[논문리뷰] Lexico: Extreme KV cache compression via sparse coding over universal dictionaries
Language Modeling
- Lexico: Extreme KV cache compression via sparse coding over universal dictionaries (ICML 2025)
Introduction
- KV cache compression을 위한 많은 노력이 지금까지 있었고, 이 논문에서는 key vector들이 low-rank subspace 하에 위치함을 보인 바 있다. 그러나, 모든 벡터가 같은 subspace에 위치하는지는 불분명하다.
- 따라서 이러한 redundancy를 해결하는 것이 KV cache 압축에 있어서 큰 도움이 될 것이다!
- Input sequence에 따라 low dimensional subspace가 constant한가?
- 만약 그렇다면, 이러한 중복을 제거하여 더욱 효과적인 압축을 할 수 있지 않을까?
- 저자들은 overcomplete basis인 universal dictionary로 Lexico를 제안하며, 이를 통해 KV cache를 효과적으로 decompose& reconstruction 할 수 있도록 한다.
- 저자들은 key vector의 subset이 군집화됨을 확인하였으며 이러한 low dimensional structure을 활용하기 위하여 compressed sensing과 dictionary learning의 관점을 가져온다
- Lexico는 간단하게 학습되고, 쉽게 적용 가능하며 상수 메모리 사용량 만을 추가하는 장점을 가진다.
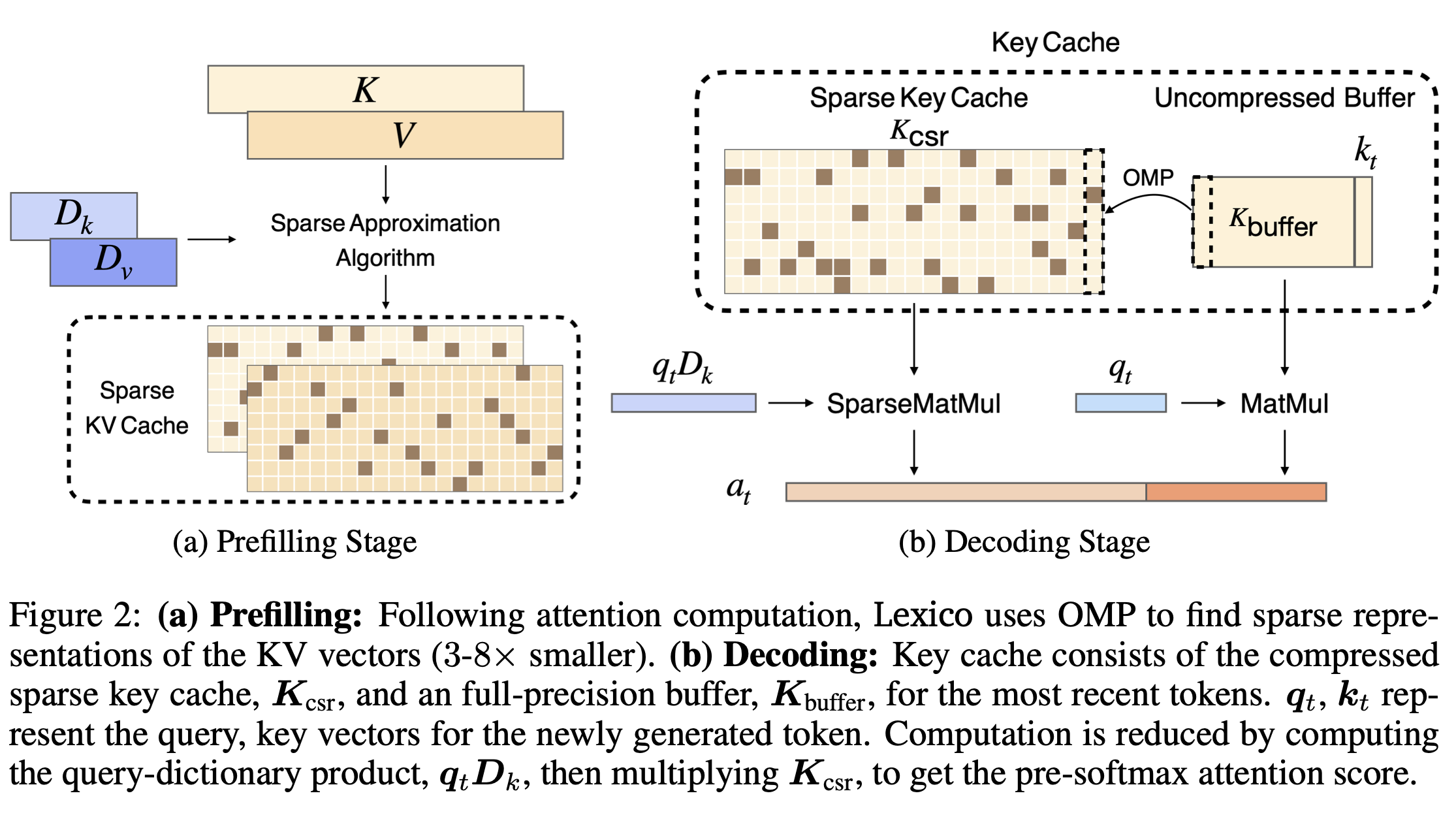
- Lexico는 아래와 같은 3단계로 학습을 진행한다
- Dictionary Pretraining: Wikitext103 데이터셋을 통해 사전에 universal하게 사용되는 dictionary를 만들어둠
