앞 내용이 궁금하신 분들은,,,
Glow-tts 코드리뷰 2편을 보고 오시면 됩니다.!
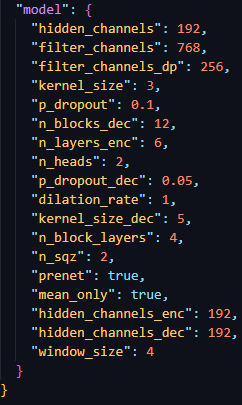
■ Train.py (input)
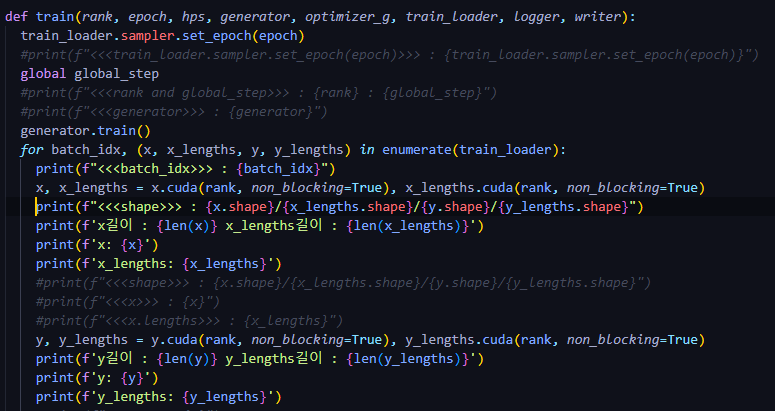
- batch size : 16

-
x.shape : torch.Size([16, 115])
- batch size 16개, text token 최대 길이 115
- 115 길이에 맞추고 그보다 작은 데이터들은 0으로 padding 채움
-
y.shape : torch.Size([16, 80, 493])
- batch size 16개, mel size 80
- mel 최대 길이 493에 모든 데이터를 맞추고 그보다 작은 데이터들은 0으로 padding
-
x_lengths : 텍스트 길이 정보(sorting 결과, 긴 결과부터 출력됨)
-
y_lengths : 오디오 길이 정보(sorting 결과, 긴 결과부터 출력됨)
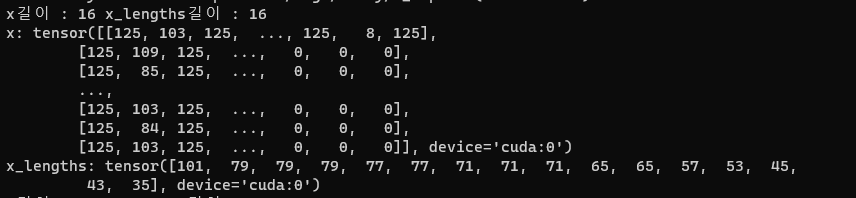
x : text
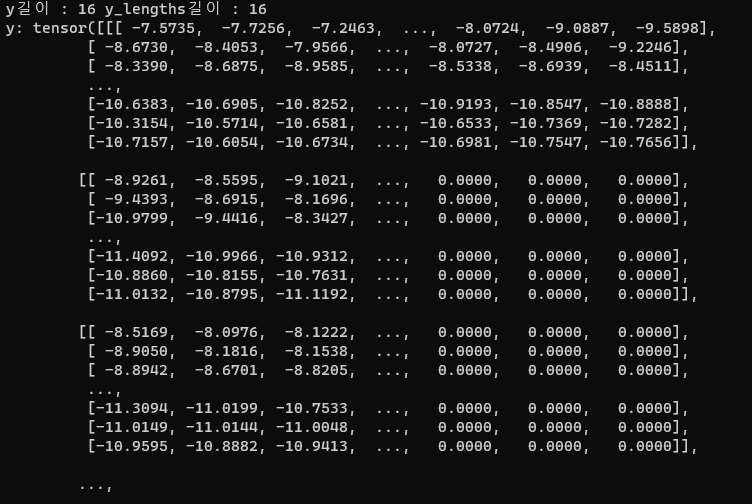
y : mel
TextEncoder
0. Embedding()
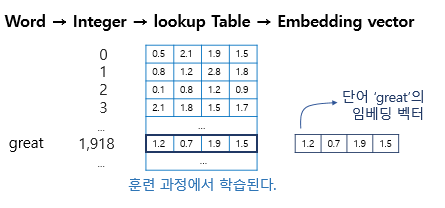
⚽ 참고 자료 : https://wikidocs.net/64779
1. convReluNorm()
- Conv1d → LayerNorm → relu → dropout → Conv1d (if proj, true)
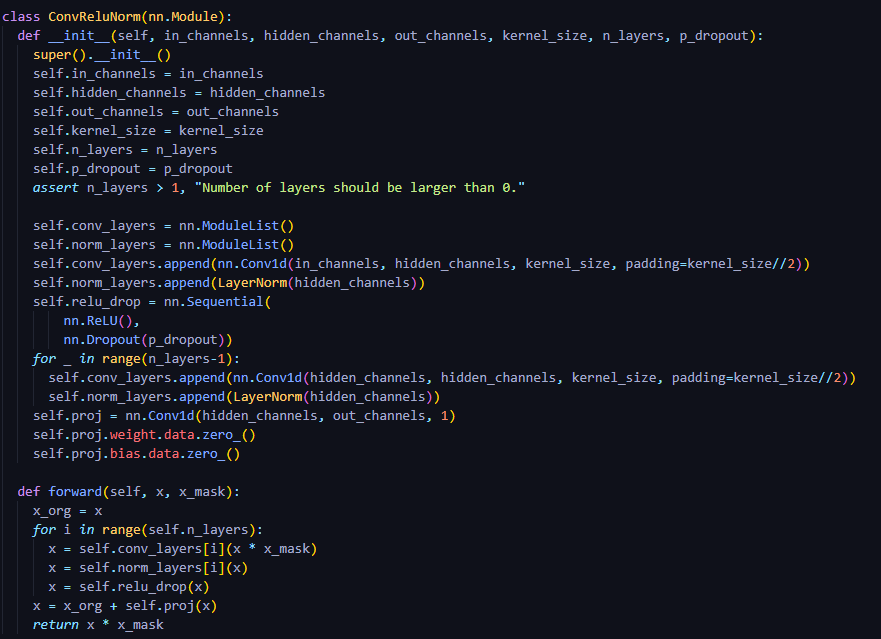
(encoder): TextEncoder(
(emb): Embedding(126, 192) # 125개 token + blank token = 126개 / 192 : hidden_channels_enc
(pre): ConvReluNorm(
(conv_layers): ModuleList(
(0): Conv1d(192, 192, kernel_size=(5,), stride=(1,), padding=(2,))
(1): Conv1d(192, 192, kernel_size=(5,), stride=(1,), padding=(2,))
(2): Conv1d(192, 192, kernel_size=(5,), stride=(1,), padding=(2,))
)
(norm_layers): ModuleList(
(0): LayerNorm()
(1): LayerNorm()
(2): LayerNorm()
)
(relu_drop): Sequential(
(0): ReLU()
(1): Dropout(p=0.5, inplace=False)
)
(proj): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)

nn.ModuleList()를 쓰는 이유-
nn.ModuleList안에 Module을 넣어줌으로써 Module의 존재를 PyTorch에게 알려준다.
