[논문정리] Epidemic Spread Modeling을 위한 여러 연구들(메모)
원 글 작성일 : 2020-10-29
주의!!
본 글은 개인 연구용으로 마구잡이로 메모한 것이기에 참고하기엔 좋지 않습니다.
1.Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions
- 기초재생산지수(R0)을 어떤 식으로 추정했는지.
Transmission model
- SEIR모델을 사용했으며, Poisson-distributed daily time increments라 가정하였다.
가정
- 사람, 사람 간 전염
- 매점 폐쇄, not 동물성 감염.
추정
- 잠복기 : 4일 (SARS의 잠복기로 사ㄷ용 – 기존 연구에서 4.4일로 추정)
- 하루 당 생기는 평균 확진자를 나타내는 ODE 시스템을 다룸으로써 Fitting을 하였다. 또한 신규 확진자의 수는 이 평균 근처에서(Approximately) 푸아송 분포를 따른다고 가정.
- 또한, parameter inference는 Nelder-Mead optimization을 이용한 MLE를 사용했다. (R의 opti() – R..
※ parameter estimation의 불 확실성 ?
- parametric bootstrap을 이용해 탐구함.
- 1만개의 Monte Carlo 시뮬레이션을, MLE estimate of parameter를 이용해 생성
- 이 생성 된 dataset을 model과 다시 re-fitted해 parameter의 결합 표본 분포를 생성하고 95%의 신용도로 추정함.
- 예측 된 mean epidemic 주변 95% 신용구간을 만들기 위해 sampling distribution를 통해 계속 ODE System이 실행됨.
2. Preliminary estimation of the basic reproduction number of novel coronavirus (2019-nCoV) in China, from 2019 to 2020: A data-driven analysis in the early phase of the outbreak
- 기초 재생산 지수(R0)을 어떻게 추정했는지
방법
- EXPONENTIAL GROWTH(지수 성장)을 통한 전염병 곡선을 모델링
- Intrinsic growth rate(γ)와 함께 메르스와 사스의 serial intervals(SI)를 이용해 안 알려진 SI의 추정치로서 사용함.
- time-varying reporting rate를 이용함(선형증가로 가정) – 이전 연구 존재
- ~ 어떤 변수를 가정할 때 그냥 사회적 상황에 맞게 알아서 가정함.
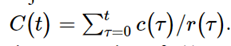
- 보고를 3일만에 40명으로 쳤다면, 신규 확진자는 13.3명으로 보는게맞음.
※ Reporting rate : 완전히 기대값을 기반으로 생성되는, report의 비율
즉, 이는 완전한 data set을 눈으로 봐 계산하는 것.
아무튼, 전염병 모델로 지수 곡선을 선택했다.
- Nonlinear least square framework가 data fitting과 parameter estimation을 위해 채택됨.
- growth rate(γ)는 추정됐고, R0 또한 R0=1/M(-γ) 를 통해 얻어짐.
(물론, 100%의 전염가능성을 가정했을 때)
여기서, M(): 라플라스 변형, 즉 SI(Serial interval)의 확률분포의 MGF(적률생성함수)이다. 이는 h(k) , k는 평균 SI일 때.
또한 ,H(K)를 감마 분포로 가정했다(7.6의 평균과 3.4일의 표준편차를 가진 메르스와 8.4일, 3.8일)을 가진 사스를 기반으로.

또한 여기서 k-fold 교차 검증이 나온다.
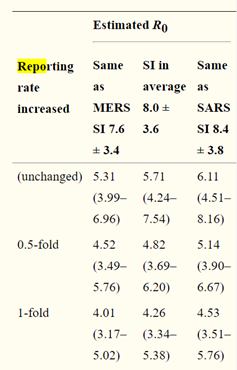
결과와 토론
알 것 : Nonlinear least square framework
위에 나온 M(*) : 라플라스 변형의 이론. (MGF)
SeRIAL INTERVAL
3. Parameter Estimation of Various Hodgkin-Huxley-Type Neuronal Modesl Using a Gradient-Descent Learning Method
개요
Doya et al에 의해 고안된 automatic parameter identification (Hodgkin_Huxley type equation의 )을 탐구함.
더욱 개선 된 estimation 방법을 제안하였고, 이러한 방법은 HH-type equation의 parameter 추정의 어려움을 풀었다.
이는 복잡한 membrane(막) potential wave form suach as a chaotic butrsting과 같은 모습을 보여줌으로써 estimation 속도를 올려주었다.
- 다만, 이는 논리회로에서의 HH-EQUATION에 관한 얘기라서 다른 얘기로 직접적인 참고를 하는게 나을듯하다.
4. A mathematical model of the COVID-19 pandemic dyanmcis with depende....
- parameter 추정한 방법.
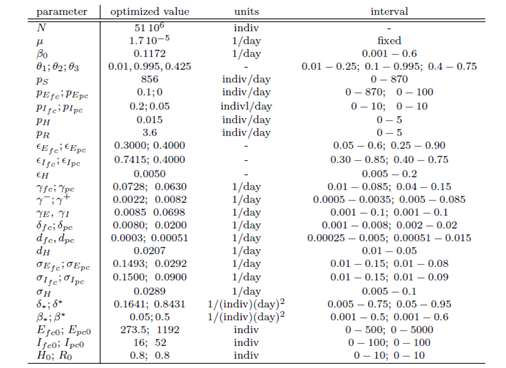
matlab에서 ode 45 solver를 사용했고 , fmincon constrained optimization routine이 쓰였다.
(여기선 l1 norm)
※ ode45 solver ?
- initial parameter를 정한 후 SGD를 통해서 Parameter의 optimization이 이루어지지 않는다면, 어떻게 Moore-Penrose opti로 multi-step problem을 풀 수 있는 건지 ?
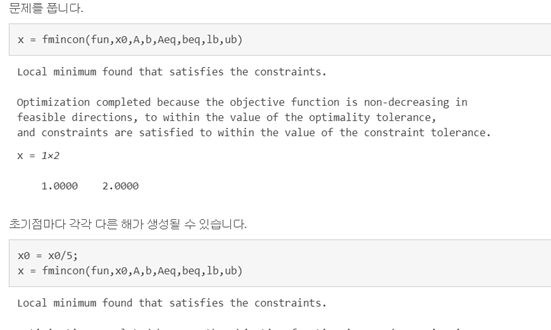
- 어떤 opti 문제건 초기값마다 다른 점이 생성될 수 있음.
- optimization function들의 특징을 눈 여겨 보아야 함.
5.A novel sub-epidemic ..
https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-019-1406-6
- 기존 연구 : (parameter estimation)
https://www.sciencedirect.com/science/article/pii/S2468042717300234
https://www.sciencedirect.com/science/article/abs/pii/S0022519305005096



