논문 링크 : https://arxiv.org/abs/2008.07873
❖ 논문 선정 이유
추천 시스템 관련 논문을 찾아보던 중, 이전에 리뷰했던 BERT4Rec의 단점(단방향 의존, 속성 활용 부족, 데이터 상관관계 미반영 등)을 보완한 모델로 평가되는 S3-Rec을 발견해, 해당 한계들을 실제로 어떻게 개선하는지 확인하고자 이 논문을 선택해 리뷰하게 됨
❖ 0. Abstract
◆ 논문 핵심 주제
BERT4Rec 이후의 시퀀스 추천 모델을 더 똑똑하게 만들기 위해 아이템 간 의미적 상관관계를 Self-Supervised Learning으로 학습시키는 것
❖ 1. Introduction
◆ 주요 문제 인식
-
기존 모델들은: “예측 성능”에만 집중해서 아이템 간 의미적 연결성(context correlation)을 반영 못 하고 데이터 희소성(data sparsity)에 매우 취약함
-
그래서 제안한 방법:
- S³-Rec (Self-Supervised Sequential Recommendation) 여러 auxiliary objective을 만들어 시퀀스 내 다양한 관계를 학습 Mutual Information Maximization(MIM) 원리를 적용해 추천의 품질을 높임
❖ 2. Related Work
◆ 2.1 Self-Supervised Learning for Recommendation
Self-supervised :
사람이 라벨링하지 않아도 데이터 내부의 규칙성을 학습하는 방식
(예: 문장에서 단어를 가려놓고 예측하기 = BERT의 Masked LM)
- S3-Rec은 이걸 추천 데이터에 적용하여 사용자의 행동 시퀀스 자체에서 내부 구조적 상관관계를 학습함
◆ 2.2 Mutual Information Maximization (MIM)
Mutual Information (MI) :
두 변수 X, Y가 얼마나 정보적으로 의존하는지를 나타내는 척도이며 쉽게 말해서 둘이 얼마나 관련 있는가를 수치로 표현한 것
- 이 논문에서는 MIM을 이용해 아이템–속성, 시퀀스–부분시퀀스 등의 관계를 강화하고 서로 다른 형태의 컨텍스트 간 correlation을 극대화 하여 더 일반화된 user-item representation을 얻게 됨
❖ 3. Preliminaries
◆ 3.1 Problem Statement
-
사용자 집합: 아이템 집합:
