두줄 요약
- [풍경 그림 - Segmentation Label] pair data 없다.
- 그렇다고 풍경 사진에 사전 학습된 Segmentation model을 풍경 그림에 적용하면 Segmentation Label을 제대로 얻을 수 있을까)?
- 약간 부정적인 편
모든 생성 모델의 경우 학습할 데이터의 특성이 가장 중요합니다.
가령, 현실 이미지와 그림 이미지를 섞어서 학습을 진행할 경우, 디테일한 표현력을 보이지 못할 수도 있습니다.
그렇기 때문에, 많은 데이터를 확보하되 비슷한 representation을 보이는 데이터 셋을 선택해야 합니다.
본 글에서는 현실 이미지를 제외하고 그림에 대한 데이터 셋을 정리했습니다.
1. 풍경 - 그림
2. 풍경 - 일러스트
특히, 대부분의 State-of-the-art segmentation model은 실제 사진을 대상으로 학습된 모델일 가능성이 크기 때문에 그림에 적용할 경우 새롭게 학습해야 하거나 전이학습이 필요할 수 있습니다.
- 풍경 그림은 풍경 사진과 비슷한 특성을 지니므로 final layer만 학습시킬 수 있습니다.
- 혹은 마지막 layer를 추가해서 그 layer만 학습시키는 것도 가능합니다.
- 데이터가 많다면 pre-trained model을 이용해(pre-trained weight를 initial point로) 그냥 전체 모델을 다시 학습시킬 수 있습니다.
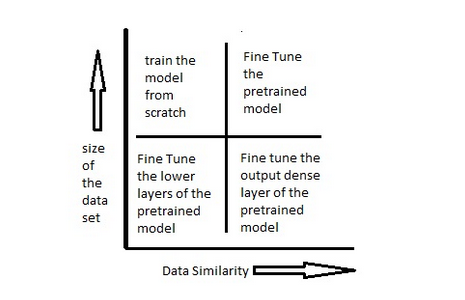
Bulit-in Dataset vs (Fine-tuned) Segmentation
전자는 그냥 사용해도 되고, 후자는 구글 이미지 등에서 크롤링 해야될 수도 있음.
- 근데 크롤링한 이미지에 라벨 부여하려면 적어도 fine-tuning시킨 segmentation model이 필요하기 때문에 결국 라벨이 필요하긴 함,, ㅠㅠ
가령, 연구 Scribble-to-Painting Transformation with
Multi-Task Generative Adversarial Networks
에서는 아래와 같은 아키텍처 구현을 위해 Segmentation을 제공하는 COCO Dataset을 활용해 real-image와 segmentation map을 얻고, 추가적인 기법을 활용해 엣지 데이터를 만든다(아래의 Fig 3.(a)). 거기에 또 다른 스타일 모델을 활용해 Ground Truth를 얻는다(아래의 Fig 3.(b)).
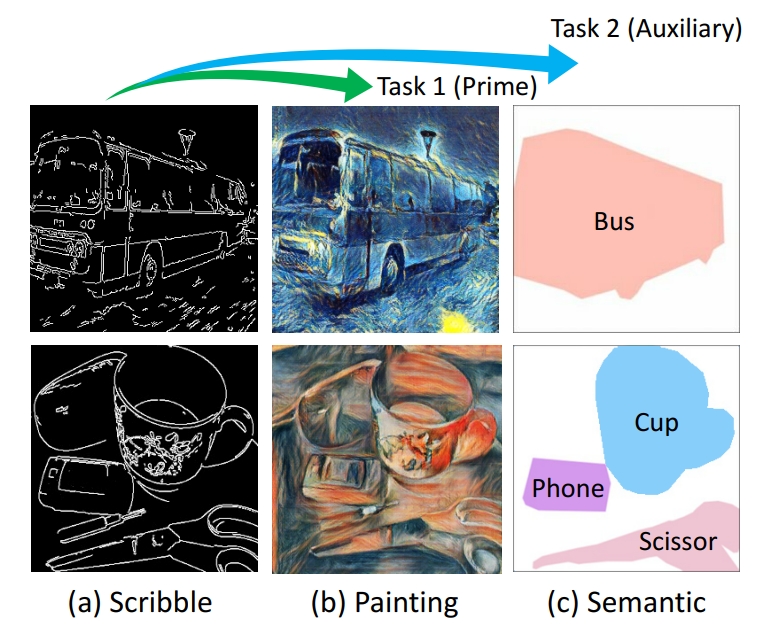

그러니까, [풍경 이미지-Segmentation map]pair를 얻기 위해 [실사 이미지 - Segmegmentation] pair와 Style transfer model을 활용해 실사 이미지 -> 풍경 이미지를 만들어 버려 강제로 pair를 얻는다는..
