Spelling Correction, Noisy Channel Model, State of the Art Systems
1. Spelling Correction
이름에서 보다시피 검색, 자판, 문서작성 등 여러 곳에 쓰이는 '철자 바꿔주기(제안해주기)' task입니다.
- Spelling Error Detection
- Spelling Error Correction
- Auto Correct
- Suggest words...
보통 spelling error는 두 가지로 나눌 수 있습니다.
- Non-word Error
- 영어의 단어가 아닌 경우.
- graffe -> giraffe
- Real-word Errors
- 영어 내에 실제로 쓰이는 단어인 경우
- Typographical error(오타)
- three -> there
- Cognitive Errors (homophones - 동음이의)
- piece -> peace
- too -> two
- 특히 음성인식할 때 많이 쓰일 듯.
Non-word spelling errors
Non-word Spelling Error는 어떻게 찾을까요?
단순하게 생각했을 때, 사전을 이용해서 찾을 수 있습니다.
크기가 너무 방대해서
그리고 나서, 다른 단어로 Correct해줄 때에는 그 단어와 가장 유사한 단어를 추천해주면 됩니다.
유사도(즉, Error)는 이전에 다뤘었던 string similarity 관련 기법들을 이용해서.
(Shortest weighted Edit distance, etc)
여기서는 noisy channel probability model에 대해서 다룰 것입니다.