- 각각 사용자 , 아이템 로 표시
-
각 사용자는 시간 순서대로 아이템을 소비한 시퀀스 보유:
- (여기서 iₜ는 t번째로 본 아이템)
목표 : 주어진 사용자 시퀀스 {i₁, …, iₙ}을 보고, 다음 아이템 iₙ₊₁을 예측하는 것
- 추가적으로 각 아이템 i는 여러 속성(attributes)을 가짐:
- 𝒜ᵢ = {a₁, a₂, …, aₘ} (예: 음악 추천의 경우 — 아티스트, 앨범, 장르, 인기 등)
즉, 추천 문제는 시퀀스뿐 아니라 아이템의 속성 정보도 함께 고려해야 하는데 이게 바로 S3-Rec이 단순 BERT4Rec보다 강력한 이유임
◆ 3.2 Mutual Information Maximization
-
Mutual Information (MI)는 두 랜덤 변수 사이의 정보적 의존성을 나타냄
-
공식
- : 의 엔트로피(불확실성)
- : 를 알고 난 뒤 의 불확실성
- 가 클수록 두 변수는 강하게 연결되어 있음
InfoNCE (Practical MI Lower Bound)
-
MI는 직접 계산하기 어려워서, InfoNCE (Noise Contrastive Estimation)를 사용함
-
positive sample vs negative samples 구별하는 contrastive learning 형태임
-
공식 :
- : 같은 입력의 두 view (예: 아이템과 속성, 시퀀스와 부분시퀀스)
- : 두 representation의 similarity (예: dot product)
- : negative sample (다른 아이템 등)
- log term은 cross-entropy와 유사함
-
직관적으로는 같은 맥락의 view는 가깝게, 다른 맥락은 멀게 만드는 학습 방식
(BERT의 NSP나 CLIP의 contrastive 학습과 같은 원리)
S3-Rec에서 MI를 적용한 이유
→ S3-Rec은 시퀀스 내부의 다양한 view 간 관계를 학습하기 위해 MI를 사용하며 이는 모델이 내부 구조적 의미를 더 깊이 파악할 수 있기 때문
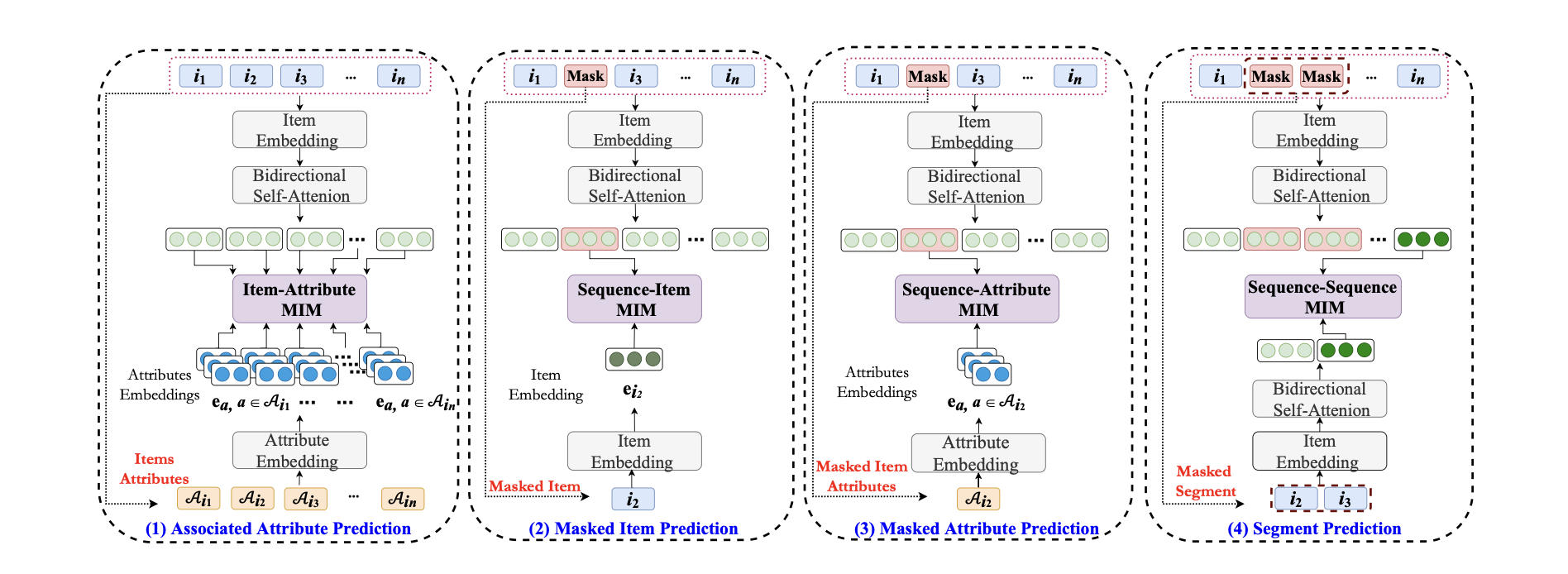
❖ 4. Approach
◆ 4.1 Overview
- 기존 시퀀스 추천은 아이템 레벨 한 가지 목적함수(다음아이템 예측)에만 집착
→ 데이터 희소성과 컨텍스트 결합 부족함
