Introduction
- google에서 나온 새로운 메모리 기반 모델
- MAC, MAG, MAL, LMM 이렇게 네가지 모델로 나뉘어있음
- 현재까지의 모델들은 메모리 관점에서 vector-valued or matrix valued memory에 적절히 정보를 압축해서 흘리는 과정을 통해 완성되는데, 이를 좀 더 메모리 관점에서 접근할 필요가 있다.
- 메모리 관점에서 학습은 세가지 요소를 필요로 한다. 우리가 잘 만들어야 할 부분은 어떻게 이 요소들을 연결하고, abstraction을 만들어서 learning process를 완성하리이다.
- short term memory: 실제 학습을 하는 과정
- long term memory
- meta memory
- 메모리 학습은 1) 메모리 업데이트 2) 해당하는 메모리 정보 retrieve 이렇게 두가지 단계로 일어난다고 생각할 수 있다.
- 따라서, 모델이 좋은 메모리 학습을 하게 하기 위해서는
- 좋은 메모리 구조
- 적절한 업데이트 방법
- 적절한 메모리 retrieval 방법
- 효율적인 구조 간 연결
- 장기 기억을 위한 deep memory 설계
- 이렇게 여러가지 요소들을 고려할 필요가 있을 것이다.
- Titan에서는 이러한 요소들을 고려하며 차례차례 모델 설계를 진행한다. 결과적으로 메모리 학습을 ‘test time’ 에서 진행할 수 있도록 한다는 큰 장점을 가지게 된다. 이를 병렬화하여 학습할 수 있게 하여 효율적 메모리학습을 구현하고자 하였다.
- Titan의 구조는 3개로 크게 나눌 수 있다. 아래 구조들을 3가지 방식으로 조합하여 효율성을 파악한다. (context, gate, layer)
- Core: short-term memory, main flow of processing the data - attention with limited window로 구현
- Long-term memory: store and remember long past
- Persistent memory: learnable but data-independent parameters that encodes knowledge about a task
- Linear model as memory
- 위와 같이 어떠한 모델을 메모리 관점에서는 write operation(1) 과 read operation (2)로 나누어 파악할 수 있으며, 각각 메모리를 업데이트하는 과정과 업데이트된 메모리에서 필요한 정보를 읽어오는 과정이라 생각할 수 있다.
Learning to memorize at test time
- 이제 본격적으로 Titan의 구성에 대해 알아보자.
Long term memory
- 즉각적으로 들어오는 Input에 대한 정보만 파악하게 된다면, 장기적인 문맥을 파악하기 어렵게 되므로 보다 나은 일반화를 위해서는 장기 메모리의 정보를 잘 모델링하는 것이 중요하다. 이를 위해 titans에서는 surprise metric이라는 것을 도입하여 사용한다.
- 인간은 얼마나 어떠한 경험에 영향을 받았는지에 따라 그 기억이 장기기억으로 전환되는지 여부가 결정된다. 이를 모델에도 동일하게 적용하여, 모델이 얼마나 ‘놀랐는지’ 에 따라 이를 장기기억에 반영하도록 하는 것이다. 여기에서는 gradient를 이용하여 이를 measure한다.
- 그러나 이러한 surprise metric은 큰 surprise가 반복된다면 그 다음에 오는 정보들을 무시하게 될 가능성이 있다. 즉, Local minima에 빠지게 되는 것이다. 따라서 이를 반영하여 모델링하고자, past surprise와 momentary surprise로 나누어 모델링을 진행한다.
-
여기서의 parameter은 data dependent한 decay로서 과거 정보를 얼마나 반영할지를 결정할 수 있게 된다.
-
surprise metric의 objective는 loss function으로 정의된다. 결국 우리의 모델은 meta learning으로 objective를 배우게 되는 것이다.
-
Associative memory 관점에서 우리는 key, query, value 개념으로 메모리 구조를 파악할 수 있을 것이며 이를 이용하여 loss를 정의할 수 있다.
-
이 Loss function은 inner loop의 memory에 대한 것이므로, key, value의 weight update에는 관여하지 않는다. 즉, hyperparameter로 기능하게 된다. 따라서 inner loop에서는 memory의 weight를, outer loop 에서는 다른 파라미터들을 업데이트하며 학습하게 된다.