Real-word spelling errors
이 또한 비슷하긴 합니다.
다만, 사전에 없는 단어 뿐만 아니라 모든 단어에 대한 candidate set을 생성해야 합니다.
특히, 비슷한 발음(동음이의어)에 따른 후보들과, 비슷한 문자(오타 등)에 따른 후보들을 각각 생성해야 합니다.
당연히 비슷한 단어들 뿐만 아니라 기존의 단어 자체도 후보에 포함시켜야 합니다.
(거의 대부분의 상황에서 기존의 단어를 사용할 것이기 때문에)
그 후에는, Noisy channel이나 Classifier를 사용해서 정해진 후보 중 제일 그럴싸한 단어를 고르면 됩니다.
Noisy Channel Intuition
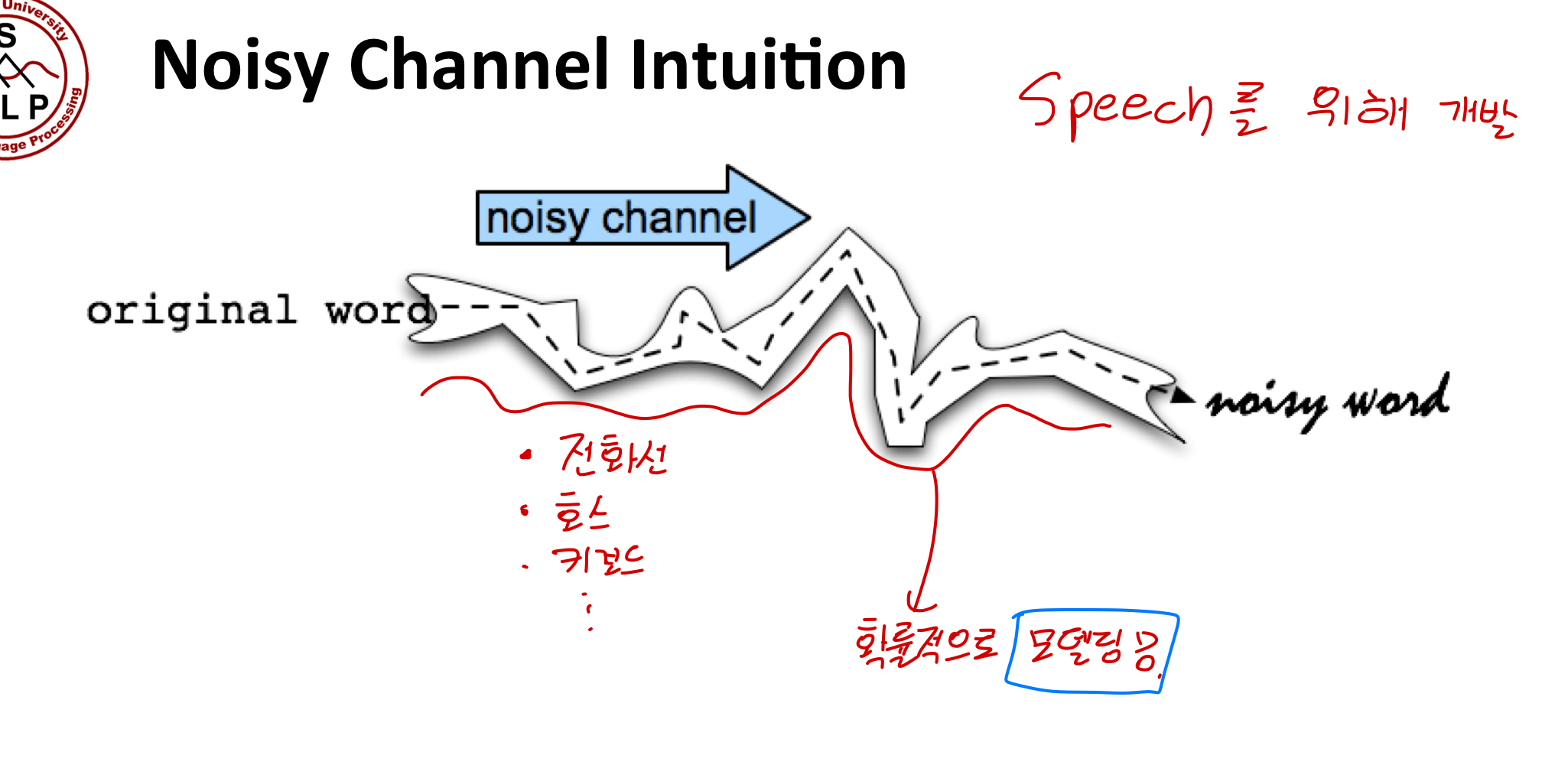

글자 acress를 기준으로 생각해봅시다.
Generate candidates
