앞 내용이 궁금하신 분들은,,,
Glow-tts 코드리뷰 1편을 보고 오시면 됩니다.!
4. 구현 中 발생한 문제 해결
-
최대한 비슷하게 따라가며 흐름을 파악할 것
-
발생한 에러들
-
cuda 전용 pytorch 버전 충돌 문제
-
smart-g2p 사용 시, 01012345678과 같은 핸드폰 번호를 제대로 읽지 못하는 문제
→ 승혁이형의 num_to_text.py 이용해서 전처리 후 g2p(mixed(smart-g2p,g2pk,Kog2p) 거쳐서 전처리
-
Sampling Rate 문제
→ 모델 sr의 경우 22050이지만 KSS데이터의 경우 44100, 이에 따라 데이터의 SR을 변경해줘야함. 앞으로의 모델 학습 과정에서도 전처리 시 체크할 것
-
Audio Channel 문제
→ glow-tts 내부 엔진에서 오디오 파일은 모노 타입, 즉 1차원의 채널만 input으로 처리함. 하지만 KSS데이터의 경우 스테레오 타입의 2 channels 데이터임. 따라서 Channel도 전처리 시 체크할 것,
→ Audio 파일의 다른 요소들도 체크하며 학습 준비할 것
-
Tokenization 문제
→ Glow-tts 내부 구조를 제대로 파악하지 못함
-
text/symbols.py : symbol 리스트에 영어 또는 한국어(외국어)를 최소 단위로 구성하는 모듈
Defines the set of symbols used in text input to the model.
The default is a set of ASCII characters that works well for English or text that has been run through Unidecode. For other data, you can modify _characters. See TRAINING_DATA.md for details
-
text/cleaners.py : input 텍스트에 대해서 g2p 라이브러리를 활용하여 phone단위로 변환하든지 발음 매핑하고 싶은 최소 단위로 쪼개는 모듈
Cleaners are transformations that run over the input text at both training and eval time.
Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
hyperparameter. Some cleaners are English-specific. You'll typically want to use:
1. "english_cleaners" for English text
2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
the Unidecode library (https://pypi.python.org/pypi/Unidecode)
3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
the symbols in symbols.py to match your data).
-
text/init.py : cleaners.py, symbols.py, numbers.py, cmudict.py 의 모듈들을 활용하여 텍스트 토크나이징 하는 모듈 ⇒ text_to_sequence 모듈 활용
c-1. text_to_sequence function *Converts a string of text to a sequence of IDs corresponding to the symbols in the text.* *The text can optionally have ARPAbet sequences enclosed in curly braces embedded* *in it. For example, "Turn left on {HH AW1 S S T AH0 N} Street."* *Args:* *text: string to convert to a sequence* *cleaner_names: names of the cleaner functions to run the text through* *dictionary: arpabet class with arpabet dictionary* *Returns:* *List of integers corresponding to the symbols in the text*   위 사진은 자,모음으로 분류한 사진, 실제 훈련은 phone단위로 수정해서 작업함.d. phone 단위로 문장을 변환하거나 매핑할 수 있어야 함
d-1. 기존에 알파벳 단위로 텍스트를 변환한 후, 토크나이징 했을 때, 정확도가 향상되지 않았다. 따라서 이를 조금 더 보완하고자 KoG2P모듈을 활용하여 Phone 단위로 변환하여 텍스트의 Token들을 매칭해주었다.
