Some papers about representation
Conference & arxiv
2019
Utilizing Class Information for Deep Network Representation Shaping
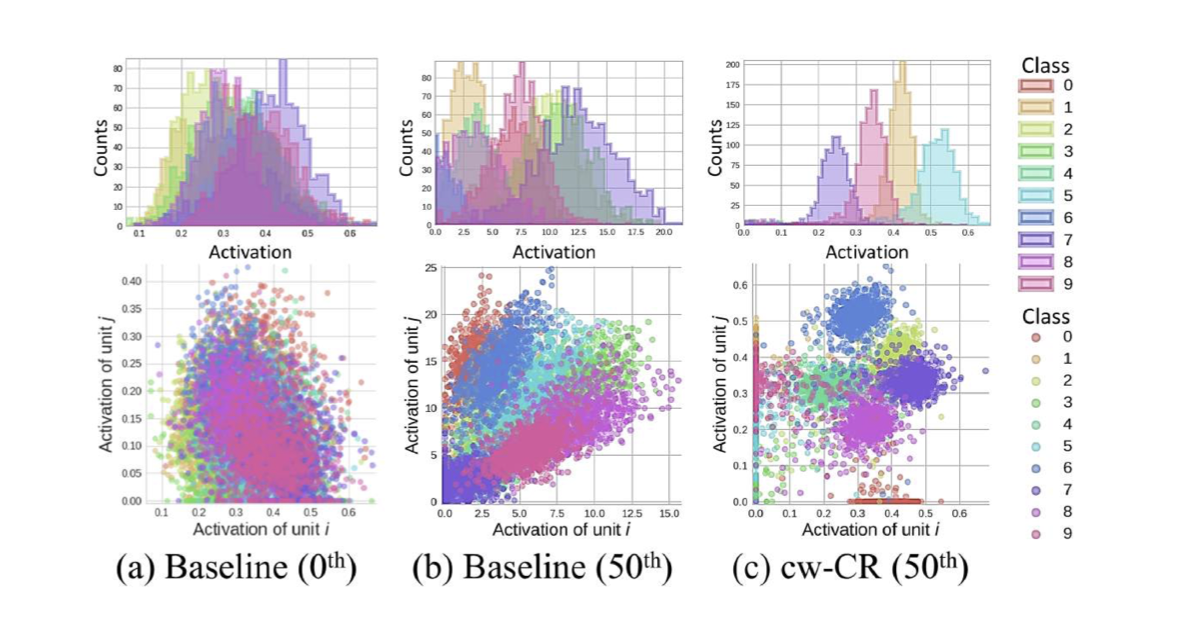
- 딥러닝에서 representation의 sparcity, correlation과 같은 통계량은 네트워크의 성능과 해석가능성에 관련이 있다고 알려져 있음.
- 이런 통계량은 학습 단계에서 적절한 regularizer를 이용해 조작할 수 있으며, 이는 모든 class에 대해 적용되는 경향이 있음.
- 하지만, 클래스 별로 특징을 더 두드러지게 하기 위해 class-wise statistics(통계량)조작을 유도하는 게 더 좋을 수도 있음.
- 그래서 우리는 class information을 명시적으로 활용하는 2개의 class-wise regularizer를 제안했다.
- class-wise Covariance Regularizer (cw-CR)
- 클래스간 Covariance를 줄여 피쳐 독립성(feature independence)를 강화
- class-wise Variance Regularizer (cw-VR)
- 클래스 내부의 분산을 줄여 compactness를 강화
- class-wise Covariance Regularizer (cw-CR)
- 위 방법의 효용성을 증명하기 위해 class information을 사용하지 않는 Regularizier들도 사용함.
- 아무튼, 다양한 representation regularizer에 따라 representation의 모양도 다르다는 것.