이 방법이 쓰이는 이유는
풍경 이미지를 보고 Label을 만들어 주는 사람은 세상에 없다는 것
- 실제 이미지 --> 그림 이미지는 사실상 pair-data가 없어도 비지도로 Style transfer가 가능해 많은 데이터를 얻을 수 있다는 것.
Since the photos contain full information,
the quality of synthesized paintings is good enough for them to serve as the training ground truths
정리하자면, pre-trained Sota Segmentation model + [(Style-transfered)풍경이미지 + Segmentation map] : fine-tuning
--> 크롤링한 풍경 이미지(혹은 + 위에서 fine-tuning한 Segmentation model -> 대용량 풍경 이미지.
아니면 그냥 실제 풍경 이미지를 Style-transfer로 그림 이미지로 바꾼 다음, 그렇게 바뀐 이미지와 Segmentation map을 활용해 그대로 생성 모델을 학습시켜도 되긴 함.
(엄밀히 따지면 실제 그림은 아니긴 한데 뭐.. Fine-tuning시키기 귀찮다면 ㅎㅎ..)
1. 풍경 그림(landspace paintings)

1.1. Image Recoloring of Art Paintingsfor the Color Blind Guided by Semantic Segmentation


- R-CNN, Rast R-CNN 등 Object Detection 등에 널리 쓰이는 모델들이 있습니다(비교적 옛날 모델).
- 이의 변형인 Mask R-CNN은 단순히 Bounding box를 찾는 것 뿐만 아니라 object의 mask를 detect하는 Image Segmentation에 쓰입니다.
- 즉 이미지의 pixel에 대한 class를 찾습니다.
위의 예시들은 분명 좋은 성능을 보이지만, 이는 당연하게도 large datasets에 학습됐을 때의 얘기이며, 의학 분야나 art images처럼 학습 데이터가 별로 없는 이미지에는 성능 면에서 문제가 많을 수 있습니다.
보통 이런 down-stream task에는 transfer learning을 사용하는 것이 일반적인 방법입니다.
Transfer Learning
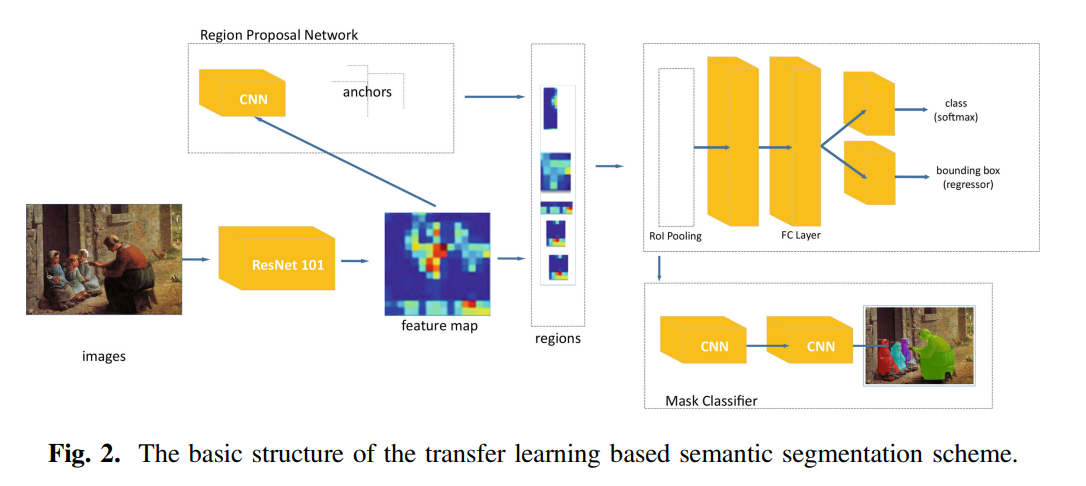
저자들은 Art-images에 Segmentation을 적용하기 위해 Implementation of Mask-RCNN을 사용했다고 합니다.