- 비슷한 철자(spelling)을 지닌 단어들
- 비슷한 발음(pronunciation)을 지닌 단어들
일단 발음은 일반적인 spell check 상황에선 잘 안 쓰이므로(음성인식 등 제외) 비슷한 철자를 가진 후보들에 초점을 맞춰봅시다.
similar spelling
이에는 기존에 다뤘던 Minimal edit distance가 있습니다.
다만, 일반적으로 Spelling correction 관련 task에서는 한 문자를 다른 문자로 대치하는 것 외에도 두 문자가 서로 위치가 뒤바뀌는 경우(e.g., magic -> magci)가 많기 때문에 이 순서를 원상복귀해주는 연산까지 포함해준 edit distance를 사용합시다(Damerau-Levenshtein edit distance).

역시 연산은 동적 프로그래밍으로 계산.
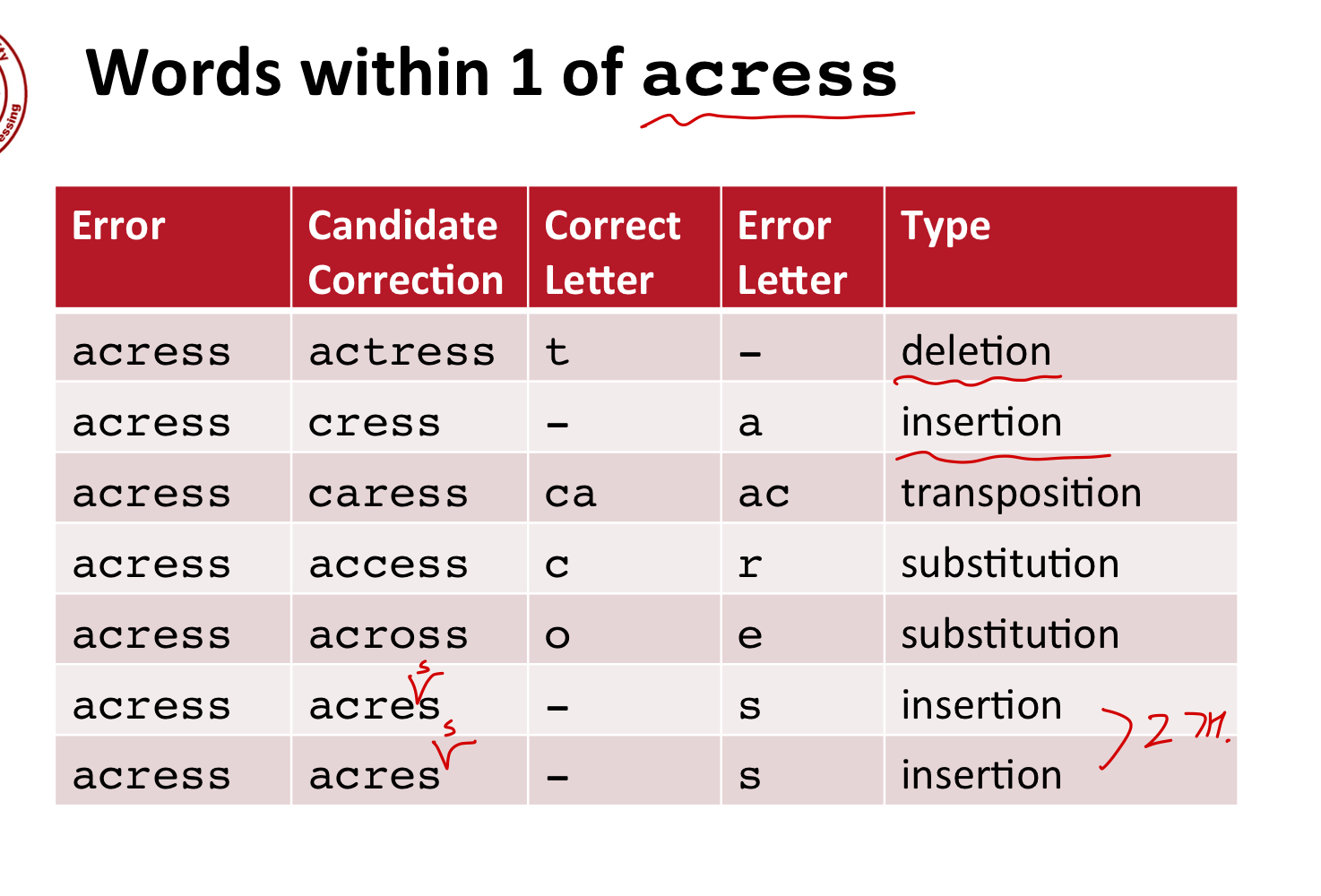
특히, 대부분의 오타가 edit distance 2 이하에서 일어난다고 합니다.

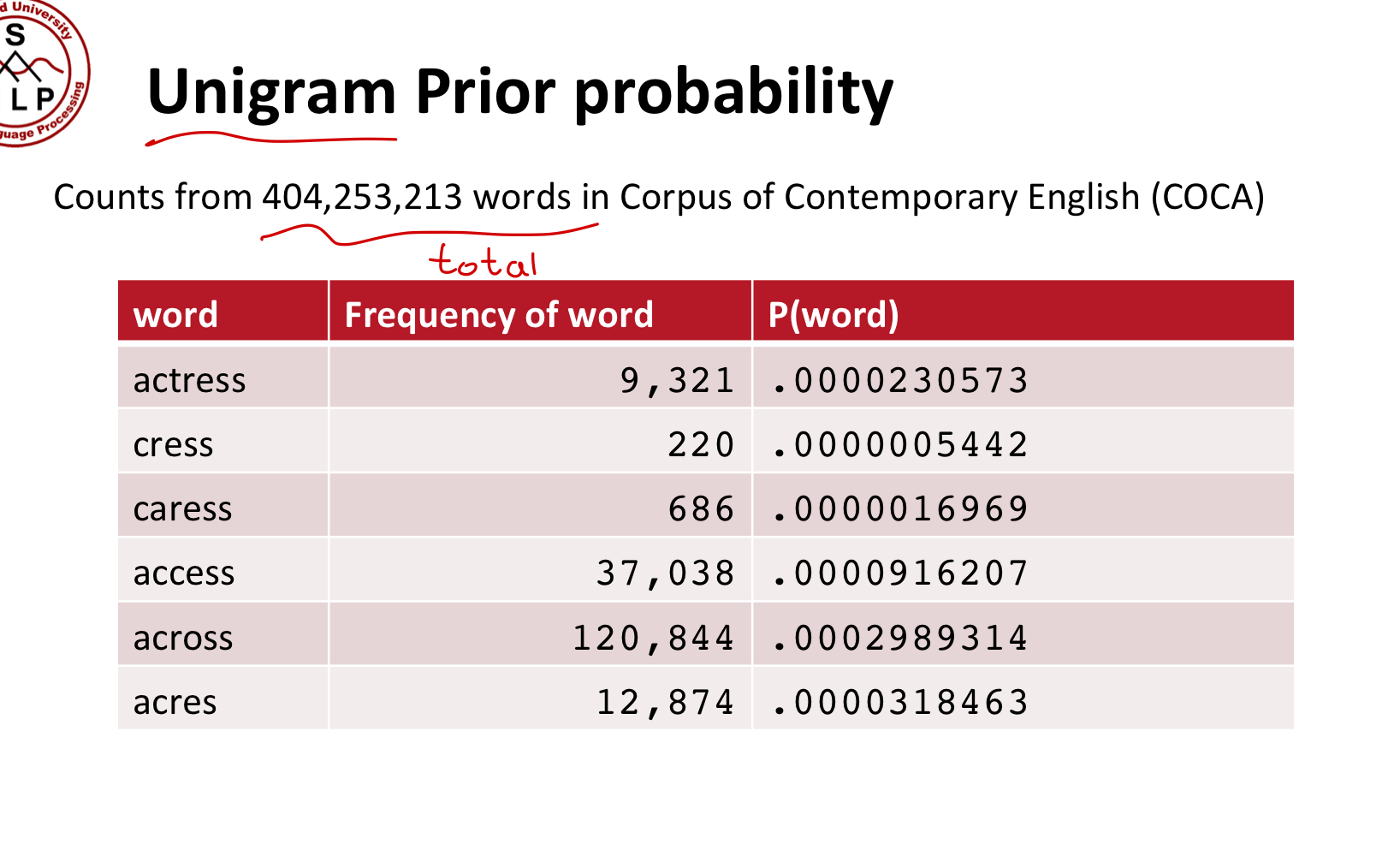
Prior model(Language Model)은 적당히 확률을 구하면 된다.
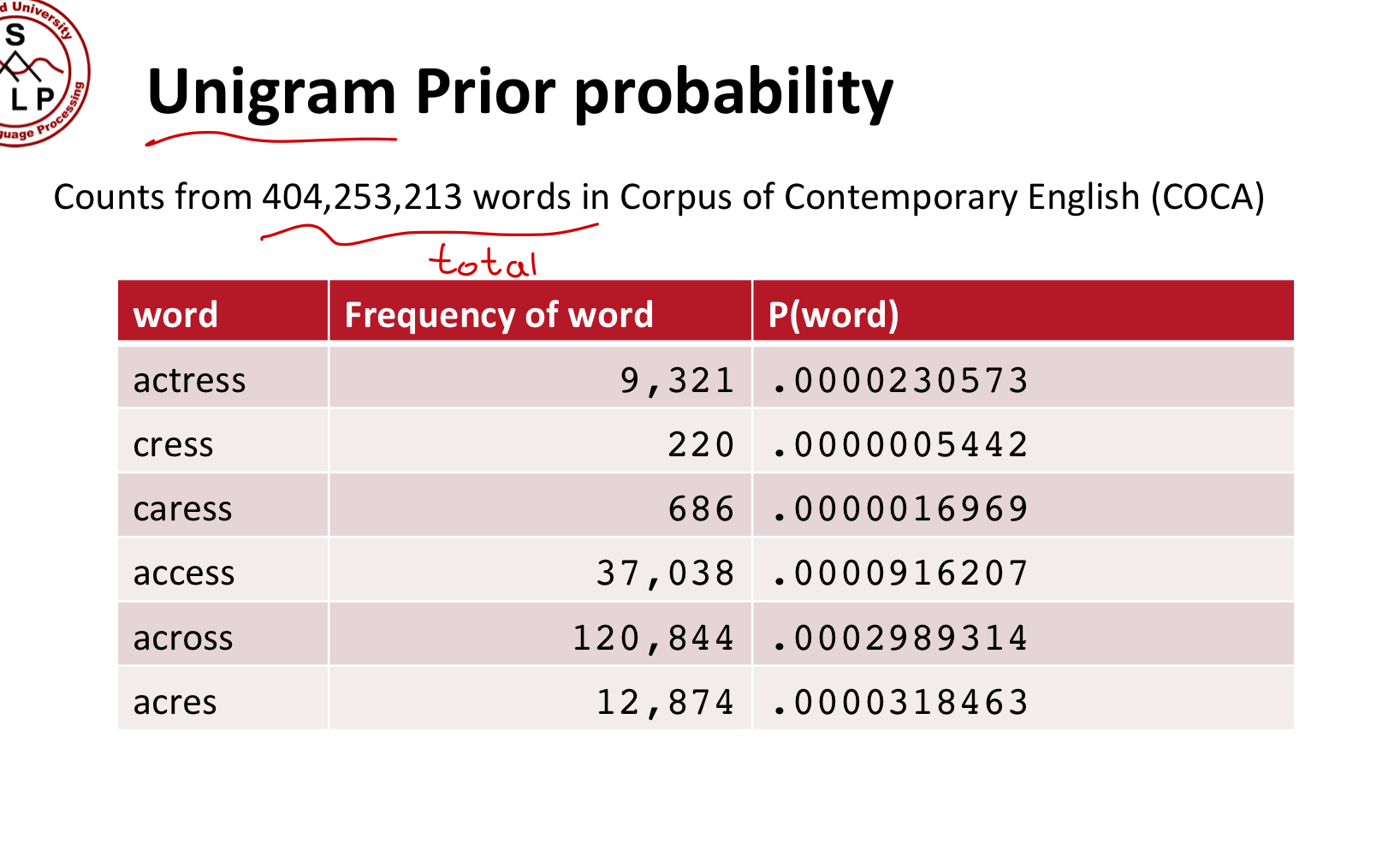
Channel model probability
Channel Model을 다루어봅시다().

모든 pair에 대해 confusion matrix를 계산할 수 있습니다.
그러면, 아래와 같이 행렬을 파악할 수 있습니다(일단 Substitution).

즉, 연산마다 confusion matrix를 계산할 수 있습니다.