기존의 방법은 Text 패키지 안의
__init__에서 텍스트 변환 작업이 이루어진다.Text_to_Sequence모듈을 활용하는데cleaner를 거쳐서 나온 텍스트 중, 발음 사전(=cmu_dict)에 존재하는 단어인 경우 중괄호{}로 감싸 주어, 텍스트 토크나이징을 하고, 그렇지 않은 경우에는 영어이기 때문에 해당 알파벳에 맞는 토큰으로 토크나이징 해주었다.d-2. 한국어 glow-tts 모델을 구성하기 위해서, 약간 다른 방법으로 코드를 수정하였다. 먼저, 중괄호(={})를 씌워주는 이유는 문장을 phone 단위로 변환했을 때, 단어(=어절)별로 구분하기 어렵기 때문이다. 예를 들어,
'안녕하세요 저는 승재입니다.'이런 문장을 phone으로 변환할 때,'aa nf nn yv ng h0 aa s0 ee yo c0 vv nn xx nf s0 xx ng c0 qq ee yo'이런 식으로 변환이 된다. 따라서 어절별로 중괄호를 씌워, 구분을 할 수 있게 해줌으로써, 단어를 구분할 수 있고, 중간 중간에 띄어쓰기 토큰도 넣어줄 수 있어, 문장과 최대한 유사하게 토큰화 할 수 있다.import re import g2pk from .SMART_G2P.KoG2P.g2p import runKoG2P from .numtotextmodule import numtotext from .symbols import _letters_k g2p = G2p() numtotxt = numtotext() _punctuation = list('''"!\'(),.:;?''') _letters_k = list(_letters_k) # Regular expression matching (non phone) (phone) (non phone) _separated_punctuation_re = re.compile(r'([^가-힣]*)([가-힣]*)([^가-힣]*)') # Regular expression matching phone number _phonenum_re = re.compile(r'(010|02|051|053|032|062|042|052|044|031|033|043|041|063|061|054|055|064)(?:-)?(\d{3,})(?:-(\d{3,}))?') # Regular expression matching whitespace: _whitespace_re = re.compile(r'\s+') def phone_numbers(text): return re.sub(_phonenum_re, numtotxt.num_test_phone, text) def collapse_whitespace(text): return re.sub(_whitespace_re, ' ', text) def punctuation_cleaners(punc): temp = '' for _ in punc: if _ in _punctuation or _ in _letters_k: temp += _ return ' '.join(temp) def korean_g2p(word): res = '' cnt = 1 while len(word): m = re.match(_separated_punctuation_re,word) if m is None: break punc1 = punctuation_cleaners(m.group(1)) if cnt != 1: res += ' '+punc1 else: if m.group(2) is None: res += punc1 else: res += punc1+' ' g2p_word = runKoG2P(m.group(2),'text/SMART_G2P/KoG2P/rulebook.txt') res += g2p_word if len(m.group(3)) != 0: punc2 = punctuation_cleaners(m.group(3)) res += ' '+punc2 word = word.replace(m.group(),'') cnt+=1 if len(res) != 0: res = res.strip() return "{" + res + "}" else: return res def korean_cleaners(text): '''Pipeline for Korean text. Split Korean into smart-g2p -> kog2p -> phone''' phone_text='' text = collapse_whitespace(text) text = phone_numbers(text) #text = trans(g2p(text)) text = (g2p(text)) if len(text) == 0: return text phone_text = [korean_g2p(w) for w in text.split(" ")] return_text = ''.join(phone for phone in phone_text) return return_textdef text_to_sequence(text, cleaner_names, dictionary=None): sequence = [] space = _symbols_to_sequence(' ') origin_text = text text = _clean_text(text, cleaner_names) cleaned_text = text while len(text): m = _curly_re.match(text) if not m: clean_text = _clean_text(text, cleaner_names) if dictionary is not None: clean_text = [get_arpabet(w, dictionary) for w in clean_text.split(" ")] for i in range(len(clean_text)): t = clean_text[i] if t.startswith("{"): sequence += _split_phone_to_sequence(t[1:-1]) else: sequence += _symbols_to_sequence(t) sequence += space else: sequence += _symbols_to_sequence(clean_text) break if len(m.group(1)) != 0: sequence += _symbols_to_sequence(_clean_text(m.group(1), cleaner_names)) if len(m.group(3)) == 0: sequence += _split_phone_to_sequence(m.group(2)) else: sequence += _split_phone_to_sequence(m.group(2))+space text = m.group(3) # remove trailing space if dictionary is not None: sequence = sequence[:-1] if sequence[-1] == space[0] else sequence return sequence -
symbols.py의 korean이 계속 찍히는 이유와 이를 해결할 수 있는 방법
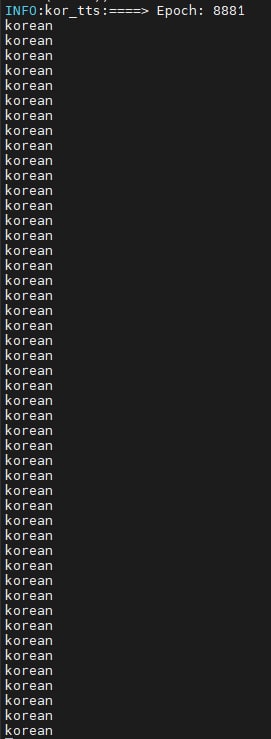
-
학습 시, 위의 사진과 같이 korean이 여러 번 찍히는 것이 이상했다. 위의 문자가 찍히는 순간 GPU 사용률이 0%이었다. 박사님께서 딥러닝 학습 시, GPU의 유휴시간이 최소화 되는 것이 자원 사용률 측면에서 중요한 포인트라고 말씀해주셨다.