-
만약 nn.ModuleList에 넣어 주지 않고, Python list에만 Module들을 넣어 준다면, Pytorch는 Module의 존재를 알지 못한다.
-
model.parameter()로 파라미터를 넘겨줄 때, 에러가 발생하게 된다.
-
Module을 nn.ModuleList로 wrapping 해준다고 생각하면 된다.
-
nn.Conv1d()
-
proj_m : Conv1d
-
출력값
-
in_channels : input의 feature dimension
- time step마다 feature dimension이 들어옴
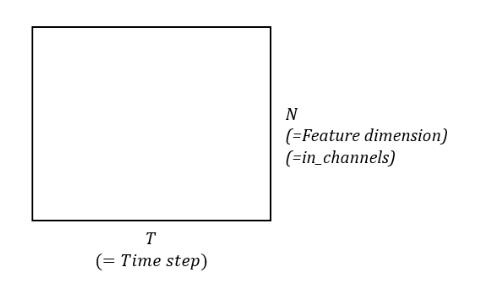
- time step마다 feature dimension이 들어옴
-
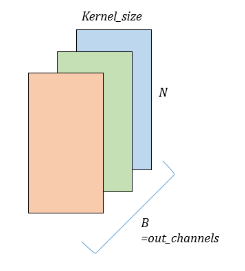
out_channels : output으로 내보낼 dimension
-
1D Conv의 경우, width가 Kernal Size 즉, Time 도메인이 됨
-
그런 kernel을 out channels 개수만큼 생성하여 conv 연산을 진행하게 됨
-
-
stride : kernel이 몇 칸을 띄면서 적용될 지 설정
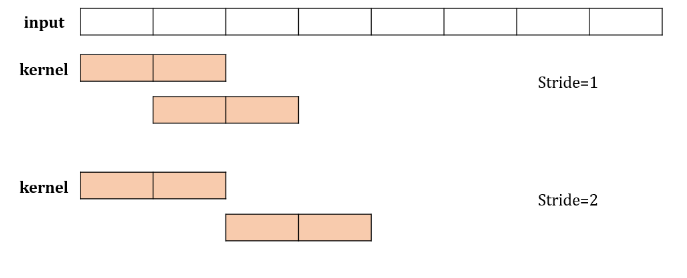
-
dilation : kernel 내부에서 몇 칸을 띄면서 볼 것인지 설정
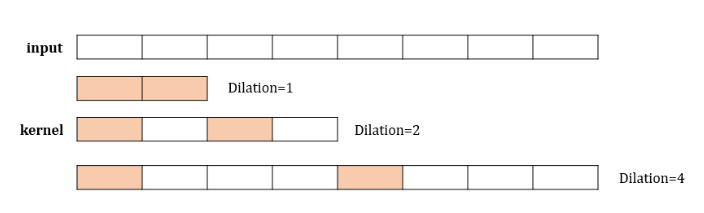
-
groups : kernel의 height를 조절(Default : 1)
- output channel과 input channel을 같게 맞추고 channel을 잘라서 conv 연산을 적용
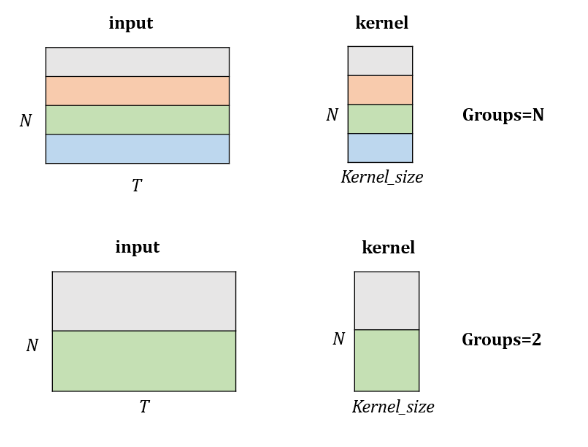
-
⚽ 참고 자료 : https://sanghyu.tistory.com/24
내용이 길어져서 다음 편에서 Encoder 부분을 이어서 정리하도록 하겠습니다. 읽어주셔서 감사합니다. 😀