-
Forgetting mechanism은 장기 기억에 있어서 얼마나 ‘잊을지’를 결정하는 방법이다. alpha를 이용하여, 한정된 공간에 최대한 효율적으로 메모리를 저장하고자 얼마나 기억하고 잊을지를 조절한다.
- Memory 구조 관점에서 생각할 때 MLP를 사용한다. 기존 아키텍처들은 vector-valued or matrix valued hidden state를 사용했고, 이를 loss function 관점에서 해석하면 Linear regression objective로 표현되기에 linear dependency만을 가정하게 되었다. 이것을 MLP 로 변형하여, 보다 다양한 objective를 반영할 수 있도록 하는 것이다.
- Retrieval은 간단하게 forward pass로 수행한다. 메모리에서 업데이트 없이 forward pass를 수행해 query에 해당하는 memory 값을 가져온다.
How to parallelize
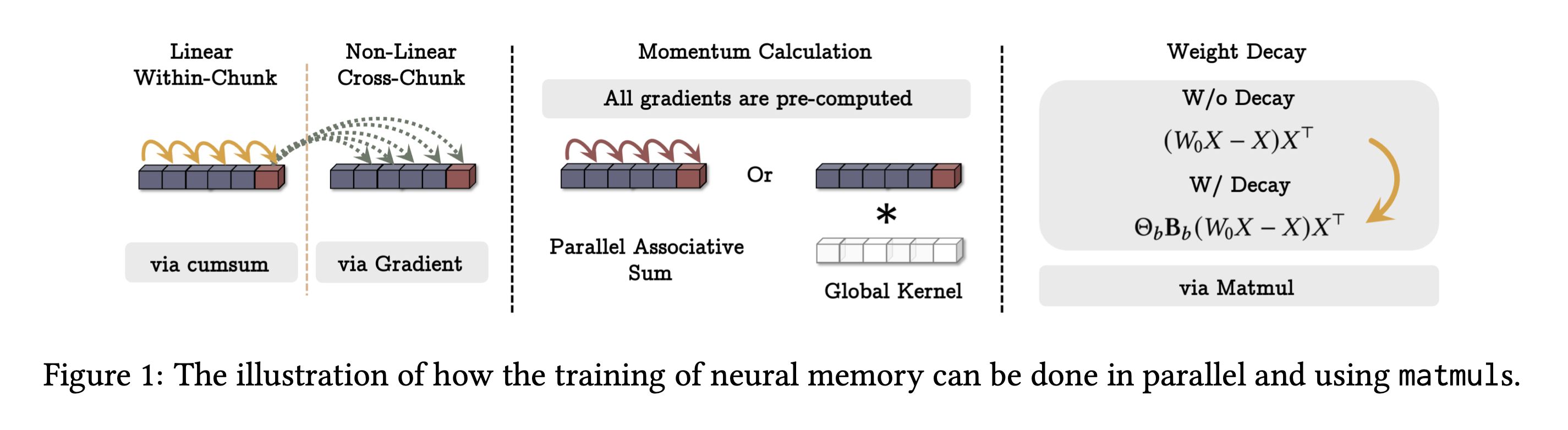
- O(N) 시간이 필요한 전체 과정을 병렬화하여 보다 효율적인 학습을 가능케하고자 한다.
- 이를 위해 mini batch gradient descent를 응용한다. 시퀀스를 청크단위로 나눈 뒤, 아래와 같은 방식으로 학습을 진행한다. 이는 gradient with momentum과 같은 형태이다!
- 파라미터도 청크에 대한 것으로 보았을 때 불변이므로 LTI로 모델링이 가능해진다.
Persistent memory
- Persistent memory는 contextual memory로, learnable but data independent parameter 들로 구성된다. 쉽게 생각하면 모델에게 어떤 task를 주입하고 있는지를 알려주는 것이라고 보면 된다. input 앞에 붙여서 사용하는 형태라고 생각하면 된다. 이를 덧붙임으로서 기술적으로는 attention의 implicit bias로 Initial token에 집중하게 되는 현상ㅇ을 이용할 . 수있게 되며, softmax와도 같은 방향으로 이해할 수 있다.