다만, delete 연산과 insertion 연산 등은 연산 기준이 되는 두 단어가 다르기 때문에 아래와 같이 계산해줍니다.

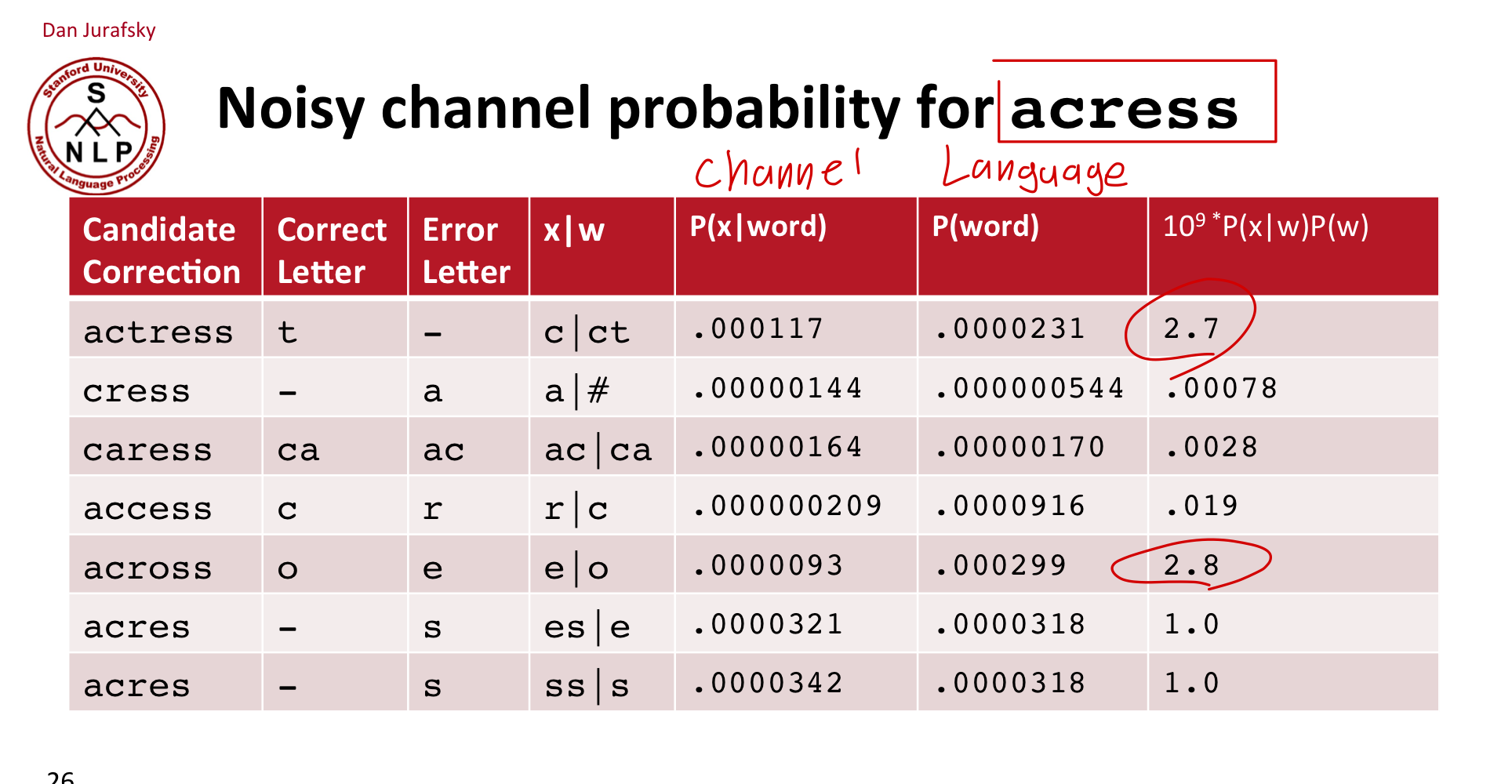
그래서, 정답은 뭐였을까요?
사실, 위의 방법들은 모두 맥락을 고려하지 않은 single-word correction입니다.
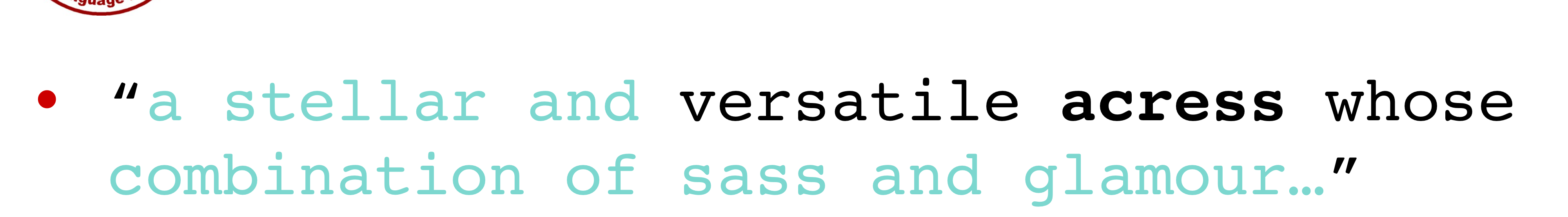
위와 같이 맥락을 이용한다면, Language Model을 사용해서, across인지 actress인지 쉽게 파악할 수 있습니다.

앞, 뒤 맥락을 각각 Bi-Gram 모델을 사용해 계산할 수 있습니다.
(당연히 앞, 뒤 맥락을 동시에 고려하는 모델도 있겠죠)
평가는 여러 사이트가 제공.
Real-world Spelling Corrections