S3-Rec은 입력을 여러 뷰(view)로 쪼개서(속성·아이템·세그먼트·시퀀스) 뷰들 사이의 상호정보량(MI)을 InfoNCE로 키우는 여러 self-supervised 목적을 추가함
- 결국 프리트레인(양방향 Transformer) → 파인튜닝(단방향 Transformer) 두 단계
◆ 4.2 Base Model
4.2.1 Embedding Layer
-
두 임베딩 테이블을 둠:
- 아이템 임베딩:
- 속성 임베딩:
-
길이 n의 시퀀스 에 대해 룩업으로 아이템 임베딩 행렬 을 더해 입력 표현을 강화 :
-
각 아이템 에 속성 집합 가 있으므로 해당 속성 임베딩들을 합/평균해 아이템을 속성 표현 도 만듦
4.2.2 Self-Attention Block
-
레이어 의 입력을 라 하면 멀티헤드 어텐션:
-
포인트와이즈 FFN :
-
마스킹 규칙
- 프리트레인:BERT처럼 마스크 제거(양방향) → 각위치가 좌우 문맥을 모두 본 컨텍스트-어웨어 표현을 학습함
- 파인튜닝 : 좌 → 우 마스크(단방향)적용함
4.2.3 Prediction Layer
- 점수 계산
- 시간 의 시퀀스 컨텍스트 표현 과 후보 아이템 임베딩 의 점곱 :
- 시간 의 시퀀스 컨텍스트 표현 과 후보 아이템 임베딩 의 점곱 :
- 파인튜닝은 pairwise rank losss로 학습
◆ 4.3 Self-supervised Learning with MIM
-
S³-Rec은 Mutual Information Maximization (MIM) 을 이용해 서로 다른 view 간의 상호정보량(mutual information) 을 높이는 방식으로 self-supervised 학습을 진행함
-
기본 아이디어: item, attribute, sequence, subsequence 등 여러 수준(granularity)의 정보(view)들 간의 상관관계(correlation) 를 학습함
→ 데이터 표현력 강화 -
이 섹션에서는 4가지 상관관계를 각각의 self-supervised objective로 정의함:
- Item–Attribute (AAP)
- Sequence–Item (MIP)
- Sequence–Attribute (MAP)
- Sequence–Segment (SP)
4.3.1 Modeling Item–Attribute Correlation (AAP)
-
아이템과 그에 속한 속성(attribute) 간의 상호정보량을 극대화하고 속성이 아이템의 세부적 의미를 제공하므로 → item representation에 attribute-level 정보를 주입함