- Sparse Decomposition: prefilling 과 decoding 시 KV pair를 sparse linear combination으로 만듦 (reconstruction coefficients와 dictionary indices로 구성)
- Lightweight sparse coefficient: sparse coefficients를 FP8로 만들어서 더욱 compression 심화 (2-bit)이하의 quantization을 달성하는 것
KV cache compression with dictionaries
-
Background and Notation
- KV cache output computation
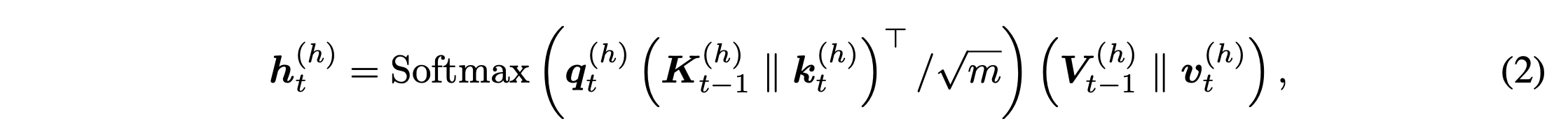
- KV cache output computation
-
Sparse Approximation
-
목표 : 가 되도록 D를 찾자
-
이 때 y는 에 proportional하다.
-
가정 : inherent redundancy exists