- 9 classes, in 75 annotated images(클래스 당)
- 사람, 배, 새, 말, 그릇, 의자, 테이블, 물병, 과일 등
전반적인 과정을 정리하면 아래와 같습니다.
- Image Augemtnation(데이터가 적으니 당연)
- horizontal flip, random crop, Gaussian blur, Contrast, Brightness, Affine Transformation
- Backbone : ResNet101
- Feature map 추출용
- Imagenet에 학습된 가중치를 사용
- Fine-Tune : level 4 layer와 heads만 학습
- Art Image에 잘 작동하는 weight를 얻어야 하므로
Result

1.2. Semantic Segmentation of Manmade Landscape Structures in Digital Terrain Models
Paper : 여기
2. 풍경 일러스트(landscape illustration)
- 얘네는 빼박 어떻게든 크롤링해서 라벨 만들어야
3. Image Segmentation Github
3.1. Mask R-CNN
https://github.com/matterport/Mask_RCNN
- Mask-RCNN을 이용한 Segmentation.
- Fine tuning에 쓰일 수 있음.
- SOTA는 당연 아님
3.2. U-NET
https://www.kaggle.com/basu369victor/transferlearning-and-unet-to-segment-rocks-on-moon/notebook
- Unet을 이용해 달 사진에 Transfer Learning을 적용
Sota in Segmentation
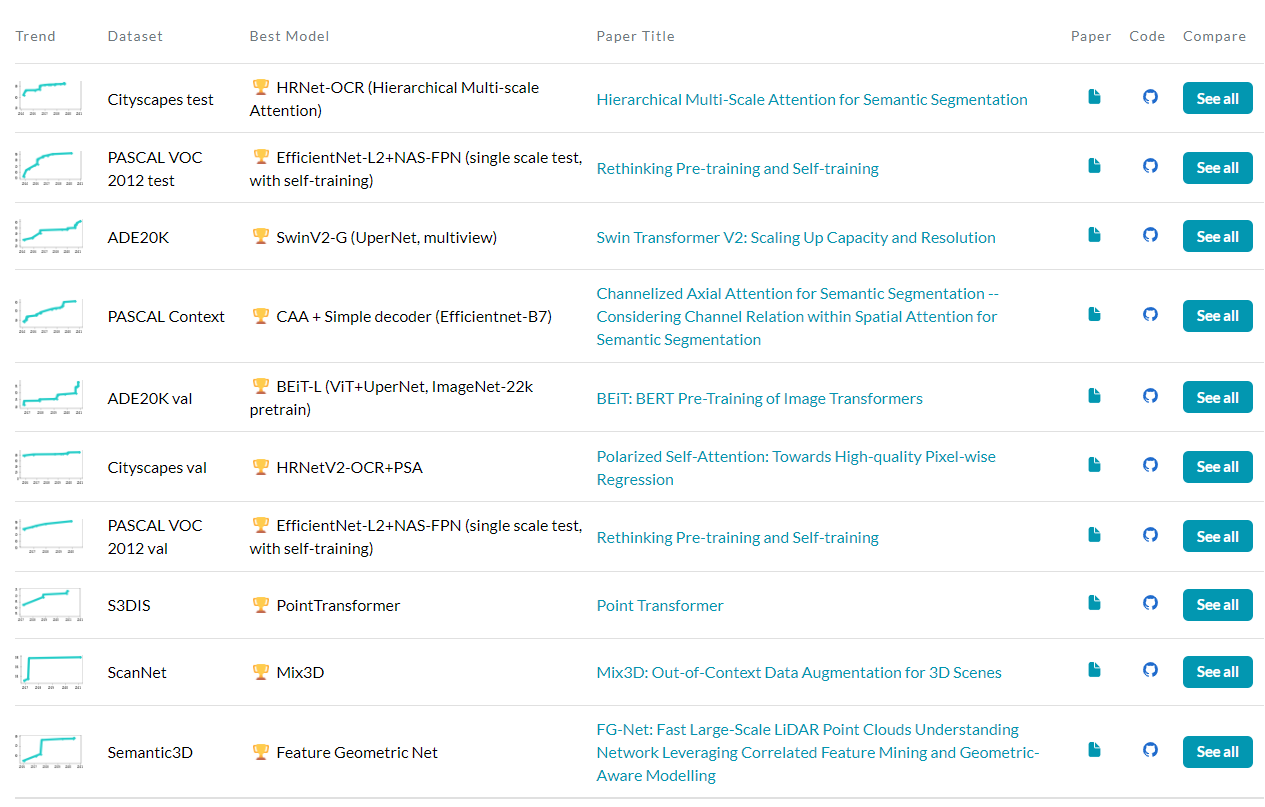
Art dataset
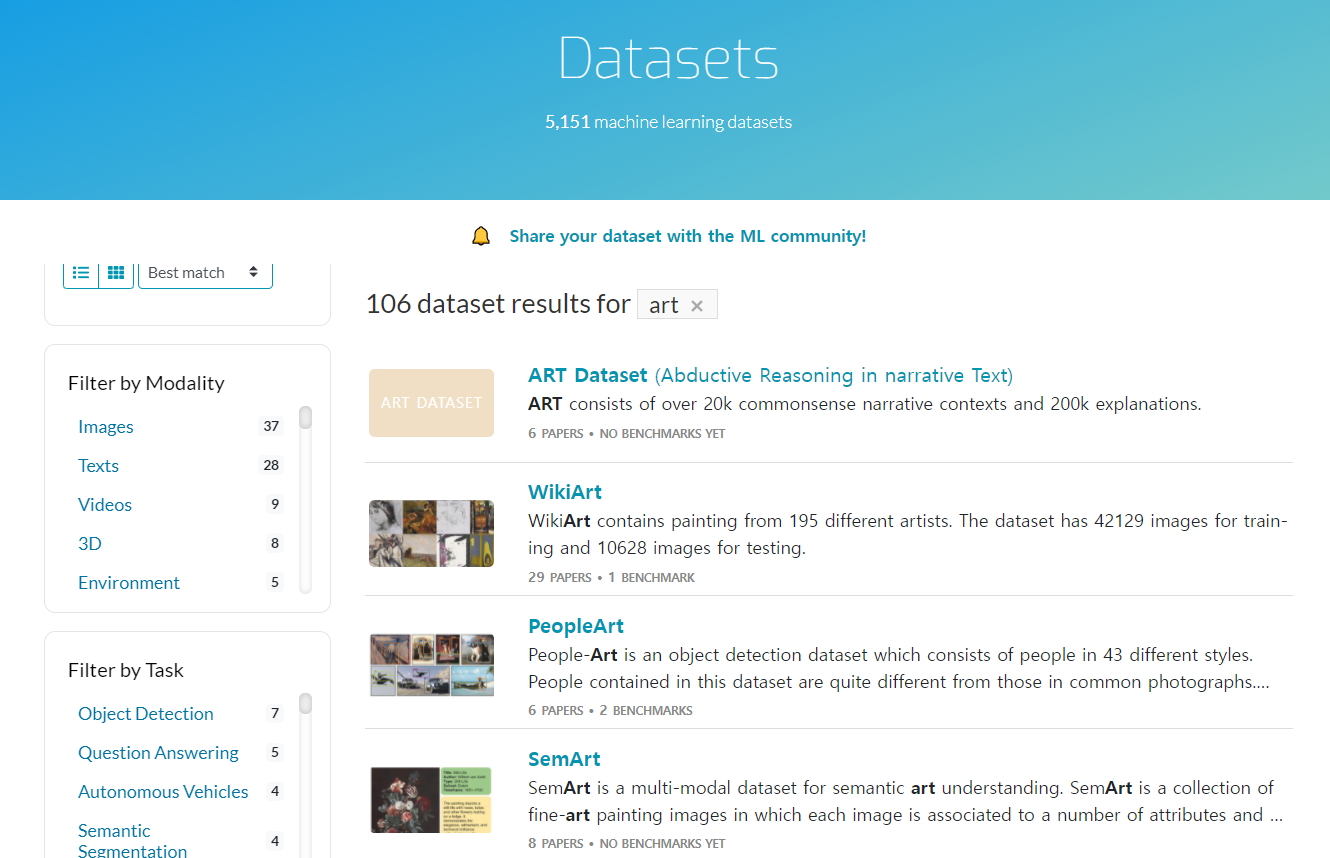 !
!