How to incorporate memory
- 메모리를 주입하는 방법은 여러가지가 있을 것이다. Titan은 세가지 컴포넌트로 구성되는데, Core, Contextual memory, Persistent memory가 바로 그것이다. 각 방법은 여기서 어떻게 persistent memory와 contextual memory가 core와 결합되는지를 중점적으로 설명하고 있다.
Memory as context
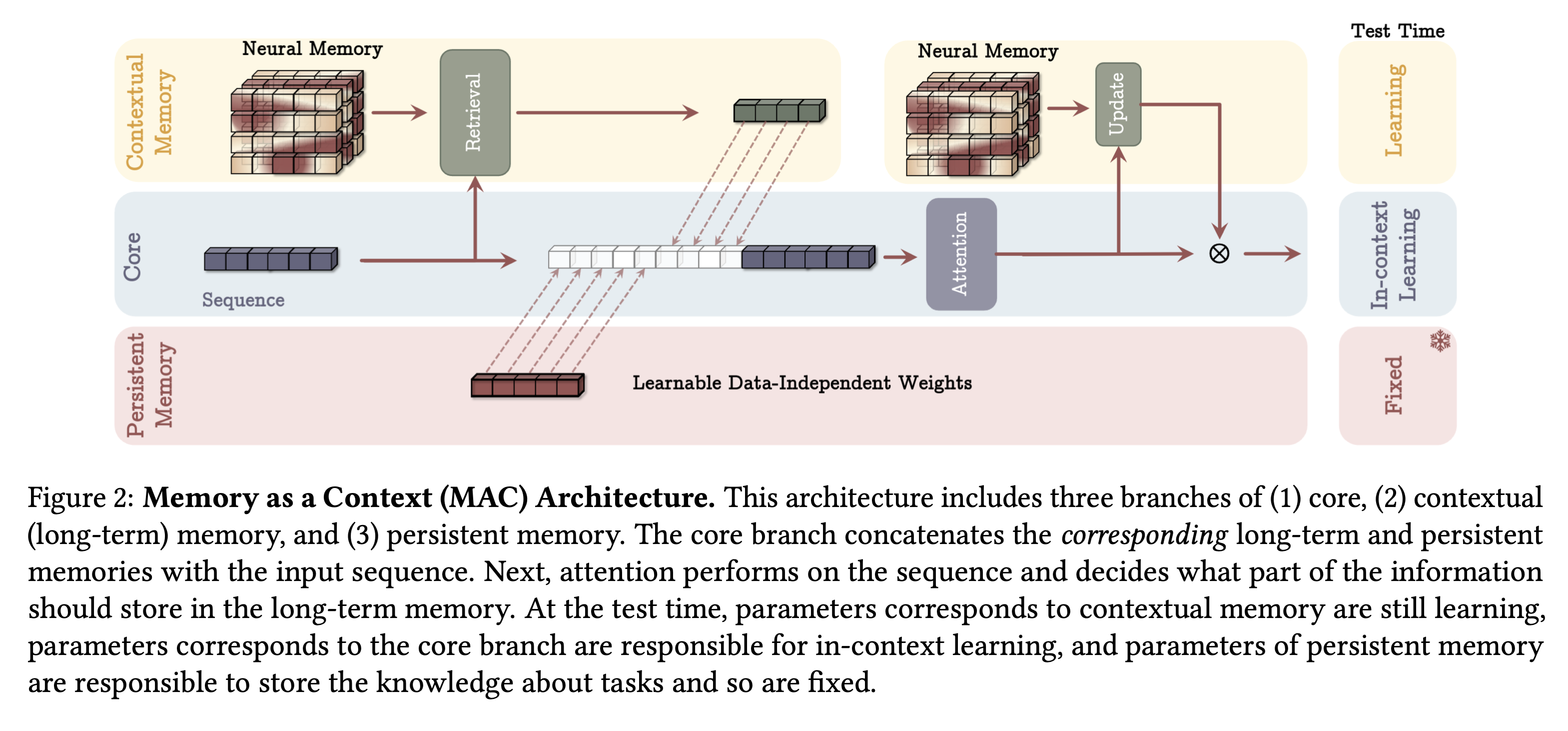
- sequence를 chunking하여 미리 memory 정보를 가져온 다음, 이를 context로 함께 주입하여 attention을 진행하는 방법이다. 이를 통해 memory update에 query의 과거 정보가 주입되고, 다시한번 이를 통해 업데이트한 메모리로 최종 게이팅을 진행한다.
