Introduction to NLP
NLP
본 내용은 2012년에 강의된 'Natural Language Processing with Dan Jurafsky and Chirs Manning, 2012'의 내용을 다룹니다.
Introduction to NLP
Applications of NLP
- Question Answering
- Information Extraction
- Sentiment Analysis
- Machine Translation
Fully automatic!
Language Technology
아래 그림은 언어 분야에서의 현황을 나타냅니다(2012년 기준).

알다시피, 9년이 지난 2021년에는 어느 정도 상당한 수준의 정확도를 보이고 있는 태스크들입니다.
NLP는 왜 어려울까?
- ambiguity problemd(crash blossoms)
- 문법적으로 해석이 애매할 수 있다(주어-동사,....
- 또한, 단어적으로 해석이 애매할 수 있다.

아래에서는 phrase structure에 대한 그림이다.

아무튼, 이해하기 쉽지 않다는 것.
또한, 아래와 같은 다양한 이유가 있다.
- 비문이 많다.
- 어떤 방식으로 단어를 구분할 지 애매 모호하다.
- 숙어, 영어제목, 신조어 등 또한 이해하기 힘들다.
이런 해결을 위해 필요한 것은 아래와 같다.
- 언어에 대한 이해
- 세상에 대한 이해
- 지식들을 통합하는 방법에 대한 고려
일반적으로는, 아래와 같이 확률적 언어 모델링을 통해 자연어처리를 주로 접한다.

일종의 Approximate job이라 할 수 있다.
이론적
1. 통계적 자연어 처리를 위한 핵심 이론 & 방법
2. 나이브 베이즈 / Maxent Classificir
3. N-gram language model
4. Statistical parsing
5. Inverted index, tf-idf, vector models
Practical
- Information extraction
- Spelling correction
- Information retrieval
- Sentiment analysis
2. Basic Text Processing
Regular Expression(정규 표현식)
- Regular Expression은 text strings를 다루는 형식적인 언어이다.
- 가령, 아래와 같은 단어를 보자.

위와 같이 여러 방식으로 표현될 수 있는 단어를 통일할 수 있는 방법은 여러 가지가 존재한다.
disjuction
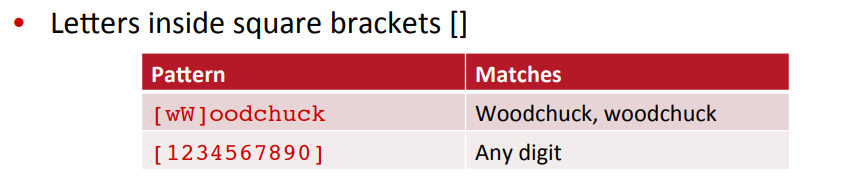
Negation in disjuction
- 위와 같이 정규 표현식을 줄 수도 있고, 반대로 원하지 않는 문자들은 제외시킬 수도 있다.
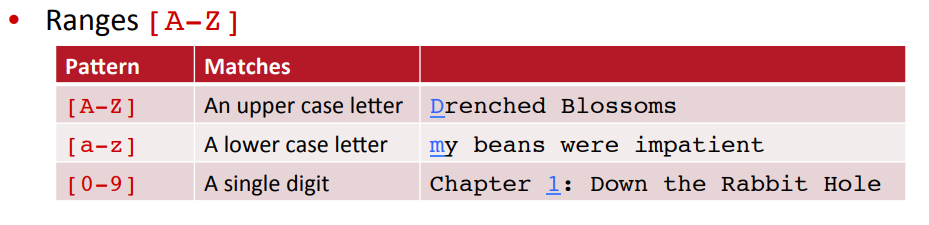
즉
- [^A-Z] : 모든 알파벳 제외
- [^Ss] : S, s 제외, ... 가 되는 것
More Disjuction
Pipe
- Pipe는 기호 |를 나타낸다.
 ㅇㅇㅇㅇㅇㅇㅇㅌㅌ
ㅇㅇㅇㅇㅇㅇㅇㅌㅌ
? * + .