-
Loss Function
- : 아이템 임베딩
- : 속성 임베딩
- : 학습 가능한 변환 행렬
- : 시그모이드 함수
→ 실제 속성(positive)은 유사도 ↑, 다른 속성(negative)은 유사도 ↓
기존 추천 모델은 아이템의 콘텐츠 정보를 auxiliary feature로만 사용했지만 AAP은 그 정보를 representation 자체에 직접 주입(inject)하는 점이 차별점임
→ cold-start item에도 효과적
4.3.2 Modeling Sequence–Item Correlation (MIP)
-
시퀀스 내 아이템들 간 순차적 의존성(sequential dependency) 학습
→ BERT의 Masked Language Modeling과 유사한 아이디어 -
학습 방식
- 입력 시퀀스 중 일부 아이템을 [MASK]로 대체
- 마스크된 아이템을 주변 문맥(context)으로부터 복원
- S³-Rec은 BERT4Rec처럼 양방향(Bidirectional) 문맥 사용
-
Loss Function
- : 주변 문맥
- : Transformer가 추출한 문맥 백터
- : 학습 가능한 매개변수
기존 BERT4Rec은 MIP만 사용 → 시퀀스 내 의존성만 학습했지만 S³-Rec은 MIP 외에도 attribute/segment 관계까지 통합하여 multilevel representation을 구현함
4.3.3 Modeling Sequence–Attribute Correlation (MAP)
-
시퀀스 수준의 문맥이 아이템의 속성을 예측하도록 학습
→ 사용자 행동 패턴(시퀀스)과 아이템 속성(콘텐츠) 간의 정보를 극대화함 -
학습 방식
- 마스크된 아이템의 속성을 문맥(context)에서 복원
-
Loss Function
- : 마스크된 아이템 주변 문맥
- : 해당 아이템의 속성 집합
MAP은 시퀀스와 속성을 연결하여 콘텐츠–행동 융합 표현(fusion representation) 강화
4.3.4 Modeling Sequence–Segment Correlation (SP)
-
장기 의존성(long-term dependency) 학습이며 단일 아이템보다 큰 단위인 세그먼트(subsequence) 수준에서 문맥을 학습함
-
학습 방식