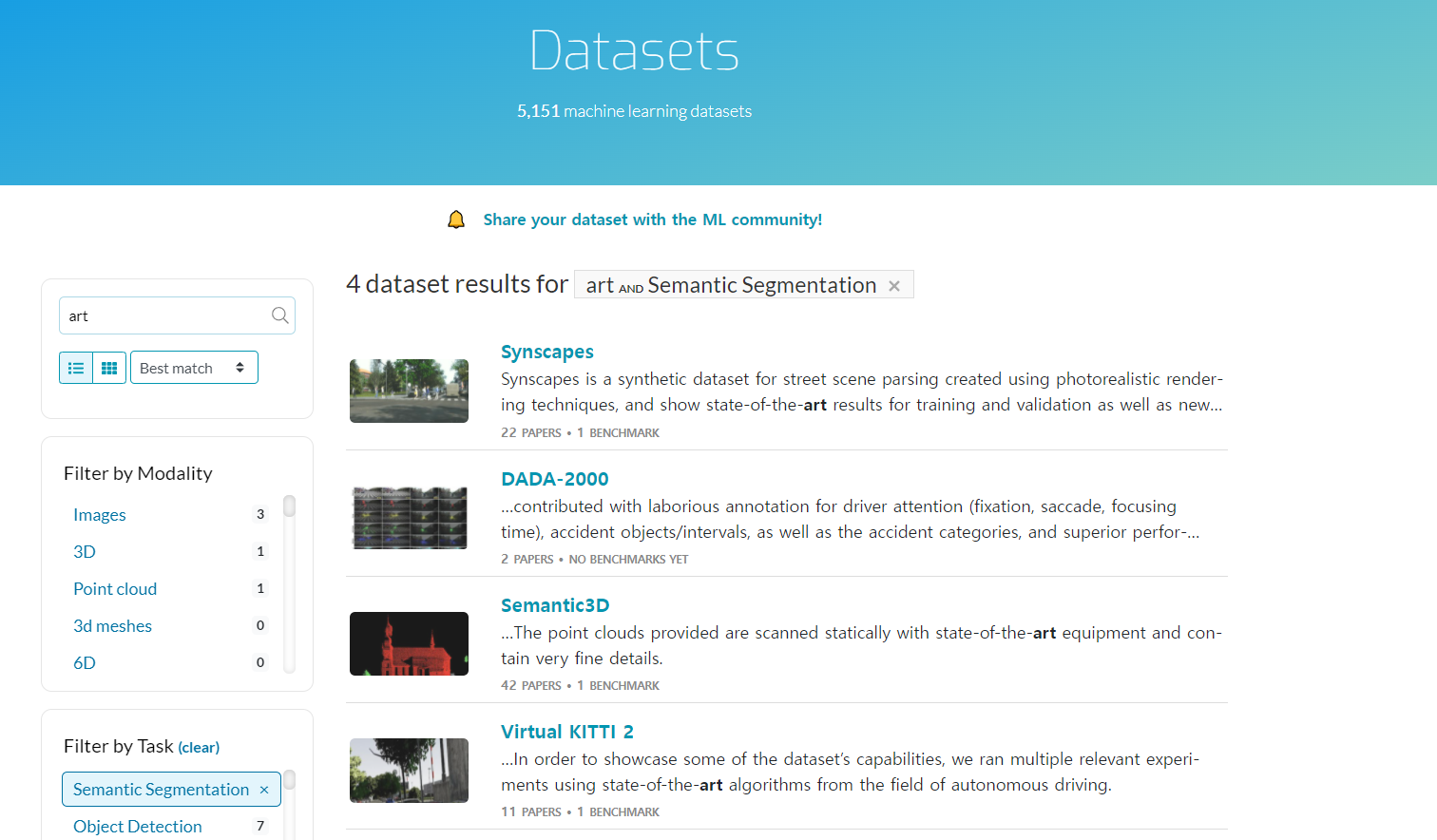
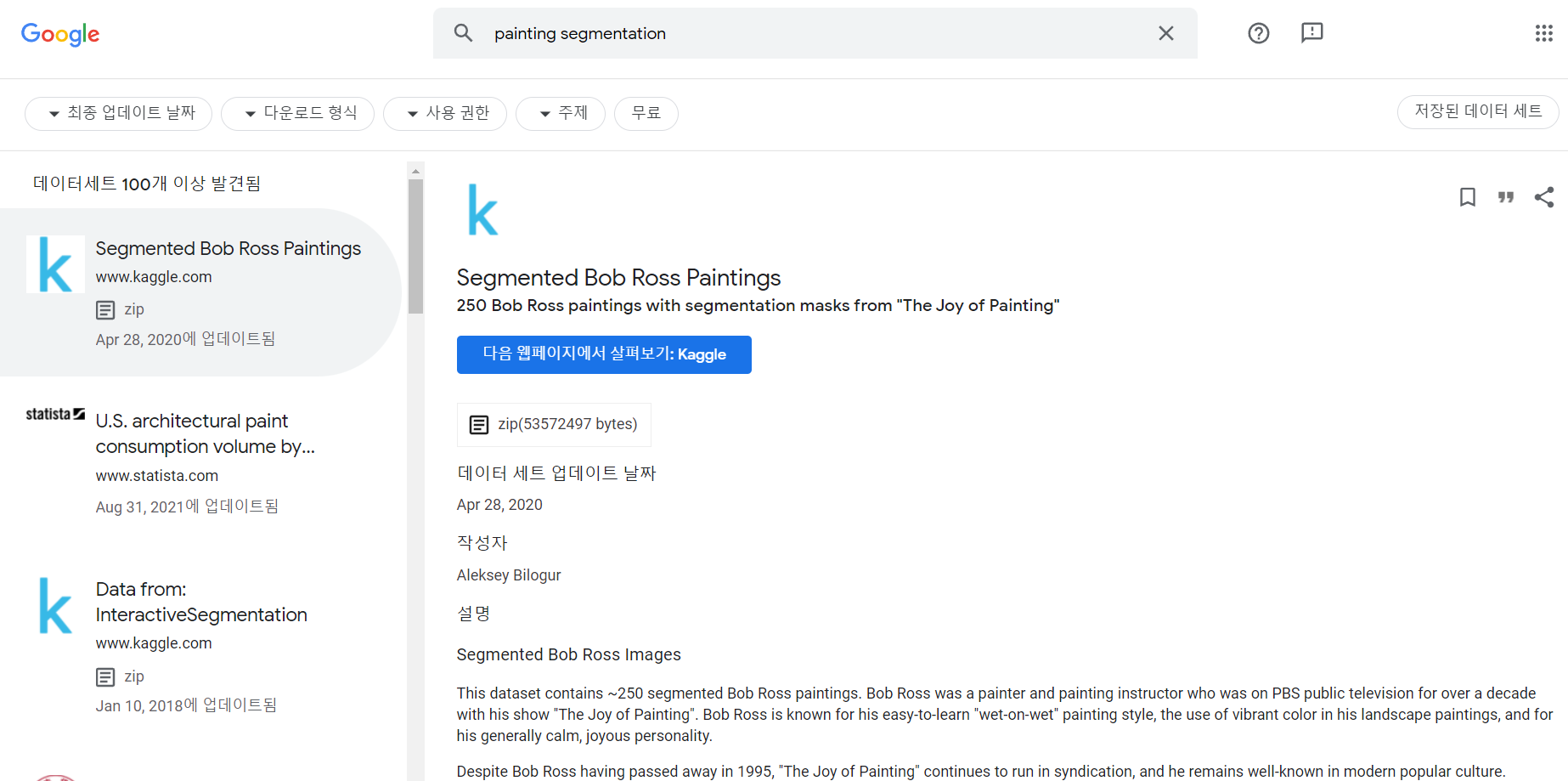
풍경 그림에 (풍경 사진용) Segmentation 곧바로 적용해보기


제대로 구역을 나누지 못한다.
이는 위 그림의 경우 일러스트레이션이고, 아래 그림의 경우 그림이지만 너무 복잡한 풍경이라서 애초에 힘든 걸 수도 있음.
어느 정도 실사를 바탕으로한 그림의 경우 최소한의 성능은 나올 것
기타 SPADE 관련 issue
SPADE 연구가 데이터 셋을 마련하기 위해 사용한 Segmentation model은 아래와 같습니다.
(Fliker Landscape가 풍경 이미지)


Training Details

단, SPADE 모델 학습 시 사용할 평가 지표를 위해서 Segmentation을 추가적으로 사용하긴 합니다.