- ? : 이전 문자에 대해 존재 유/무를 모두 다룬다.
- : 이전 문자에 대해 0~N개가 반복되는 요소를 모두 다룬다.
- : 이전 문자에 대해 1~N개가 반복되는 요소를 모두 다룬다.
- . : 어떠한 문자가 와도 괜찮다.
^ $
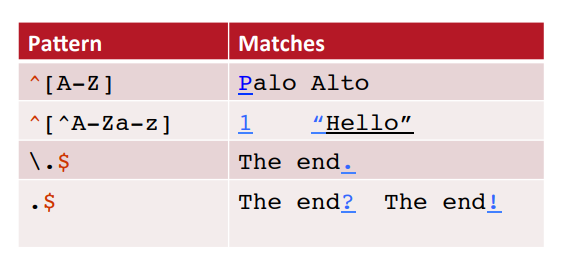
- ^ : 줄(문장)의 맨 첫번째 문자에 대한 조건식
- $ : 줄의 맨
- . : 어떠한 문자도 와도 괜찮았다. (단, 온점의 의미로 쓰고싶으면 backslash로 escape해준다).
Errors
- 정규 표현식은 경우의 수가 너무나도 많기 때문에, 구체적으로 정해주어야 한다.
가령, 'The'를 찾으려면 아래와 같이 표현해준다.

이런 과정은 일반적으로 1종 오류(False positive)와 2종 오류(False negative)를 고치는 방향으로 진행한다.
즉, 1종 오류는 너무 많은 결과값들을 반환할 때 높게 나타나며, 2종 오류는 너무 적은 결과 값들을 반환할 때 높아진다.
이런 부분들은 precision을 높혀 False positive를 낮추고, coverage(recall)을 높혀 False Negative를 낮추는 방향으로 진행하게 된다.
요약하면, 텍스트 전처리에서의 정규표현식은 너무나도 중요하고, 심플한 방법이다.
특히, 후에 머신러닝을 사용하더라도 정규표현식을 이용해 뽑아낸 Feature들이 유용하게 쓰일 수 있다.
3. Regular expressions in practical NLP
NLP 분야에서는, 수 많은 확률 모델링 방법들이 존재합니다. 다만, 실제로 깊게 들어가보면 결국 다양한 형태의 정규 표현식을 볼 수 있습니다.
다양한 태스크에 대해 정규 표현식은 굉장히 효율적이고, 다양한 패턴을 다루기에 적합한 것을 알 수 있습니다.
여기서는 Power Zone, Part-Of-Speech Tagger, coreNLP 등 NLP 안에서 정규표현식 툴들이 어떻게 쓰이는 지를 살펴보겠습니다.
JFlex
- Large Deterministic regular expression.
- 일종의 lexers(tokenizers).
- sequence를 받아 token 단위로 쪼개서 표현.
- 즉, Unix의 Lex part와 Flex part가 존재한다.
- 이 때 java와 혼용되는 버전이기 때문에 JFlex라고 부르는 것.

- 핸드폰 번호 등에 대한 표현식을 볼 수 있다(국가 코드 등).
4. Word Tokenization
-
텍스트 전처리에서 중요한 과정.
-
NLP에서 대부분의 데이터는 아래와 같은 과정을 거쳐야 한다.

이 중 가장 대표적인 Tokenization에 대해 다루어 보자.
실질적으로 문장들에는 다양한 단어가 존재한다.
- Fragments(혹은 filled pauses) - 늘임표.
- Lemma - 단수 복수, ...

아래의 예시 문장에 단어가 몇 개 있는 지 세어보자.
'they lay back on the San Francisco grass and looked at the strats and thier`
세는 방법에 따라 다르지만, 여기서는 Type과 Token으로 따져보자.
- Type : 얼마나 많은 (unique한)단어가 있는지.
- Word token : 특별한 타입을 갖는 instance들이 얼마나 있는지.
- 15개(San Fransico를 2개로 세면).
they와 their는 같은 lemman이다.
$N, V4를 아래와 같이 정의하자.
데이터 셋 안에는 얼마나 많은 단어(그리고 토큰)가 있을까?
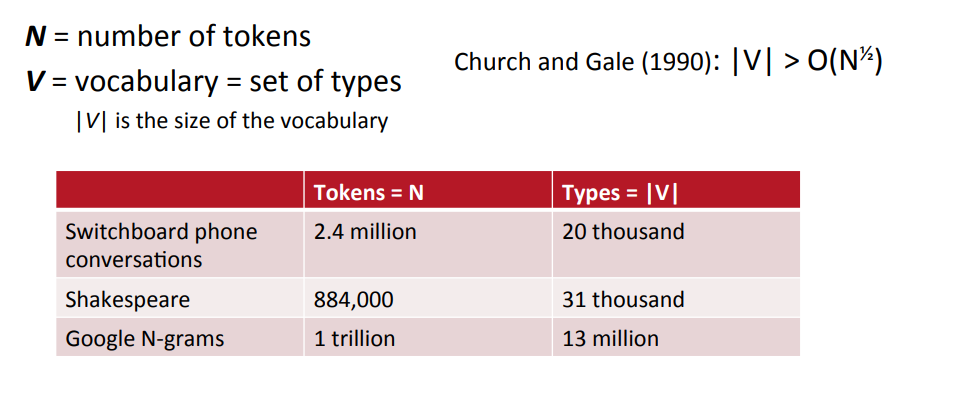
- 1990년에 CHurce와 Gale은 아래와 같이 token의 개수와 단어의 개수 간의 관계를 위와 같이 정의했다.
Issues in Tokenization

- 위와 같이 따옴표('), 하이픈(-), 온점(.) 등에 대한 요소를 고려할 수 있다.