- 시퀀스 내 일부 구간(segment)을 마스크
- 주변 문맥을 사용해 세그먼트 복원
-
Loss Function
- : 실제 세그먼트
- : 세그먼트 주변 문맥
- : 세그먼트 representation (pooling 결과)
SP는 단기 행동보다 안정적 사용자 선호 패턴을 학습
SP 단독 제거 시 성능 하락은 작지만
→ MIP/MAP과 함께일 때 시너지 효과 큼
◆ 4.4 Learning and Discussion
Learning
- S³-Rec은 두 단계 학습 구조로 되어 있음:
Pre-training:
Bidirectional Transformer 사용하며 4가지 self-supervised loss (AAP, MIP, MAP, SP)를 동시에 학습해 item–attribute–sequence 관계를 익힘
Fine-tuning:
Unidirectional Transformer로 전환하여 Pre-trained 파라미터로 초기화 후, 다음 아이템 예측을 위한 pairwise ranking loss로 학습함
-
Parieise ranking Loss:
- : 정답 아이템 점수
- : negative sample 점수
- 둘의 차이를 sigmoid에 넣어 확률화 → 랭킹 비교 구조
-
프리트레인으로 표현력 확보 → 파인튜닝으로 순차 예측 적합화 구조
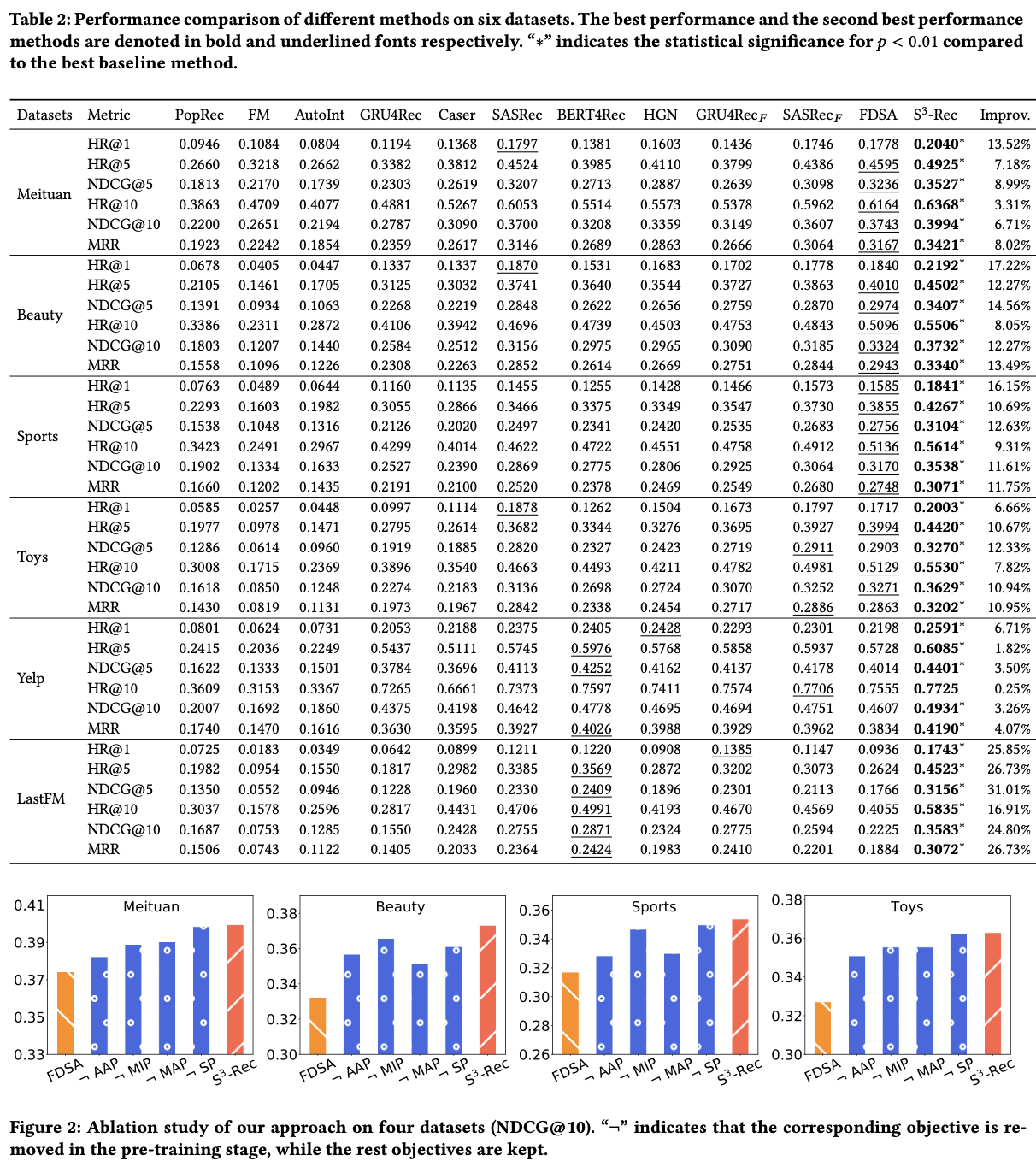
❖ 5. Experiment
5.1 Experimental Setup
-
Dataset : 6개의 실제(real-world) 데이터셋 사용:
- Meituan: 중국 음식 리뷰 플랫폼 (6년치 거래 데이터, 카테고리 = 속성)
- Amazon Beauty / Sports / Toys: Amazon 세부 카테고리 3개, 상품의 세부 속성 사용
- Yelp: 비즈니스 리뷰 데이터, 카테고리 정보를 속성으로 처리
- LastFM: 음악 추천용, artist 태그를 속성으로 사용

→ 공통적으로 속성(attribute) 을 아이템의 보조 정보로 사용하며, 상호작용 기록이 5회 미만인 유저는 제거함
-
Evaluation Metrics
- HR@10, NDCG@10, MRR
- Leave-one-out 방식 (마지막 아이템으로 테스트)
- 99개의 negative item과 1개의 positive item으로 평가함