(parameter 5개에 대한 time-series)

(일련의 함수 정의에 따른 parameter들 설정)
trust

평균을 낸다 ?? 이런식으로 해도 되는지.
PARAMETER의 신용도(95%)가 Parametric bootstrap을 통해 얻어지는 것
이 과정에서,
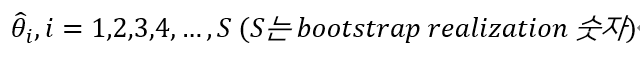
를 통해 이것들이 만들어지며, 이는 95% 신용구간을 써먹기 위해 쓰임.
(예측 자체가 정확한 값이 아니기 때문에 이러한 추정값과 같이 전달되면 아주 좋다.
6. Forecasting COVID-19 pandemic: A data-driven analysis
https://www.sciencedirect.com/science/article/pii/S0960077920304434
- 과 마찬가지로 Trust-region-reflective algorithm을 사용.
(best parameter를 찾기 위해)
※ Trust-region-reflective algorithm이란
Trust-region-reflective algorithm is one of the robust least-squares optimization techniques that can promote a fine relation between model driving mechanisms and model responses. This real-time data-fitting approach could be efficient enough to provide considerable insights on disease outbreak dynamics in different countries and design worthwhile public health policies in curtailing the disease burden. Calibrating our model parameters by using the above algorithm, we have provided probable forecasts for the emerging COVID-19 hotspots.
이 알고리즘을 사용하면, 다양한 상황에서 역학시스템을 잘 표현할 수 있음.
(결국, least-square optimization technique임
least-sqaure-optimization techniques
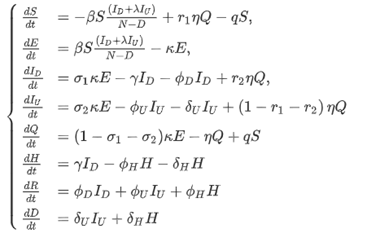
- 이 논문의 모델.
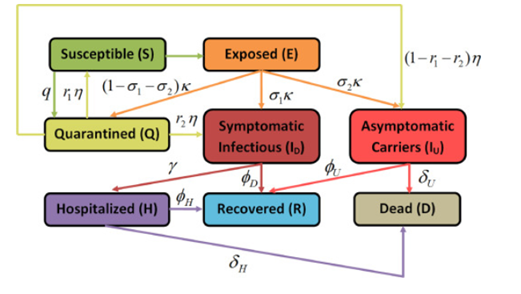
Using the next generation operator method [24] the local stability of disease free equilibrium (DFE ) has been investigated.
(감염의 평형상태도 탐구함)
- Model calibration(모델 교정)
- 여기선 continuous모델이고, matLAB의 LSQCURVEFIT란 함수를 이용한 Opt를 진행함. (TRR – Trust-region-refletive).
일반적으로, MATLAB의 OPTIMIZATION TOOLBOX는 NON-LINEAR LEAST SQUARE PROBLEM을 푸는데 많이 이용 됨. - OPTIMIZATION 과정은 다음과 같이 이루어져 있다.
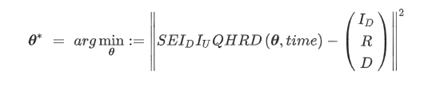

parameter의 초기값들.
TRR 알고리즘은 parameter 초기값들의 추정도 이루어 져야함.
여기서도, 거의 대부분의 optimization은 paramter의 초기값을 정의하는 것으로부터 시작 됨을 알 수 있다.
- 선형회귀+,MSE의 경우 CONVEX
단, 선형회귀가 아닌 SEIR-REGRESSION이라면 그리딩을 하지 않는 이상 선형일 수는 없을 것.-비선형 경사하강법 ?
하나의 전역 최솟값만 존재 하지만
비선형문제의 경우 초기값에 따라 다양한 로컬민에 도달할 수 있음.
즉, 내 모델의 경우 GRIDDING을 통해 선형으로 만들어버리면 무어-펜로즈 유사역행렬을 이용해 최적값을 구할 수 있으며, 선형으로 만들지 않을 경우 비선형 최적화를 사용해야 함.
단, 시계열이기 때문에 각각의 TIME-POINT에서 구한 PARAMETER들을 어떤 식으로 선택할 지는 다양한 논문을 통해.
¬- 결국 ,MOORE-PENROSE는 SVD분해를 이용하는 것이고
특성이 적은 경우에 적절하다고 볼 수 있다.
GRADIENT DESCENT의 의의
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