- 또한, 프랑스어 / 독일어 / 중국어 / 일본어 등도 특징을 가지기 때문에 각기 다른 방식으로 다룰 필요가 있다.

- 특히, 일본도 띄어쓰기가 없으며, 여러 문자가 같이 섞여있다.
- (가타카나, 히라가나, 칸지, 로마지 등)

- 특히, 중국은 하나의 문자가 하나의 음절과 하나의 형태소를 가진다.
- 즉, 하나의 단어는 보통 2~3개의 문자로 쪼개서 사용해야 한다.
- 그렇기 때문에 많은 연구가 이루어져야 하는데, 일반적으로 Max-match 알고리즘을 베이스라인으로 사용하곤 한다(greedy algorithm).
아무튼, 모두 tokenizing을 진행할 때 정교한 접근법을 취할 필요가 있다.
Maximum Matching Word Segmentation Algorithm
- 첫 pointer에서 시작해 주어진 string과 가장 길게 일치하는 단어를 찾는다.
- 그 다음 단어로 넘어가 다시 가장 길게 일치하는 단어를 찾는다.
영어로 생각해보자.
*'thecatinthehat`
- The
- cat
- in
- the
- hat
'thetabledownhere'
- Theta (변수의 일종)
- bled
- own
- there..
theta bled own there..?
즉, 영어에서는 잘 작동하지 않는다.
영어는 매우 긴 단어와 매우 짧은 단어가 혼용돼서 사용되기 때문이다.
그래도, 중국어에서는 일반적으로 단어 길이가 비슷비슷하기 때문에 잘 작동한다고 볼 수 있다.
5. Normalization

-
word를 segment(혹은 tokenize)한 후에는 토큰들을 정규화(Normalize)해야 한다.
-
normalize는 일종의 Information retrieval을 위한 태스크라고 볼 수 있다.
-
가령, U.S.A.는 USA와 매치되어야 한다.
이런 방법에는 구두점(period, '.')을 없앤다든가, 아니면 비슷한 단어들을 정의할 수도 있지만, 때로는 잘못된 결과를 낳을 수도 있다(asymmetric expansion).
복잡하기도 하지만.
그래서, 일반적으로는 symmetric, simple expansions을 사용하곤 한다.
Reduct all letters to lower case(대문자 제거)
-
모든 문자를 소문자로 바꾼다.
-
단, Fed, SAIL, GM 등 고유 명사를 제외하고.
-
이런 방법들은 감정 분석이나 기계번역, 그리고 정보 요약에서 굉장히 큰 효과가 있다고 한다(US와 us는 다른 단어이기 때문에).

Lemmatization(표제어 추출)

- 모든 단어를 기본 형태로 바꾼다.
- 역시 조심해야 한다.
- 위와 같은 요소는 일종의 Morphology(형태학)으로 이어지기도 한다.
Morphology(형태학, 형태소학)
- Morpheme(형태소) : 단어를 구성하는 작은 요소.
Stems(어간) : 단어의 핵심 의미를 담고 있는 부분
Affixes(첨가어) : Stem을 받쳐주는 부분.
meaningful, units, stems, affixes,
(굵게 칠한 단어가 affixes, 나머지는 stems)
Stemming(어간 추출)
- 즉, 복잡한 단어에서 이런 첨가어를 없애고 핵심 요소인 어간만 뽑아내는 것을 Stemming이라고 한다.
제일 많이 쓰이는 어간 추출 방법은 Porter's algorithm이다.
Porther's algorithm
- 포터 알고리즘은 일종의 간단한 대체 규칙을 여러 개 통합한 알고리즘으로 볼 수 있다.
Step 1a

- sses -> ss, ies -> i, ss : 고정, s : 삭제(일반적으로).
Step 1b

- ing -> 삭제 , 단 조심스럽게 다루어야 하는데, vowel(모음, a,e,i,o,u)을 가진 단어만 지우어야 한다(walk, ing : 삭제 가능).
그 외

--

- 때로는 더 복잡한 어간 추출 방법이 필요하다.
- 가령, 터키어같은 경우 위와 같이 이상한 단어는 수 많은 어간으로 이루어져 있다.
- 그렇기 때문에 더 복잡한 Segmentation 알고리즘이 필요한 것.
6. Sentence Segmentation and Decision Trees

