ASR
1.Hifi-gan 논문 리뷰

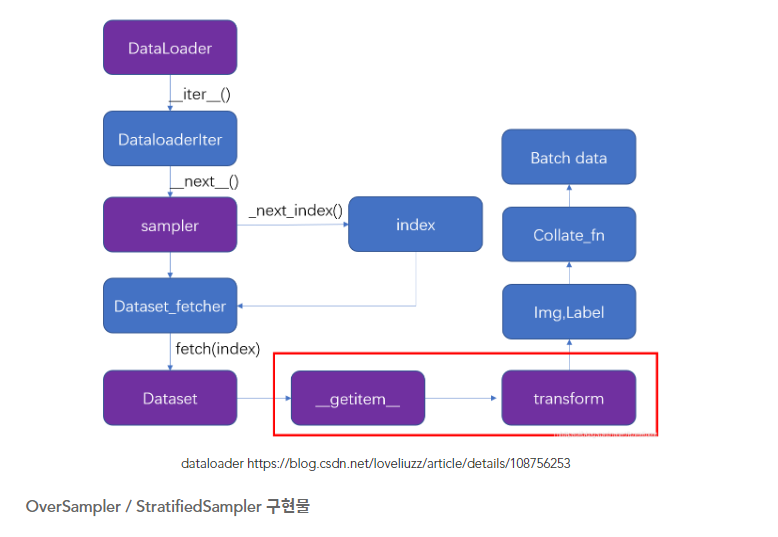
음성인식은 두 단계로 이루어져 있음Text → Mel-spectrogramMel-spectrogram → waveformvocoder는 두 번째 단계를 실행함Auto-Regressive Generative model - WaveNet학습과 추론 시간이 오래 걸림Flow
2.Glow-TTS 한국어로 학습하기
class FlowGenerator_DDI(models.FlowGenerator) : models.py 라이브러리에서 import한 모듈, init 부분을 상속 받아 모델에 변수들을 넘겨주는 부분, models.py에 FlowGenerator_DDI 부분을 보면 tor
3.Glow-TTS 한국어로 학습하기 2편

앞 내용이 궁금하신 분들은,,,Glow-tts 코드리뷰 1편을 보고 오시면 됩니다.!최대한 비슷하게 따라가며 흐름을 파악할 것발생한 에러들cuda 전용 pytorch 버전 충돌 문제smart-g2p 사용 시, 01012345678과 같은 핸드폰 번호를 제대로 읽지 못하
4.Glow-TTS 한국어로 학습하기 3편
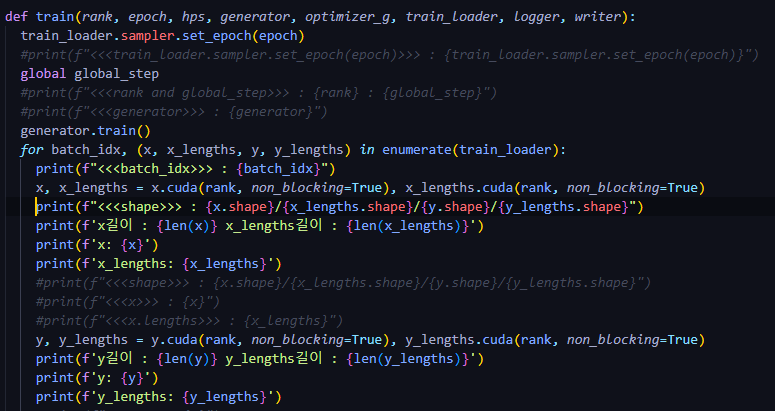
앞 내용이 궁금하신 분들은,,,Glow-tts 코드리뷰 2편을 보고 오시면 됩니다.!batch size : 16x.shape : torch.Size(16, 115)batch size 16개, text token 최대 길이 115115 길이에 맞추고 그보다 작은 데이터
5.Conformer 모델 리뷰
① 정확한 음성 인식을 위하여 음성 인식 알고리즘 중 높은 정확도와 성능을 보이는 Conformer(2020년 5월 발표) 알고리즘을 적용 (표. )Conformer는 SOTA 성능을 보여준 Transformer와 CNN 기반의 모델들보다 훨씬 뛰어난 성능을 가져옴.
6.PyAudio 사용하여 Streaming 데이터 주고받기
사실 Kaldi의 portaudio를 사용하려고 하였다.하지만 Kaldi의 경우, C코드이기때문에, portaudio가 Python으로 wrapping되어있는 pyaudio를 사용해보려고한다.PortAudio: Main PagePyAudio간단한 설치 방법은,최소한 p