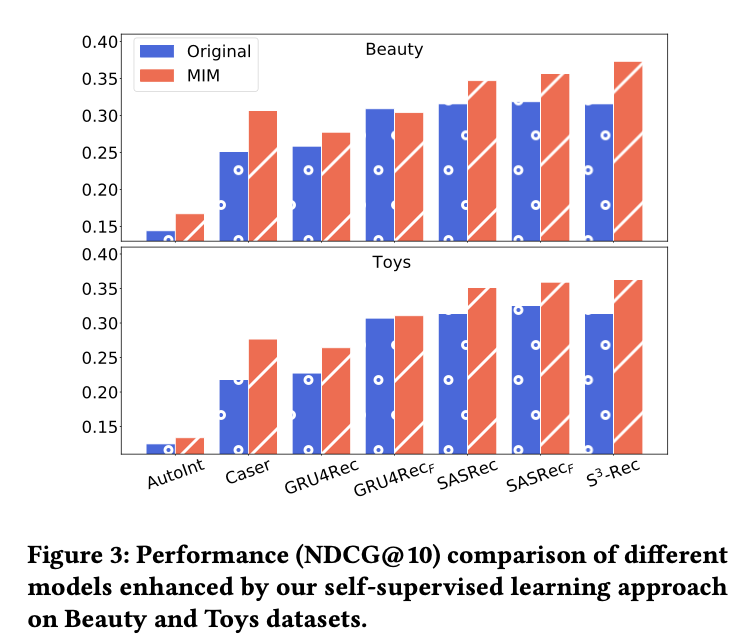
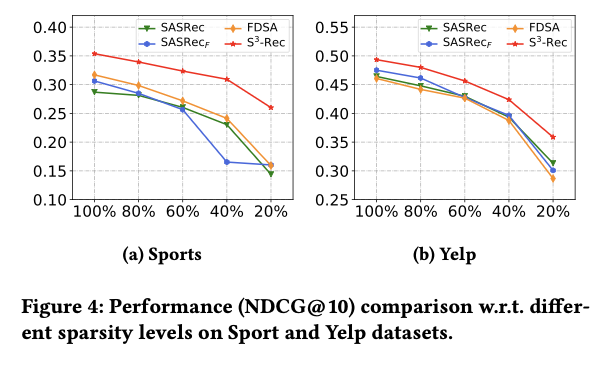
5.2 Experimental Results
-
S³-Rec은 6개 데이터셋 전부에서 모든 baseline보다 높은 성능을 달성함
-
평균 NDCG@10 기준 9~18% 향상
-
특히 Beauty Toys에서 현저한 개선
❖ 6. Conclusion
- S³-Rec은 Mutual Information Maximization (MIM) 원리에 기반한 Self-supervised Sequential Recommendation 모델임
- 핵심 아이디어는 item, attribute, segment, sequence 간의 다양한 상호관계(multi-view correlation) 를 4가지 self-supervised objective(AAP, MIP, MAP, SP)을 통해 학습하는 것
- 이를 통해 sequence representation 품질을 강화하고, 여러 strong baseline 모델(FDSA, SASRec, BERT4Rec 등)보다 모든 데이터셋에서 더 높은 성능을 달성함
❖ 논문 후기
-
BERT4Rec 논문을 읽은 뒤로 추천 시스템 분야에 더 흥미가 생겨, 이번에는 그 한계를 보완해 더 강력한 구조를 제시한 S3-Rec을 읽어보았는데 과연 기존 모델의 약점을 어떻게 개선했는지 보는 과정이 꽤 재미있었고, ‘추천’이라는 분야가 왜 매력적인지 다시 느낄 수 있었음
-
물론 이 논문도 발표된 지 시간이 지나 지금은 더 뛰어난 모델들이 많이 나와 있지만, 대학원을 준비하는 입장에서는 예전 모델부터 차근차근 읽으며 추천 시스템이 어떻게 발전해 왔는지 흐름을 따라가는 게 더 의미 있다고 생각하고 흥미로운 점은 추천 모델들이 상당히 많은 부분을 언어모델에서 차용하고 있다는 점인데, 덕분에 이런 논문을 읽으며 자연스럽게 NLP 모델의 발전도 함께 공부할 수 있었음
-
물론 논문의 전체적인 흐름과 아이디어는 이해했지만, 직접 코드를 구현해보거나 모든 수식을 완전히 소화하지는 못한 점은 조금 아쉬움으로 남았음
-
앞으로도 모델들과 딥러닝의 발전 단계를 하나씩 따라가며, 추천 시스템이라는 분야를 더 깊게 이해해 보고 싶음
논문 만족도 : ⭐️⭐️⭐️
논문 이해도 : ⭐️⭐️
추천시스템 관심도 : ⭐️⭐️⭐️⭐️

추천 연구실 들어갑시다!