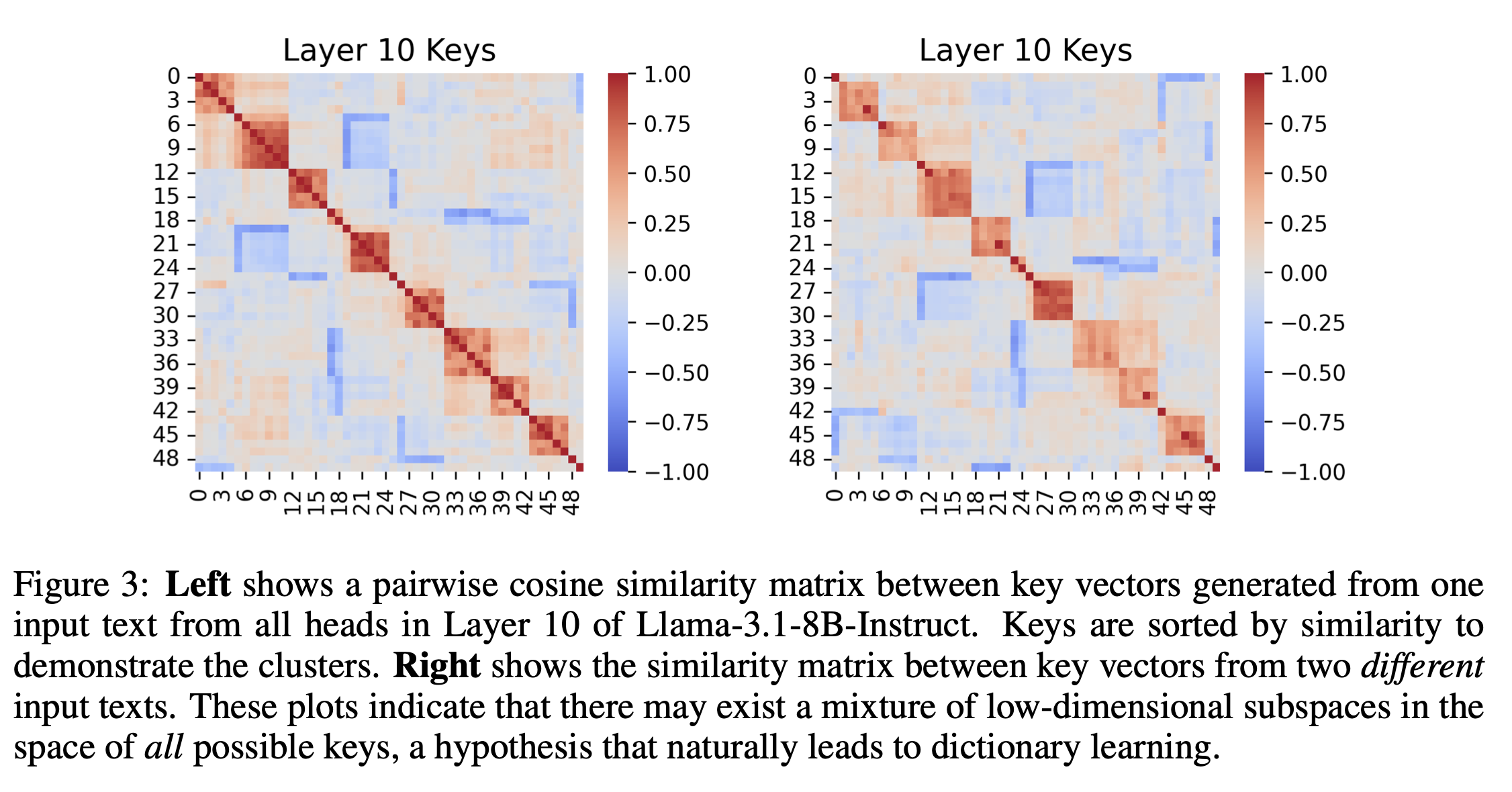
- key, value vector들이 different subspaces에서 compact set of atoms로 표현이 가능함을 보여준다
-
최적화 문제로 설명 가능
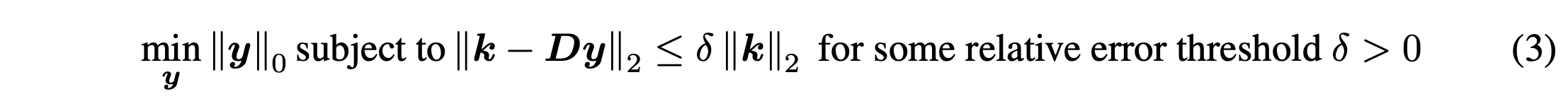
- 저자들은 해당 문제를 OMP를 통해 풀고자 함
- OMP : L2 reconstruction error를 최소화 하는 dictionary atom들을 선택 + selected sparsity에 도달하도록
- Cholexsky inverse based OMP 사용 + 배치 최적화

- 저자들은 해당 문제를 OMP를 통해 풀고자 함
-
-
Learning Layer specific dictionary
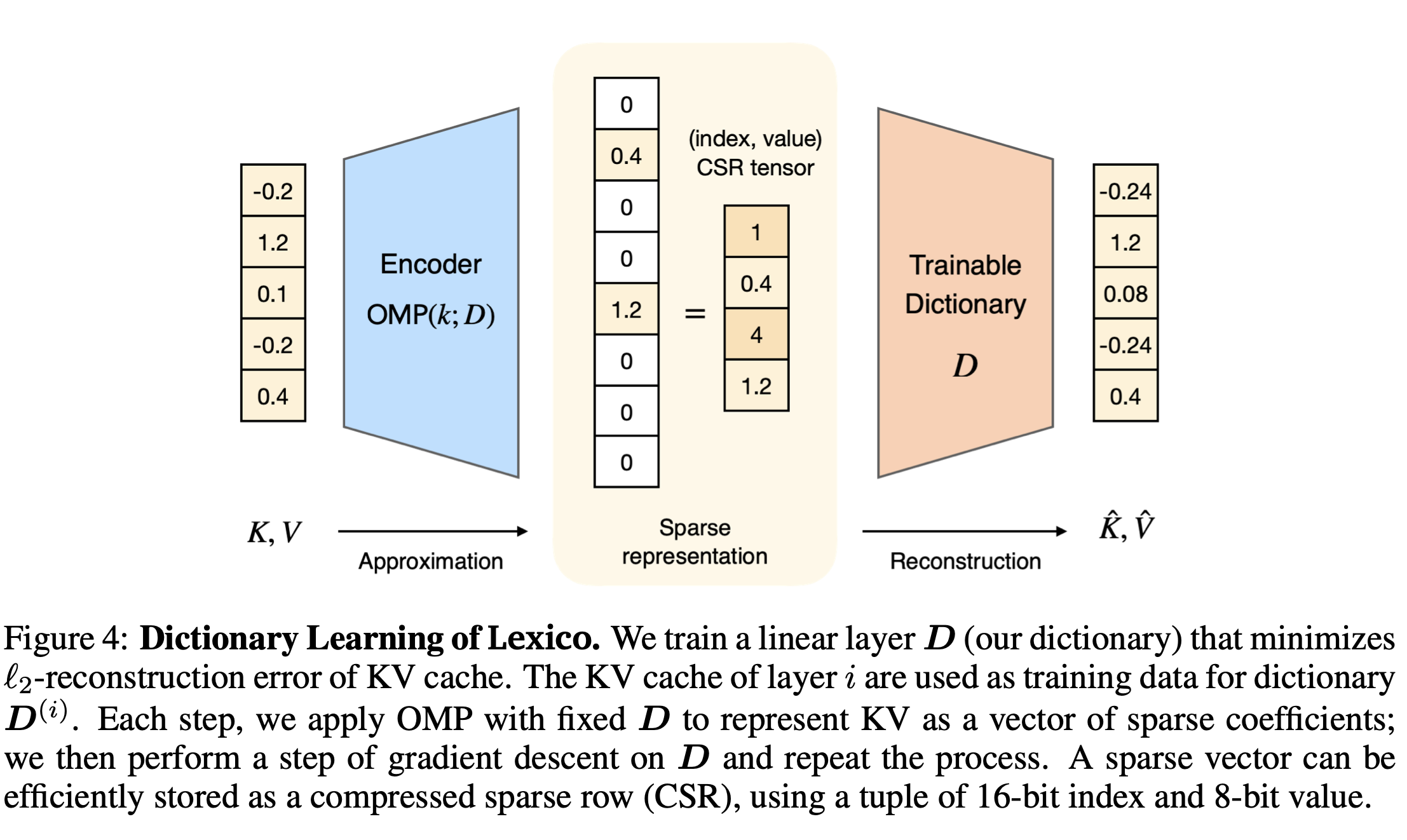
- 레이어마다/key, value 마다 다른 dictionary를 학습함
- Fixed size dictionary : , 7B /8B 모델에서 16.8M 정도의 사이즈만 차지함
