[Inference] TTTT for landscape paintings using pre-trained-to-FlickrLandscape SPADE model
Generative Model
Segmentation mask(즉, Segmentation model) 있어야 합니다(라벨 때문).
우선 Segmentation model 없이 sample segmentation mask 사용.
Label : CoCo-Stuff(without 'unknown' label)
코드 수정 최소화하였음(애초에 Test Time Training을 목표로 한 코드가 아니기 때문에 학습 시간은 훨씬 오래 걸릴 수 있음).
(가능성 보이면 코드 수정 시작)
0. Landscape image
Flickr Landscape에 학습된 모델 사용.
label
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'street sign', 12: 'stop sign', 13: 'parking meter', 14: 'bench', 15: 'bird', 16: 'cat', 17: 'dog', 18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra', 24: 'giraffe', 25: 'hat', 26: 'backpack', 27: 'umbrella', 28: 'shoe', 29: 'eye glasses', 30: 'handbag', 31: 'tie', 32: 'suitcase', 33: 'frisbee', 34: 'skis', 35: 'snowboard', 36: 'sports ball', 37: 'kite', 38: 'baseball bat', 39: 'baseball glove', 40: 'skateboard', 41: 'surfboard', 42: 'tennis racket', 43: 'bottle', 44: 'plate', 45: 'wine glass', 46: 'cup', 47: 'fork', 48: 'knife', 49: 'spoon', 50: 'bowl', 51: 'banana', 52: 'apple', 53: 'sandwich', 54: 'orange', 55: 'broccoli', 56: 'carrot', 57: 'hot dog', 58: 'pizza', 59: 'donut', 60: 'cake', 61: 'chair', 62: 'couch', 63: 'potted plant', 64: 'bed', 65: 'mirror', 66: 'dining table', 67: 'window', 68: 'desk', 69: 'toilet', 70: 'door', 71: 'tv', 72: 'laptop', 73: 'mouse', 74: 'remote', 75: 'keyboard', 76: 'cell phone', 77: 'microwave', 78: 'oven', 79: 'toaster', 80: 'sink', 81: 'refrigerator', 82: 'blender', 83: 'book', 84: 'clock', 85: 'vase', 86: 'scissors', 87: 'teddy bear', 88: 'hair drier', 89: 'toothbrush', 90: 'hair brush', 91: 'banner', 92: 'blanket', 93: 'branch', 94: 'bridge', 95: 'building-other', 96: 'bush', 97: 'cabinet', 98: 'cage', 99: 'cardboard', 100: 'carpet', 101: 'ceiling-other', 102: 'ceiling-tile', 103: 'cloth', 104: 'clothes', 105: 'clouds', 106: 'counter', 107: 'cupboard', 108: 'curtain', 109: 'desk-stuff', 110: 'dirt', 111: 'door-stuff', 112: 'fence', 113: 'floor-marble', 114: 'floor-other', 115: 'floor-stone', 116: 'floor-tile', 117: 'floor-wood', 118: 'flower', 119: 'fog', 120: 'food-other', 121: 'fruit', 122: 'furniture-other', 123: 'grass', 124: 'gravel', 125: 'ground-other', 126: 'hill', 127: 'house', 128: 'leaves', 129: 'light', 130: 'mat', 131: 'metal', 132: 'mirror-stuff', 133: 'moss', 134: 'mountain', 135: 'mud', 136: 'napkin', 137: 'net', 138: 'paper', 139: 'pavement', 140: 'pillow', 141: 'plant-other', 142: 'plastic', 143: 'platform', 144: 'playingfield', 145: 'railing', 146: 'railroad', 147: 'river', 148: 'road', 149: 'rock', 150: 'roof', 151: 'rug', 152: 'salad', 153: 'sand', 154: 'sea', 155: 'shelf', 156: 'sky-other', 157: 'skyscraper', 158: 'snow', 159: 'solid-other', 160: 'stairs', 161: 'stone', 162: 'straw', 163: 'structural-other', 164: 'table', 165: 'tent', 166: 'textile-other', 167: 'towel', 168: 'tree', 169: 'vegetable', 170: 'wall-brick', 171: 'wall-concrete', 172: 'wall-other', 173: 'wall-panel', 174: 'wall-stone', 175: 'wall-tile', 176: 'wall-wood', 177: 'water-other', 178: 'waterdrops', 179: 'window-blind', 180: 'window-other', 181: 'wood'}000000001490.jpg, 000000203744.jpg 사용
오류뜸
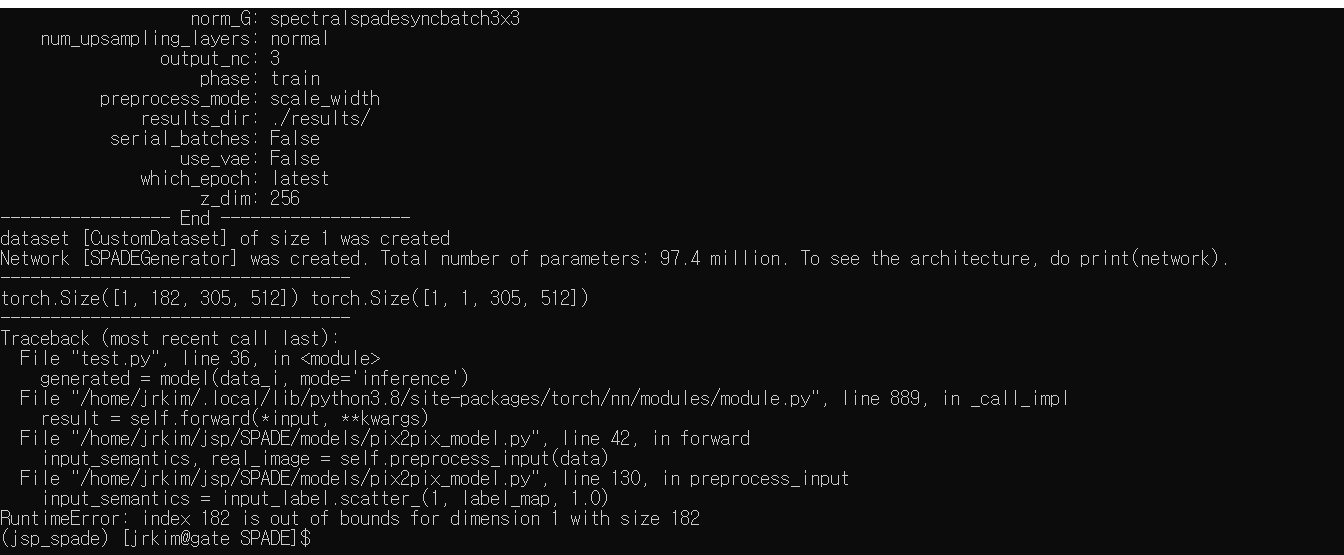
Label Background에 255인가 픽셀 이상한 거 껴있음..
Generation(without adaptation to single image)