- 문장은 어떻게 나눌 수 있을까?
- !, ? 등은 웬만하면 문장의 끝을 나타내도록 사용할 수는 있겠으나, "."는 분명 약자, 포인트, 직위 등에도 너무나도 많이 쓰인다.
그 외에도 이진 분류기를 만들어 문장의 끝인지 아닌지를 판단할 수도 있을 것이다.
-
가령, 머신러닝이나, 정규 표현식이나, 매뉴얼하게 작성한 규칙이나..
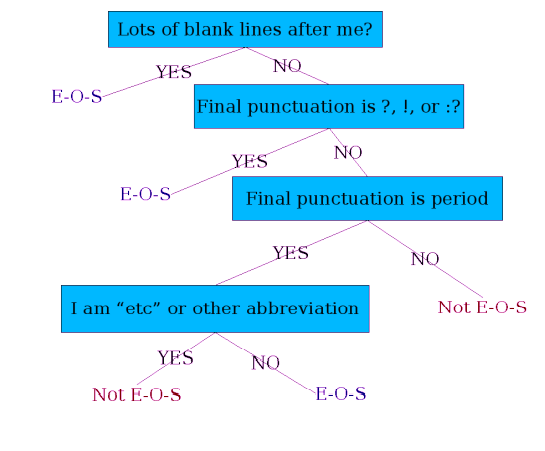
-
웬만하면 납득이 가는 부분이며, 마지막의 period(".")의 경우 굉장히 많은 약자(abbreviation) list로부터 판단할 수 있다(Dr., etc, ...).
결정트리를 조금 더 정교하게 구성할 수도 있다.
-
가령, period 다음에 대문자가 온다면 어느 정도 문장의 끝과 시작이라고 판단할 수 있다든지, period와 같이 쓰이는 단어의 길이가 어떤지(약자는 보통 짧으므로)를 토대로 결정할 수도 있다.
-
또한, Period 이전, 다음 문자를 토대로 확률을 계산할 수도 있다.
(베이즈 정리를 이용해도 되고..)-
가령, "." 뒤에 "The"가 온다면 거의 100%에 가까운 확률로 end of sentence일 것이다.

-
Decision Tree(결정트리)같은 경우 if-then-else 구조로 이루어져 있다. 그렇기 때문에 어떤 features를 판단기준으로 설정할 지도 중요한 요소이다.
일반적으로 결정트리는 직접 구조를 짜기가 매우 어렵다.
10개 이하는 적당히 우선 순위를 정할 수 있겠지만, 이마저도 numeric feature라면 어느 값을 threshold로 정해서 Yes/No를 가를 지도 골라주어야 한다.
그래서, 일반적으로 결정트리의 구조를 형성하기 위해서는 머신러닝 방법을 많이 이용한다.
- 특히나, 이런 방식으로 정한 결정트리로부터 Features를 얻고나면 로지스틱 회귀, SVM, Neural Nets 등 다양한 분류기에 투입할 수도 있다.
7. Minimum Edit Distance
Method
- Minimum Edit Distance(MED로 칭하겠다)는 일종의 문자 간 유사성을 다루는 방법이라 할 수 있다.
가령, graffe라는 단어를 생각해보자.
- 그러면, graf, graft, grail, giraffe 중에는 어느 단어가 graffe와 가까울까?
이런 strings similarity같은 경우 유전체 서열을 비교할 때나, 기계번역, 정보 요약 등의 task에도 널리 사용될 수 있다.
즉, 두 단어(문장)간 유사도를 비교한 다음 Error를 반환해 Evaluation을 진행할 때.

MED는 이런 유사도를 비교하기 위해 사용되는 방법으로, Insertion(삽입), Deletion(제거), Substituion(대체) 등을 수행해 두 문장을 같게 만드는 최소 시행 횟수를 구하는 방법이다.
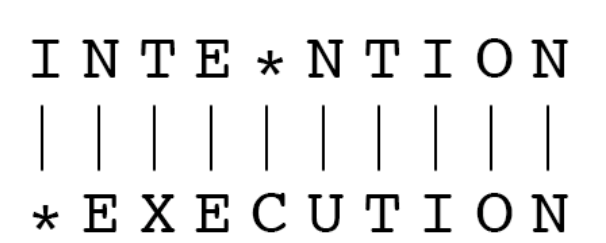
예를 들어, 위와 같은 단어의 경우

이와 같이 5번의 연산을 통해 같게 만들 수 있다.
Levenshtein은 substitutions cost를 2로 계산한 방법이다.
Biology
생물학에서도 이와 같은 태스크를 수행할 수 있다.

