심도 : ⭐️⭐️⭐️⭐️ (추천시스템은 현실 서비스에서 가장 큰 영향을 미치는 분야라 생각해서 관심이 많음)