- Gradient based optimization으로 KV dictionary를 학습함
- OMP algorithm으로 sparse representation y 추정 (multiple dictionary에 병렬 학습)
- Training Objective : , unit norm constraint
- Training : WikiText-103에서 KV 생성해서 사용
- 2시간 정도 걸림

- 이렇게 학습한 Dictionary가 Sparse Autoencoder보다 좋은 성능을 보임
- Universality 를 보임 : Out of domain dataset에 대해서도 더 좋은 reconstruction error 성능을 보임
- 2시간 정도 걸림
-
Prefilling and Decoding with Lexico

-
Prefill
- KV vector 생성 (full precision)
- OMP 로 Dictionary에서 최적의 sparse representation 생성
- Compressed key, value 복원하여 attention 계산에 사용
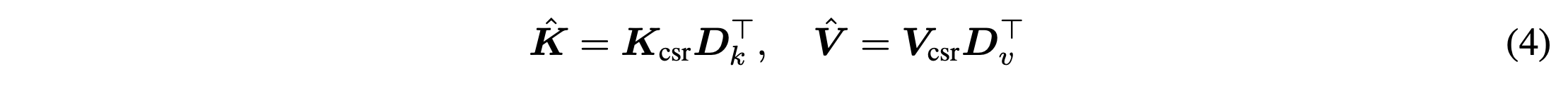
-
Decoding
- buffer를 사용하여 최근 n개의 토큰을 원래 사이즈로 유지
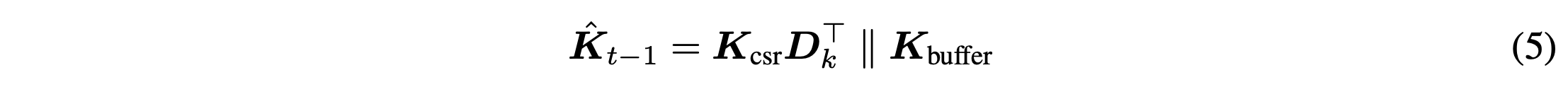
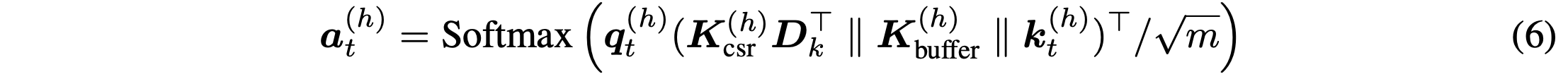
- Attention 계산은 전체 연결을 통해서 진행. 이 때 압축된 캐시와 full cache는 각각 연산 진행
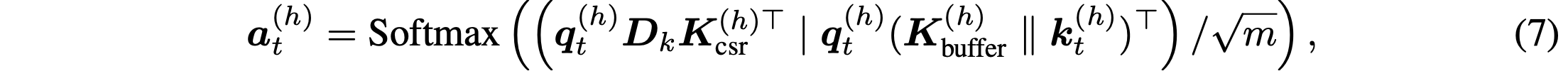
- 압축된 캐시 대상으로 pre-softmax 연산
- buffer가 가득 차면 가장 오래된 KV vector들을 OMP를 통해 압축 (Attention 연산과 병렬로 진행 가능)
- buffer를 사용하여 최근 n개의 토큰을 원래 사이즈로 유지
-
Time/Space Complexity