Machine Translation

기계 번역 태스크에서도 평가 방법 중 하나로 MED를 택할 수 있다.
즉, 인간 전문가와 모델의 예측 간의 유사도를 비교함으로써, 유사도를 높히는 방향으로 학습하는 것.
(단, 단어 단위로)
또한, Entity Extraction, 즉 단어의 구성은 다르지만 같은 entity를 나타낼 경우에도 사용할 수 있다.
How to find MED
-
최소한의 방법을 찾는 MED는 일종의 시작부터 끝까지 최적의 경로 찾기 문제로 바라볼 수 있다.
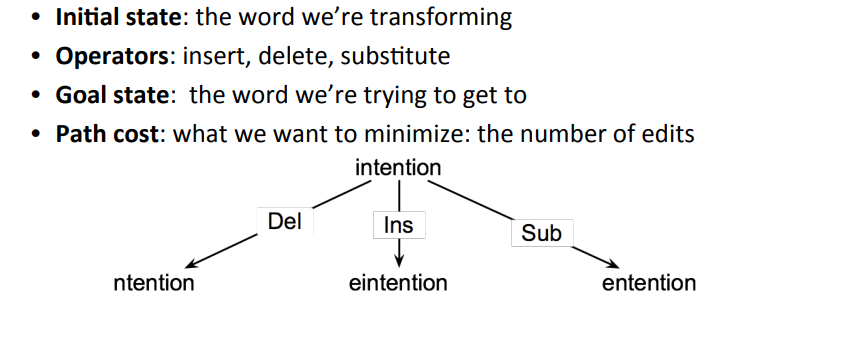
-
즉, path sequence의 길이를 cost로 바라보고, 이를 낮추는 방향으로 수행할 수 있다.

-
단, 위 그림을 봤을 때 8글자임에도 불구하고 아주 많은 경우의 수 ()가 생긴다는 것은 쉽게 예측할 수 있다.
-
그래서, 이처럼 가능한 시퀀스가 너무나도 많은 문제를 푸는 방법들 중 하나로 후보를 제거하는 방법을 사용할 수 있다.
-
가령, 중간중간 가장 짧은 경로만을 택한다든지..
-
이는 후에 서술할 Dynamic Programming(DP)에서 다루어 보도록 하자.
8. Computing Minimum Edit Distance
Dynamic Programming

- Dynamic Programming(DP)는 일종의 표 형태의 계산 방법이다.
- 목표는 길이 을 가지는 두 스트링을 비교하는 것이다.()
이런 큰 문제 를, subproblem인 로 쪼개서 생각하되, 더욱 큰 로 점차 확대해가며 계산하는 방법이다.
대치 연산인 Substitute에 2의 cost를 부여하는 Levenshtein 알고리즘은 아래와 같다.

