[간단정리]Comparing Kullback-Leibler Divergence and Mean Squared Error Loss in Knowledge Distillation(IJCAI 2021)
Knowledge Distillation

Paper: https://www.ijcai.org/proceedings/2021/0362.pdf
-
대규모 teacher model의 지식/정보를 가벼운 student model에 전이시키는 Knowledge distillation(KD) 방법이 효율적인 아키텍처 구성을 위해 널리 쓰이고 있다.
-
이를 위해 teacher model과 student model의 (softened) probability distribution 사이에 KL-발산을 이용해 차이를 줄이는 방향으로 규제를 주곤 한다.
-
근데, 실제로 이 softness의 정도()에 대한 연구는 별로 수행되지 않고 있다.
-
저자들은 이에 집중해 이론적으로 가 0으로 갈 때는 label matching에 가까워지고, 가 증가할 때는 logit matching에 가까워지는 것을 보이고, 이 logit matching이 전반적으로 성능 향상에 유리하다는 것을 보였다.
-
특히, 이런 결과들로부터 영감을 받아 final layer의 (softened) probability distribution간 KL-발산을 줄이는 대신, penultimate layer의 logit 간 MSE loss를 줄이게끔 학습해 더 좋은 결과를
- 즉, teacher model의 logit을 다이렉트하게 배운다 ! 어느 정도 마지막 feature representation 정보를 적극적으로 받아들인다 생각하면 될 듯 하다.
직관적으로, 위에서 말하는 softened probability distrubtioin은 아래와 같은 식으로 생성된다.
단순하게 생각한다면, 위 식의 가 커질수록 input logit 는 작아진다.
softmax는 exponential function이기에 input value가 조금만 커져도 영향력이 빠르게 증가하는데, 이를 강제로 없애주는 것.
즉, (softmax) probability distribution이 uniform distribution에 가까워질 것().
그렇다면 모델이 이런 output distribution을 가지고 Ground truth label()과 비교를 한다한들, 어떤 정보를 얻을 수 있을까?
이렇게, label distribution에 제약(softness)을 줄수록 모델은 (어차피 의미가 없으니)label에 대한 예측을 더 잘하기 보다는, input logit을 맞추는데 더 초점을 둘 것이고, 그렇기에 가 증가하면 logit matching에 가까워질 것임을 예상할 수 있다.
(물론 Hinton의 origianl paper에서는 정도로 설정했지만, softmax에서는 이정도 계수만 해도 큰 영향을 끼친다)
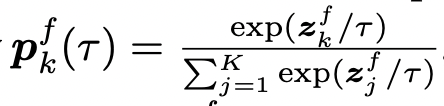
Contribution
- KD에서 softening hyperparameter인 에 대한 이론적인 분석(logit matching vs label matching)
- 위의 관찰로부터 KL-divergence loss를 대체하는 direct logit matching (MSE) loss 도입.
- KL-divergence loss는 penultimate layer(softmax 이전)의 representation(logit?)을 가늘게 하는 반면, MSE loss는 이런 현상을 보이지 않음.
- softmax 이전의 representation을 다이렉트하게 배우는 MSE loss에 비해 적당히 softmax distribution 간의 거리만 줄여도 되는 KL-Divergence loss는 다채로운(즉, high variance를 갖는?) representation을 배울 필요성을 못느낀다고 보면 될듯.
- 특히, teacher와 student간의 capacity gap이 클 경우 KL-divergence loss를 이용해 학습한 다음, MSE-loss를 이용해 이어서 학습하는, Sequenctial distillation 학습을 하는 게 더 효과적이었음.
- 단, label에 노이즈가 많을 수록 Direct하게 logit matching을 배우는 MSE Loss보다 소극적으로 배우는 (가 낮은) KL-divergence loss를 쓰는게 bad training의 악영향을 조금 줄이긴 함.