- Sparse representation은 CSR format (FP8)로 저장, indices는 INT16으로 저장, 각 행이 하나의 key나 value vector에 해당함
- memory usage : s + 2s + 2 (non-zero + dictionary indices + offset)
- head dim 128 → 256bytes needed for uncompressed vector → (3s+2) / 256 만큼 사용
- Time complexity :
- original : →
- CSR : →
- long context일 때 더욱 효과적임. short일 때는 약간의 overhead 발생Experiments
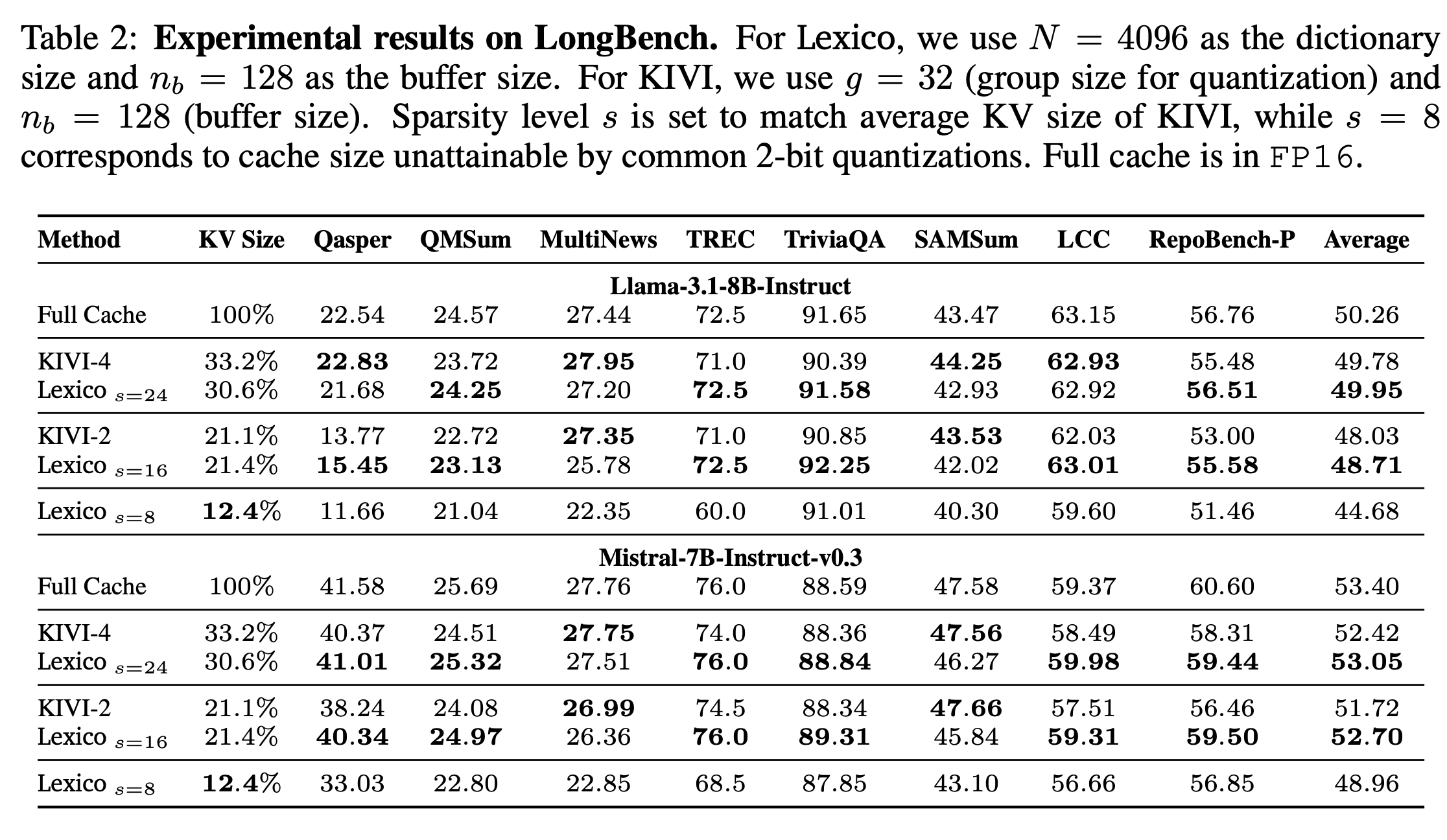
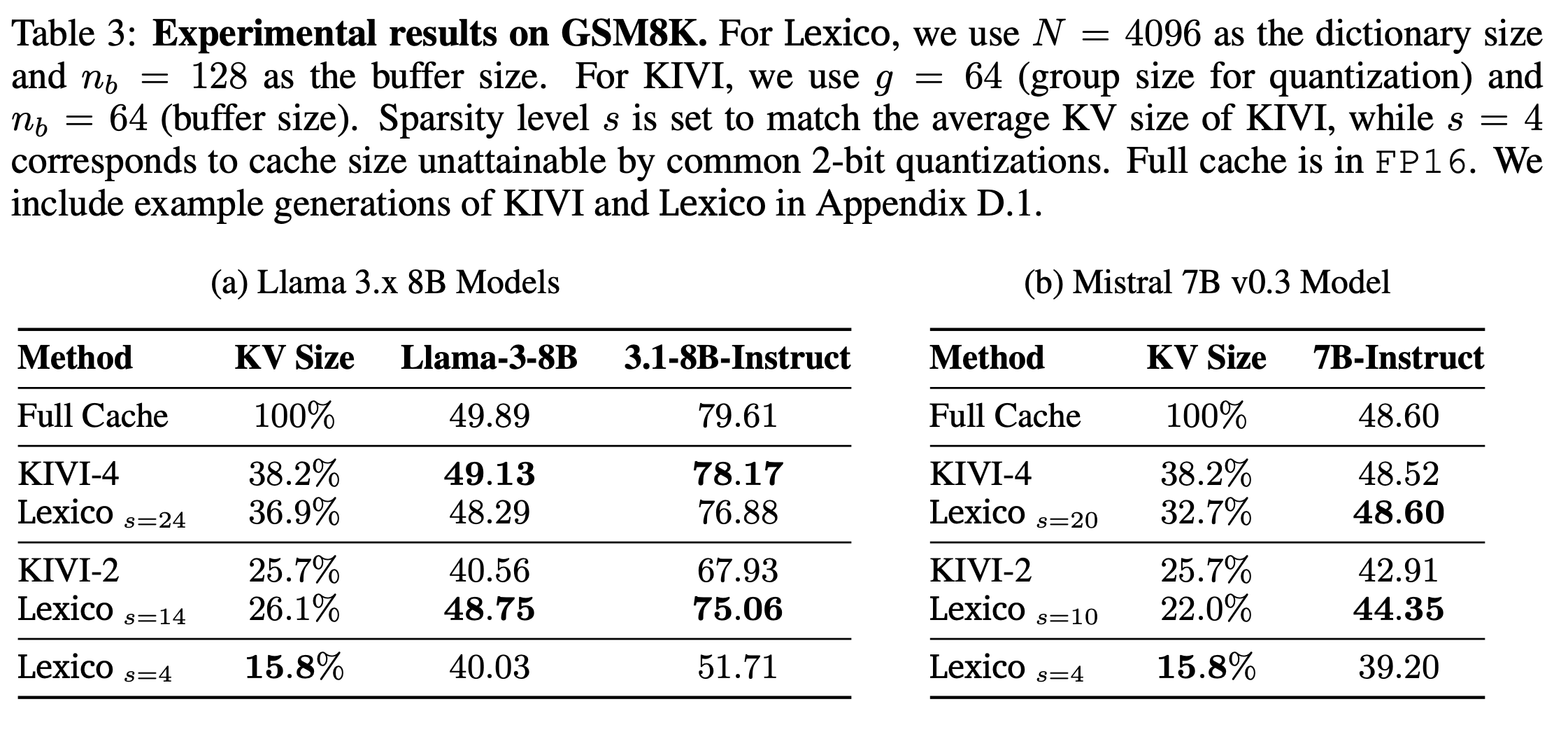
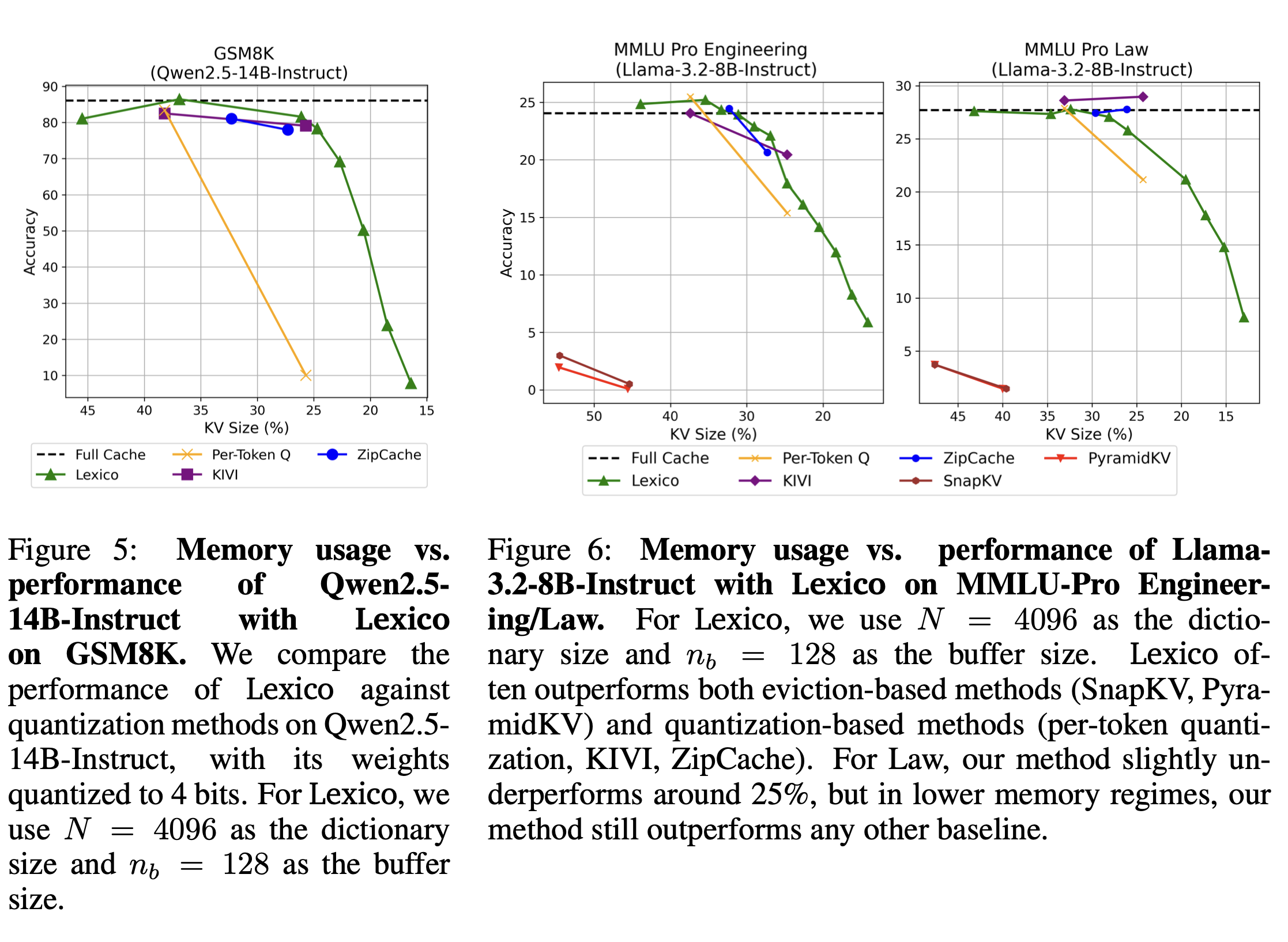
-
-
Error Thresholding in sparse approximation