![]
(아니 근데 풍경 이미지에 대한 Segmentation model 배포는 안 하신다네요..)
https://github.com/NVlabs/SPADE/issues/8
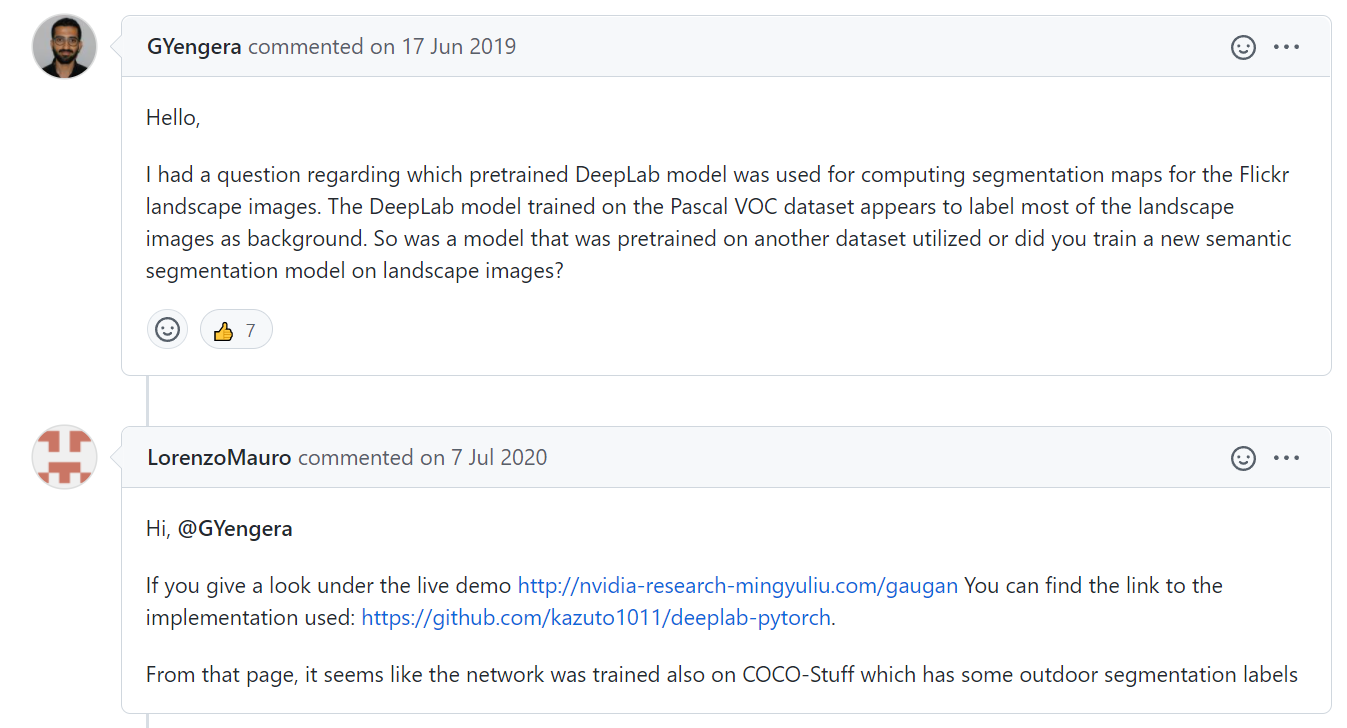
(Segmentation model을 곧바로 사용하면 그림 이미지는 대부분 background로 판별해버린다는..)