연구의 핵심 figure
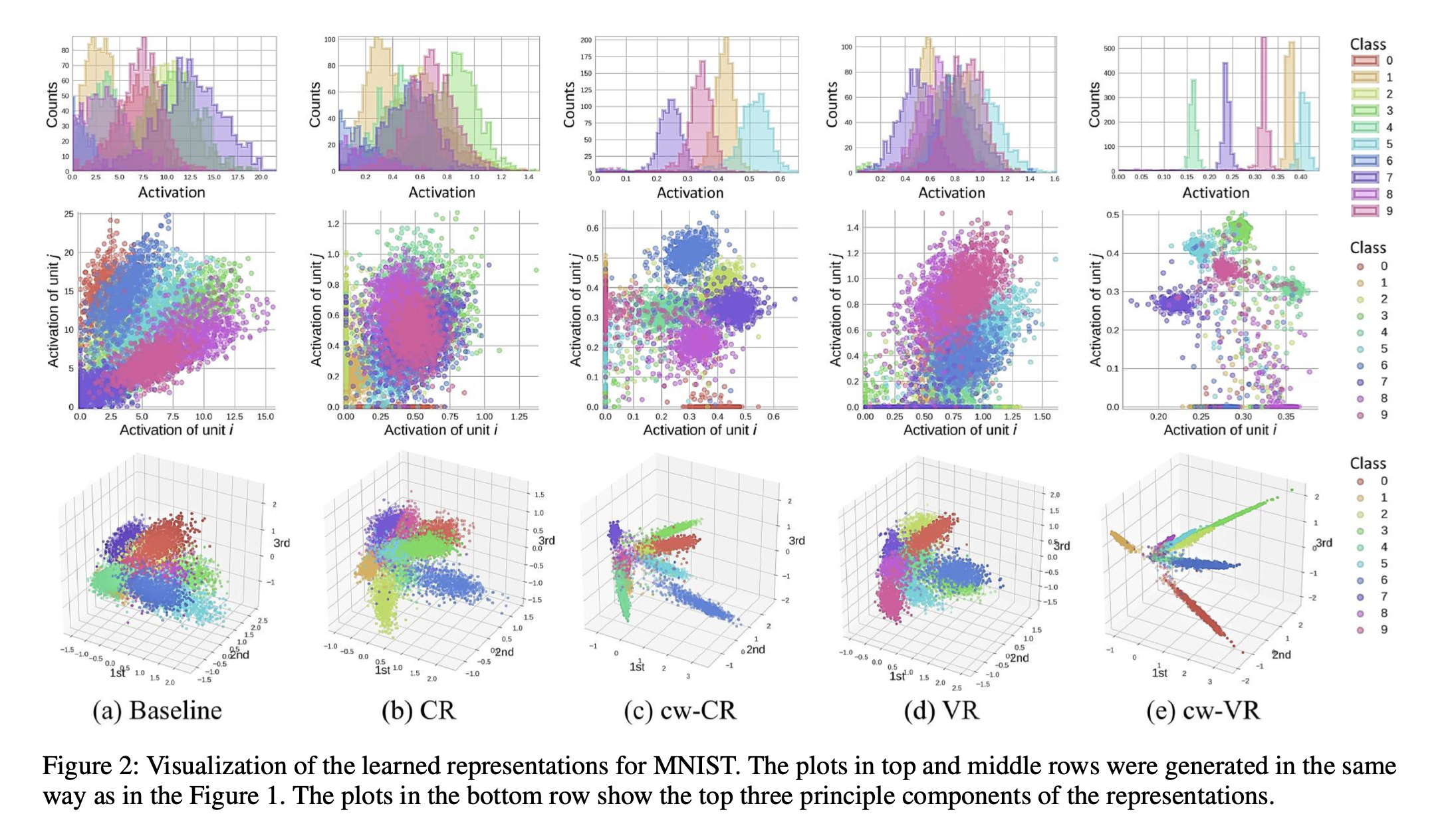
특히, 널리 사용하는 L1/L2 Regularization 또한
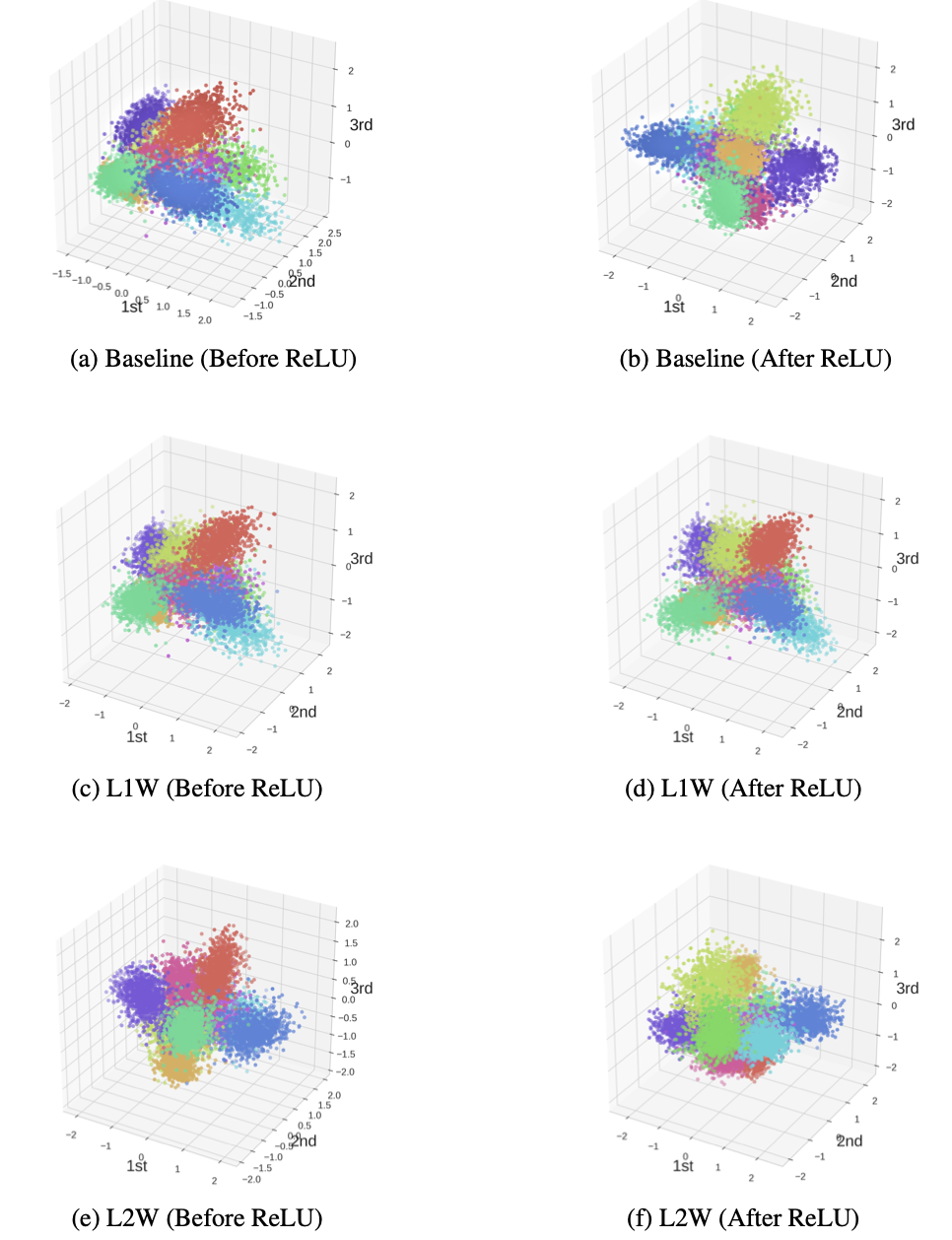
- L1/L2 Regularization은 Weight norm을 제한해주지만, covariance / variacne regularizer처럼 명시적인 모양을 조절하는 것은 아니기 때문에 위의 그림에서도 큰 모양차이가 안나는 것을 볼 수 있다.
2020
Statistical Characteristics of Deep Representations: An Empirical Investigation
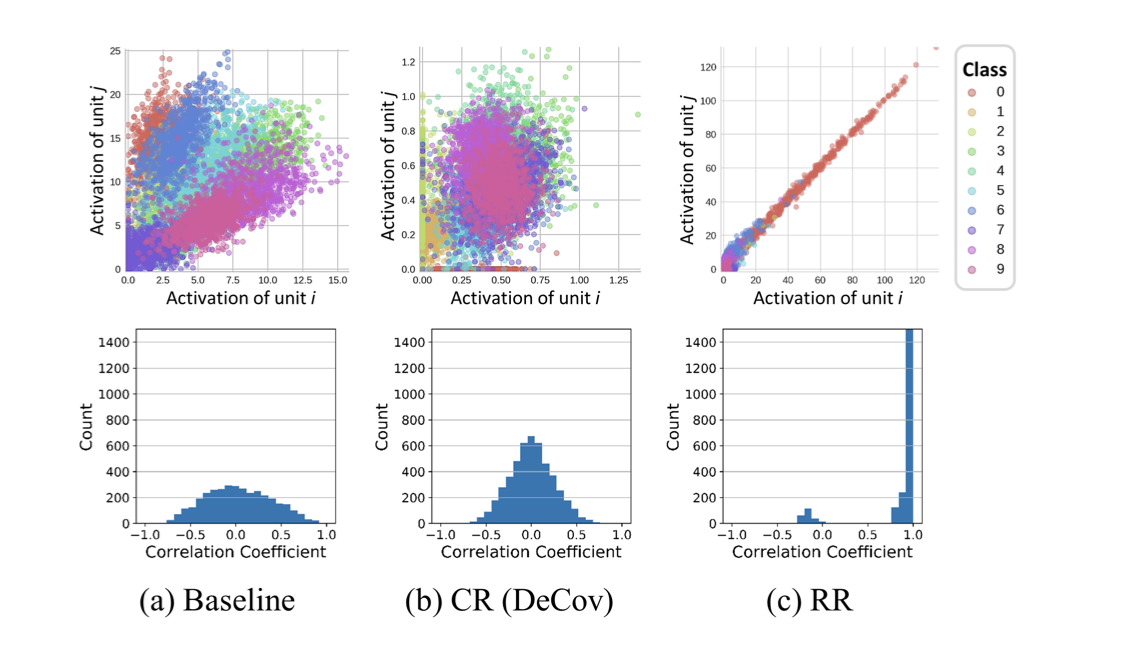
-
8가지의 representation regularization 방법을 소개한다(그 중 2가지는 새로운 방법 - Rank Regularization).
-
representation의 통계량(correlation, sparcity, rank)등은 학습 도중에 의도한대로 조작(manipulate)할 수 있음을 보여줌.
-
간단히 이런 representation regularization을 적용함으로써 baseline 성능을 향상시킬 수 있었음(+fine-tuning)
-
단, representation 통계량과 성능과의 관계는 일정하지 않았던 것 같음.
-
즉, representation 통계량을 만짐으로써 성능을 향상시킬 수는 있었지만 learning dynamics의 변화나 fine-tuning의 효과로 인한 간접적인 방식으로만 가능했음.

-