9. Backtrace for Computing Alignments
- edit distance는 분명 중요하지만, 이것만으로는 충분하지 않다.
- 가령, 때때로는 두 스트링 간의 할당 관계(alignments)를 알고싶어질 수 있다.
- 즉, 한 문장의 단어가 다른 문장의 단어와 어떻게 대응하는지.
맞춤법 검사나 기계번역, 유전체 계산 등에 쓰이는 distance를 사용한다면 더욱 중요해진다.
이런 alignments를 계산하는 방법에는 keep a backtrace를 예로 들 수 있으며, 테이블의 각 셀을 채울 때마다 어디서 왔는 지 알려주는 포인터 역할을 한다고 볼 수 있다.
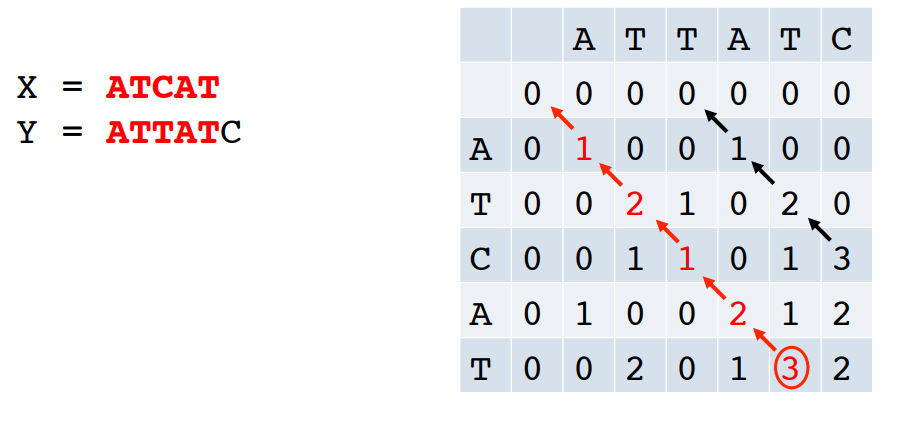
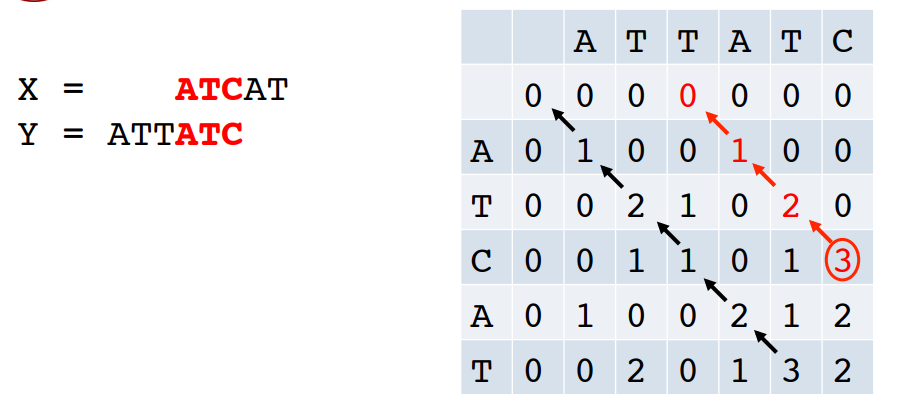
즉, 마지막까지 셀을 채웠을 때 기록해놓은 pointer를 필두로 모든 할당을 파악하기 위해 거슬러 올라갈 수 있다(trace back).
역시 예시와 함께 보자.
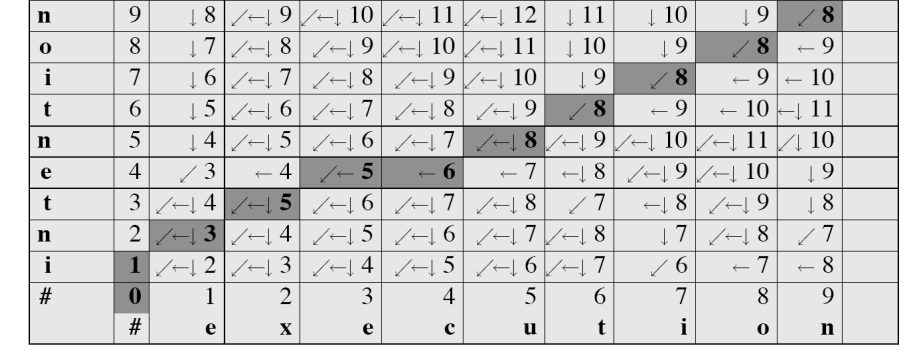
즉, 위 그림을 토대로 (우측 상단부터) 8888까지는 matching, 그 다음 8은 substitute, 그 다음 6은 insertion, .. 이 일어난 것을 알 수 있다.
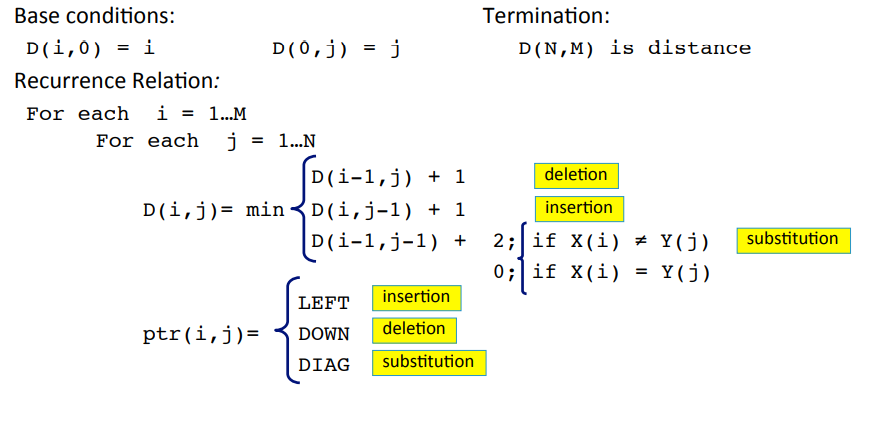
- 알고리즘은 위와 같다.
- pointer가 추가된 것을 볼 수 있다.
특히, 감소하지 않는 길을 택할 경우 이는 두 시퀀스 사이의 alignment에 해당한다.
- 즉, 최적의 alignment는 최적의 sub-alignments로 이루어져 있기 때문에 Dynamic Programming을 하더라도 문제 없이 최적의 해를 찾을 수 있는 것.
시간복잡도는 아래와 같다.