(--> 저자들이 어떻게 풍경 이미지에 Segmentation을 적용했는 지 잘 모름)
또한, Segmentation에 자주 쓰이는 Deeplab2 또한 '자연 풍경'에 대한 pre-trained model은 없는 듯
(https://github.com/tensorflow/models/tree/master/research/deeplab)
(외부 풍경에 대한 Label도 있는 CoCo-Stuff를 대신 사용했을 수도 있다는 글)
https://github.com/NVlabs/SPADE/issues/56
(돈 내고 Landscape Segmentation Model 학습하자는 글)
https://github.com/NVlabs/SPADE/issues/17
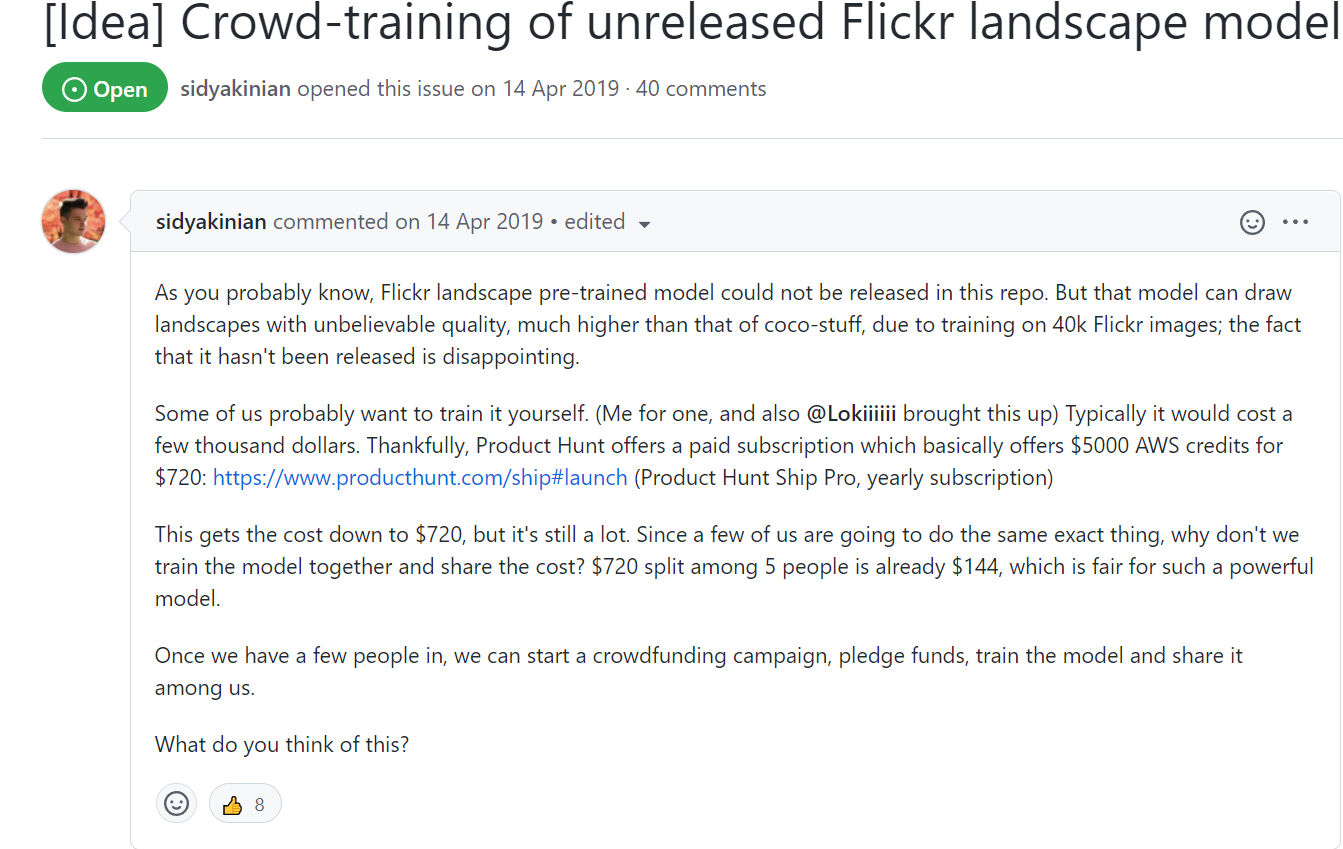
(학습 드디어 완료했다는 글)
- https://twitter.com/genekogan/status/1136261959970709504
- https://drive.google.com/drive/folders/1QJr5HBv8PAjJuVNB9zf8EiA6IcIVCswa
(Segmentation model이 필요하긴 하지만..)
(위 github 따라서 CoCo-Stuff로 풍경 이미지에 라벨링 했다는 글)

https://paperswithcode.com/task/semantic-segmentation

결론
https://github.com/kazuto1011/deeplab-pytorch/
풍경 이미지에 pre-trained된 모델은 없지만 coco-stuff에도 풍경 label들이 존재해 이를 통해 Segmentation model을 간접적으로 사용할 수 있다.
이렇게 얻은 Label을 이용해 SPADE 모델을 학습한 커뮤니티는 있지만 여전히 그림에 대한 Segmentation model or SPADE model은 없음.
ㅠㅠ