조금 더 알아보니 위의 korean이 총 48번, 8번 이렇게 규칙적으로 출력되었다. 다른 방법으로도 디버깅 해보면서, GPU Multiprocessing에 관해 유추해볼 수 있었다.
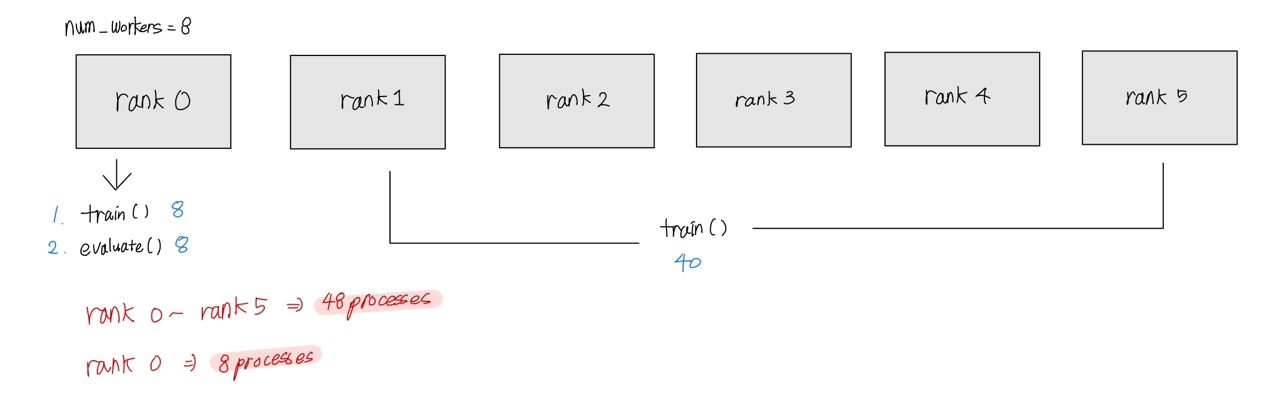
총 6개의 Multi GPU 환경에서 학습을 진행했다. glow-tts 내부 모델 안에서는 프로세스당 1개의 GPU를 할당해주고, parallel하게 작업을 진행하였다. train(), evaluate()함수 안에 각각 train_loader, validation_loader 가 인자로 포함이 되고, 이는 Dataloader 클래스를 계속 호출하게 된다. Dataloader 호출에 의해서 clearners와 symbols 같은 text관련 모듈들이 호출이 되고, symbols가 호출이 되면서 총 48번, 8번의 korean이 출력되는 것을 확인할 수 있었다.
multi-gpu, multi-processing 환경에서 GPU마다 분할해서 학습을 진행하고 각 weight값들은 nccl 통신을 통해, 갱신하는 구조이다.
또한, torch의 DataSet, DataSampler, Dataloader를 하나의 pipeline으로 구축하여, 데이터를 전처리하는 과정이 포함되어 있다. glow-tts에서는 매 epoch마다, Dataloader(=trainloader)를 호출해주며, 데이터를 랜덤 추출하며 갱신하는 구조로 이루어 진다. 이 과정에서 ‘korean’이라는 단어가 출력된 것이다.
이를 해결하기 위해 박사님께서 한 가지 방법을 제안해주셨다. 매 epoch 마다 데이터를 랜덤하게 load하는 것은 학습 차원에서 어쩔 수 없으나, data를 load할 때마다 cleaner와 같은 토큰화 관련 모듈이 수행되는 시간이 길기 때문에, 이 부분을 따로 모듈화 시키는 것을 추천해주셨다. 실제로 dataloader 과정에서 한글 텍스트를 phone으로 변환하고 phone에서 token으로 변환하는 시간이 꽤 소요가 되기 때문에, 애초에 이 과정을 모듈화 시킨 후, 독립적으로 구성하여 dataloader에서는 token으로 구성된 데이터만을 load한다면, 훨씬 더 효율적으로 학습을 진행할 수 있을 거라 예상한다.
다음편은 모델 내부구조에 대해서 이어서 리뷰해보도록 하겠습니다.
부족한 글 읽어주셔서 감사합니다.★★★★★ -
-
-