- 이를 통해 과거 정보와 현재 정보를 동시에 활용하여 장기기억이 필요한지를 결정할 수 있으며 attention으로 과거 정보 중에서도 중요한 정보만 기억하도록 할 수있다. test time에서는 persistent memory는 고정, attention은 in-context learning 으로 학습, long 은 memorize 과정을 통해 update하며 test-time learning을 가능케한다.
Memory as gate
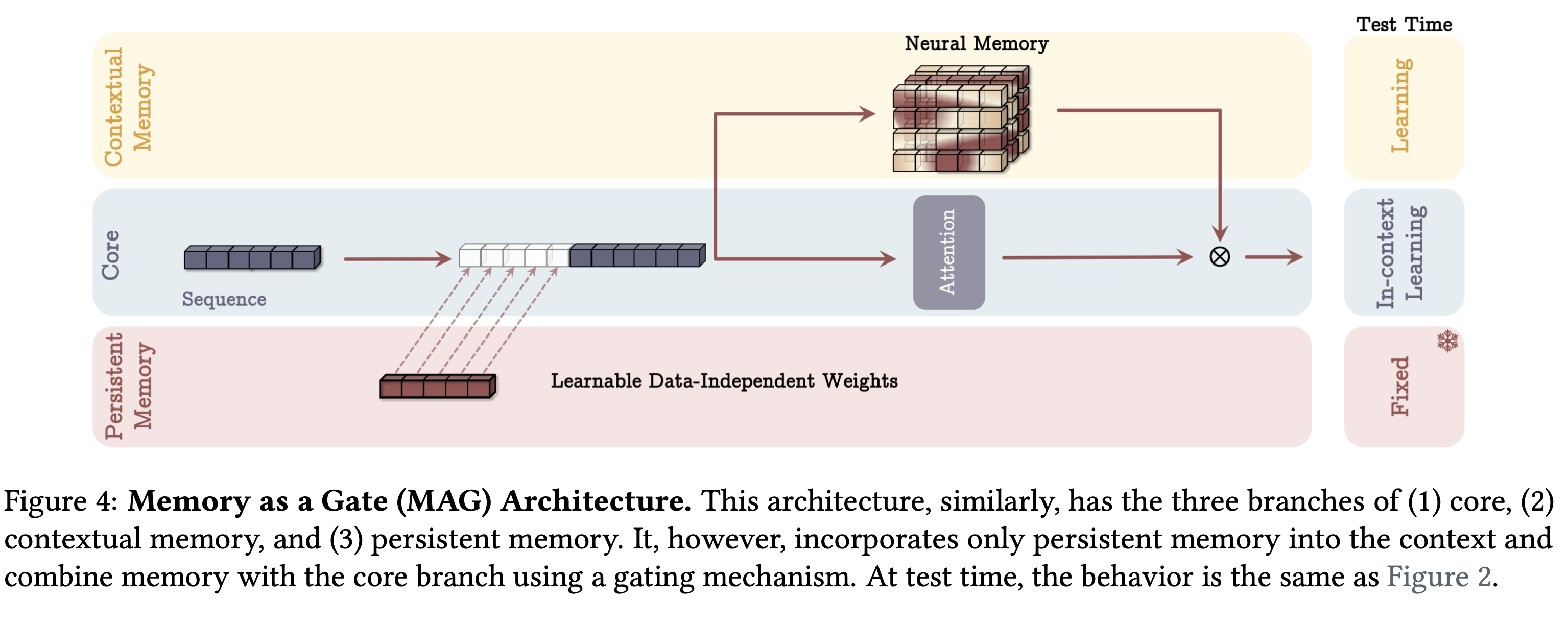
- input를 sequence 단위로 나누는 대신에 하나로 사용하며 전체에 대해서 sliding window attention으로 attention update를 수행한다. 마지막으로, 이렇게 업데이트 된 메모리를 게이트처럼 이용하여 최종 output을 결정한다. SWA를 short term memory 작동 방식으로 활용하며 long은 자연스럽게 fading하게 되고, multihead에도 적용 가능한 모델링 방식이다.