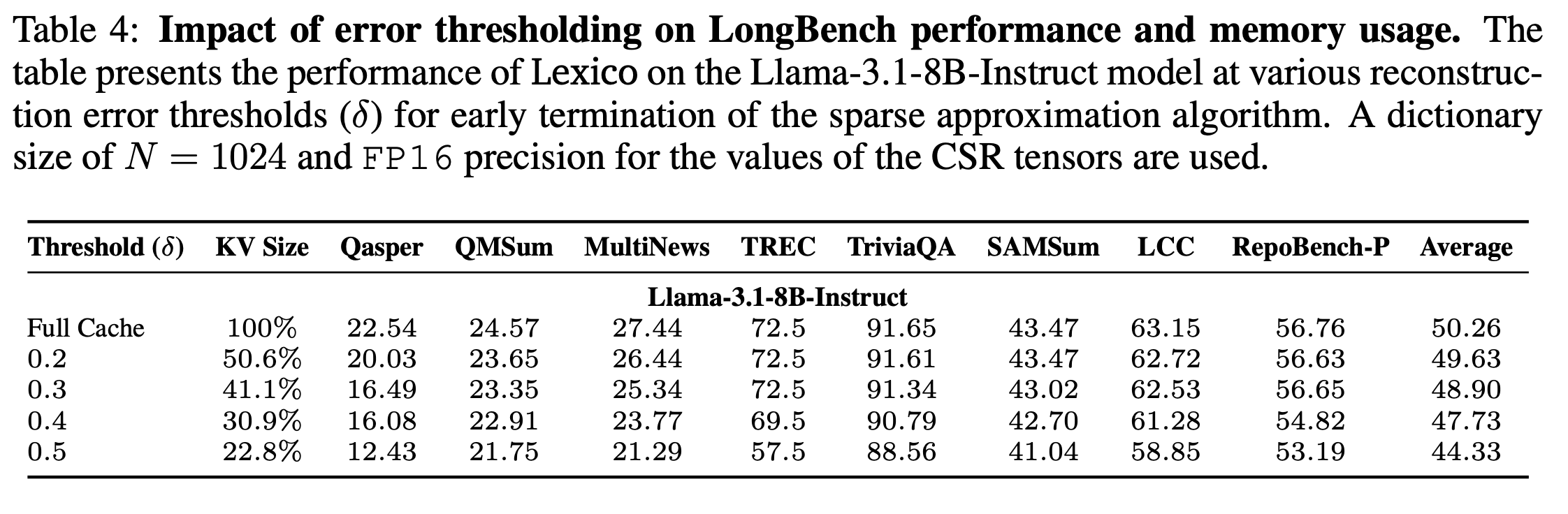
- OMP 가 error threshold 이하로 떨어질 경우 search 종료하도록 설계함.- 같은 sparsity 값을 설정해도 더 sparse한 결과를 얻을 수도 있음
-
Balancing memory between buffer and sparse representation
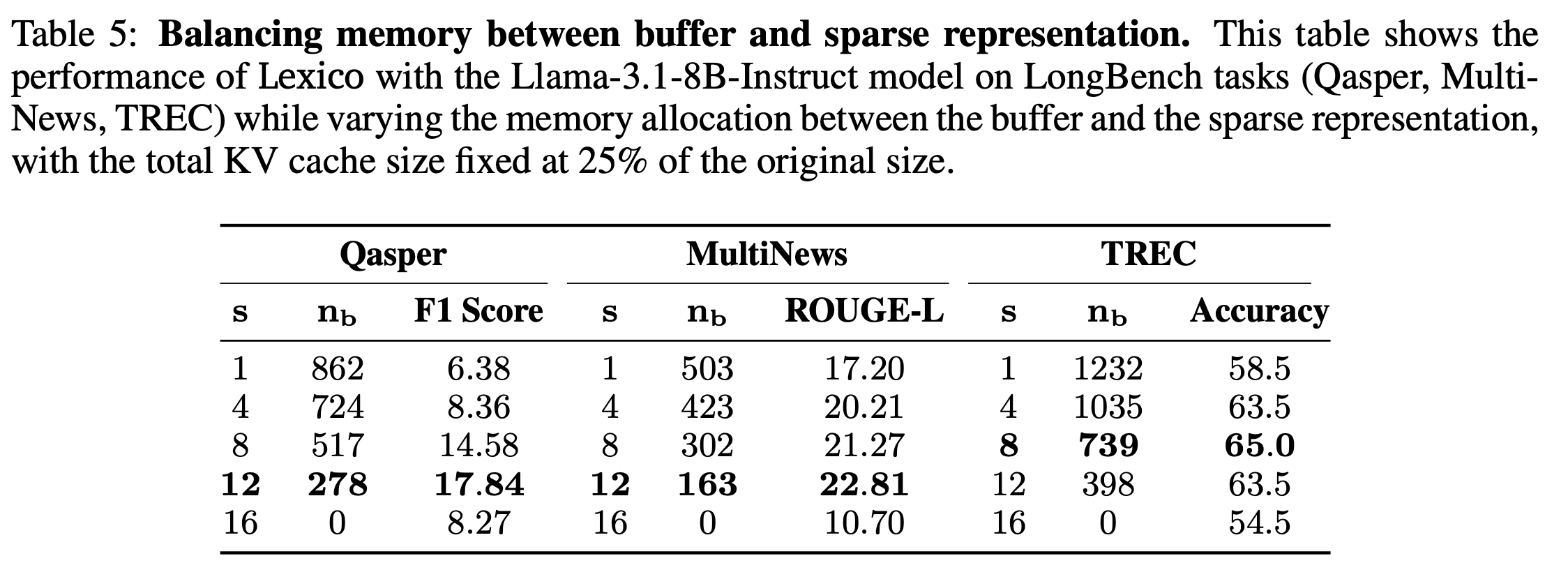
-
Adaptive Dictionary Learning
- Adaptive하게 dictionary를 decoding 시에 바꿀 수 있도록 학습 진행함
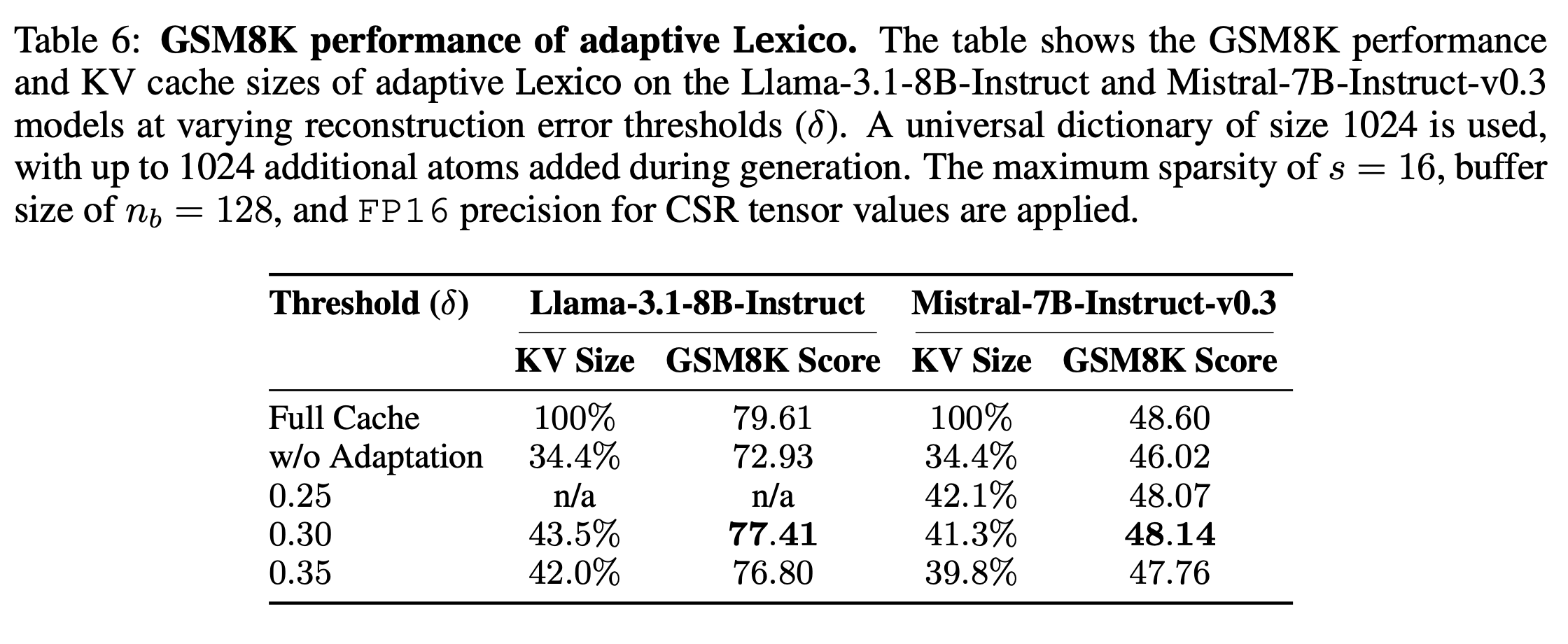
- Adaptive하게 dictionary를 decoding 시에 바꿀 수 있도록 학습 진행함
-
Latency Analysis

- 기존보다 latency overhead는 꽤 있는 편임
- 그래도 거의 12%까지 압축이 된다는데에 의의가 있을듯