- 행렬을 이용하며, 가장 최악의 경우의 수는 을 넘지 않는다.
10. Weighted MED
- MED 또한 가중치를 부여할 수 있다.
- 가령, 몇 개의 단어는 다른 것에 비해 오탈자가 생길 가능성이 높다든지, 생물학에서도 특정한 부분은 다른 부분보다 제거 / 삽입이 흔하다든지..

위에서도 a와 e를 헷갈린다든지, a와 i를 헷갈린다든지 하는 일이 많다.

- 간단하게는, 기존에는 cost를 1또는 2로 정의했을 때와 별개로 Lookup Table을 이용해서 특정한 가중치만큼의 cost를 부여한다.
11. MED in Computational Biology
- 계산 생물학 쪽에서도 MED의 여러 변형들이 좋은 역할을 지닐 수 있다.
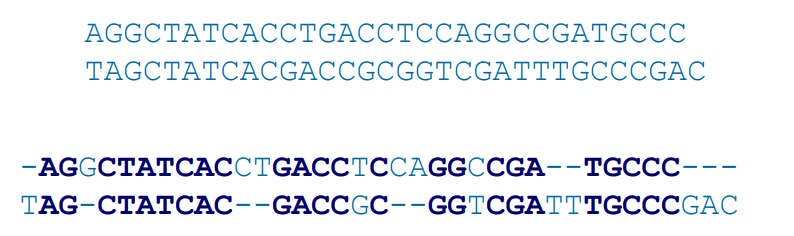
- 유전자 구조에서 중요한 영역을 찾을 수 있다.
- 유전자의 기능을 파악할 수 있다.
- 여러 종을 비교함으로써 진화와 관련된 것을 찾을 수 있다.
- DNA 염기 서열 간의 중복된 부분을 비교함으로써 어디서 유사성이 생기는 지, 어디서 차이가 생기는 지 살펴볼 수 있다.
NLP 분야와 생물학 분야에서 Alignment를 다루는 이유는 아래와 같다.
- NLP : 두 문장 간 거리를 최소화하기 위해서(필요한 Weight)
- Biology : 두 서열 간 유사성을 최대화하기 위해서(도출되는 Score).
생물학 분야에서는 Needleman-Wunsch 알고리즘을 활용해 기본적인 최소 거리를 구할 수 있다.

min이 아니고 max이다(Score 관점으로 진행하므로).
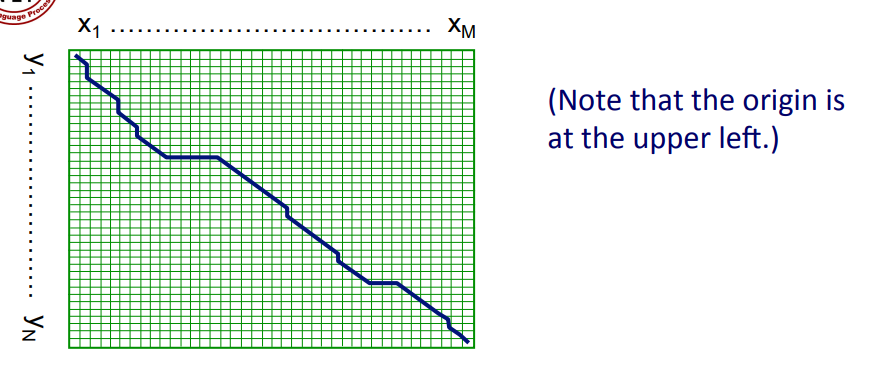
또한, 좌측 위부터 시작한다.
다만, 유전자 서열같은 것을 비교할 때에는 실질적으로 전체를 비교하기 보다는 일부분만 비교하는 경우가 잦기에, 아래와 같이 변형해주는 경우가 많다.

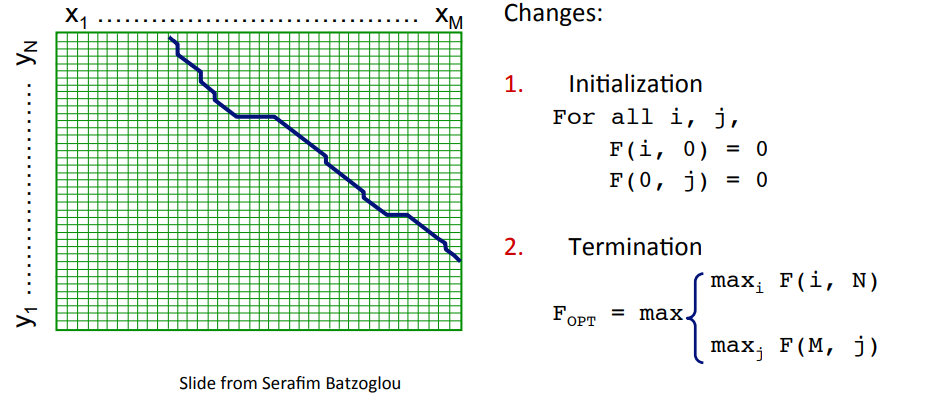
유사한 확장은 local alignment problem이다.
길이의 , 그리고 길이의 가 주어졌을 때,
유사성이 가장 높은 substrings를 구하는 게 목표다.
가령, 아래에선 cccggg이다.