↓↓↓

Training(to single Image)
학습할 경우 최신 모델로 대치되므로 원본 손상 조심.

배치사이즈보다 남은 이미지가 적으면 학습 때 어떻게 될까요?
학습을 안 합니다 !!
1로 꼭 고칩시다..
50에폭 시작
python train.py --name Flickr --dataset_mode custom
--label_dir TTTT/test_label2
--image_dir TTTT/test_img2 --continue_train
--load_from_opt_file --gpu_ids=1 --niter 500
--save_epoch_freq 50 --batchSize 1 --lr 0.00005
--preprocess_mode resize_and_crop --which_epoch 50
--print_freq 50 --load_size 286 --crop_size 256 ```preprocess_mode도 켜주어야 한다.
기존 pretrained_model : --preprocess_mode scale_width
load,crop은 우선 빼놓고 실행해보고, 작동 안 할 때만 저렇게 맞춰주기.
스케일이 2배 늘어서 그런가 조금 더 느리긴 하다.
(가 아니고 GPU kernel 관리를 잘 못했었음)
(Test-Time Training 안 했을 경우)
새는 원래 기존의 pre-trained model에 없는 클래스입니다 !!
(원래 순수 풍경 이미지를 가져와야 하나, CoCo-Stuff 기반 Segmentation model을 아직 못 들고와서 ㅎㅎ..)
After TTT
아마 생성자는 5에폭당 1회 업데이트(추후 변경 필요).










원래 아래의 task를 하려고 했으나, 엄밀히 따지면 pre-trained model에 새에 대한 representation이 포함되어 있지 않기 때문에, 이에 대해서는 pass하기로.
- 어차피 200에폭 이상 학습시키는 경우 시간낭비도 너무 심하므로, 최대한 pre-trained model을 활용하는 방향으로 진행.
에폭 별로 새롭게 Object를 추가(제거)한 Segmentation 띄워보기
- 새로운 라벨 sample들 만든 후
Paintings
- 라벨 마련한 다음
- 그림 이미지에 대한 Segmentation model을 학습시키든지
- 아니면 우선 (실사 + 라벨) -> Style transfer (그림 + 라벨)을 이용하든지.