이는 substrings 이전, 이후의 unaligned sequences를 무시하는 것을 제외하면 위에서 다룬 Needleman-Wunsch 알고리즘과 유사하다.
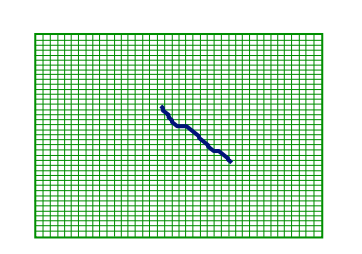
Needleman-Wunsch 알고리즘을 수정한 알고리즘은 Smith-Waterman 알고리즘이라 할 수 있다.
크게 차이나는 것은, 특정 위치에서 시작할 때 score를 0으로 고정해준다는 것과, 다음 스텝으로 넘어갈 때 (만일 문자가 달라 Score가 줄어든다면) 다시 score를 0으로 높혀주는 term이 존재한다는 것 뿐이다.

즉, 최종 목적은 local maximum sub-sequences를 찾고 traceback을 이용해 local alignment를 찾는 것이다.

특정 유사성 이상의 서브시퀀스들을 모두 구할 때 이들끼리 겹치면 다루기 힘들지만..
예시를 다루어보자.
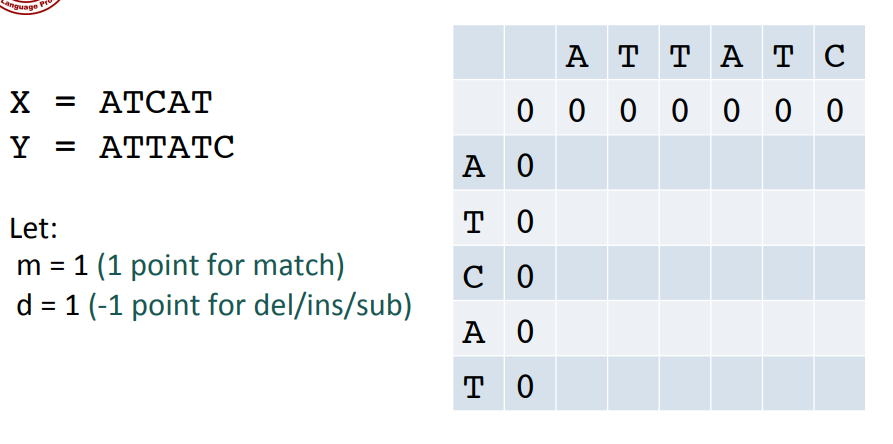
- 우선, Score와 Penalty는 위와 같이 주고, 행렬의 모서리를 기본적으로 0으로 맞춰준다.
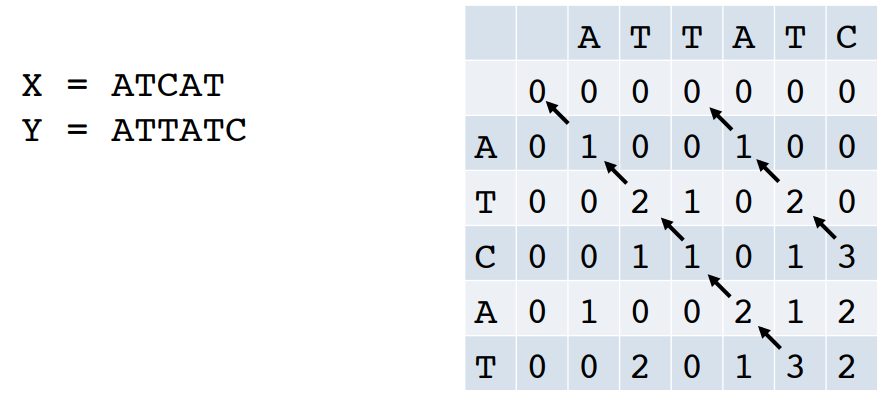
이전 알고리즘을 통해, 지나치게 유사하지 않은 sub-sequence는 0으로 반환되고, 얼추 유사하게 흘러가는 sub-sequence는 Score를 올려 최종적으로 2개의 sub sequence를 찾을 수 있다.