Memory as layer
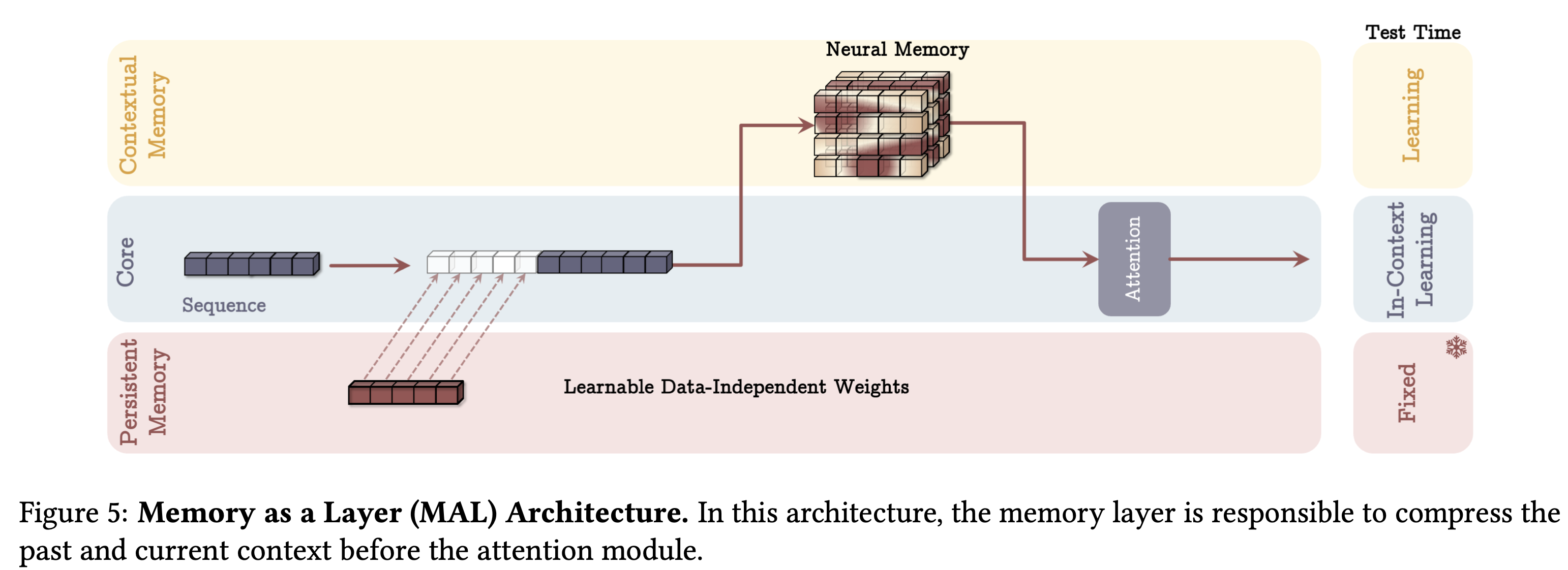
- 마지막 방법은 memory를 Layer로 사용하는 방식이다. 즉, input을 memory에 통과시키고, 이를 attention을 적용하는 방식으로 다양한 hybrid 모델에서 사용되는 형태이다. 메모리 모델링 방식의 장점을 활용하는 것은 어렵지만, 이를 통해 간편하게 implement가 가능하다.
- 아예 아무런 방식도 사용하지 않고, memory module만 사용한 것은 LMM 혹은 Titan 이라고 부른다.
- 다양한 모델링 방식을 확인하고자 H3를 base architecture로 하여 sequence modeling module만 LMM으로 교체하여 실험을 진행한다.
Experiment
- 실험을 통해 전체 퍼포먼스, context length generalization, scaling, memory depth, component efficacy를 확인한다. 아래 표를 통해 결과를 보인다.
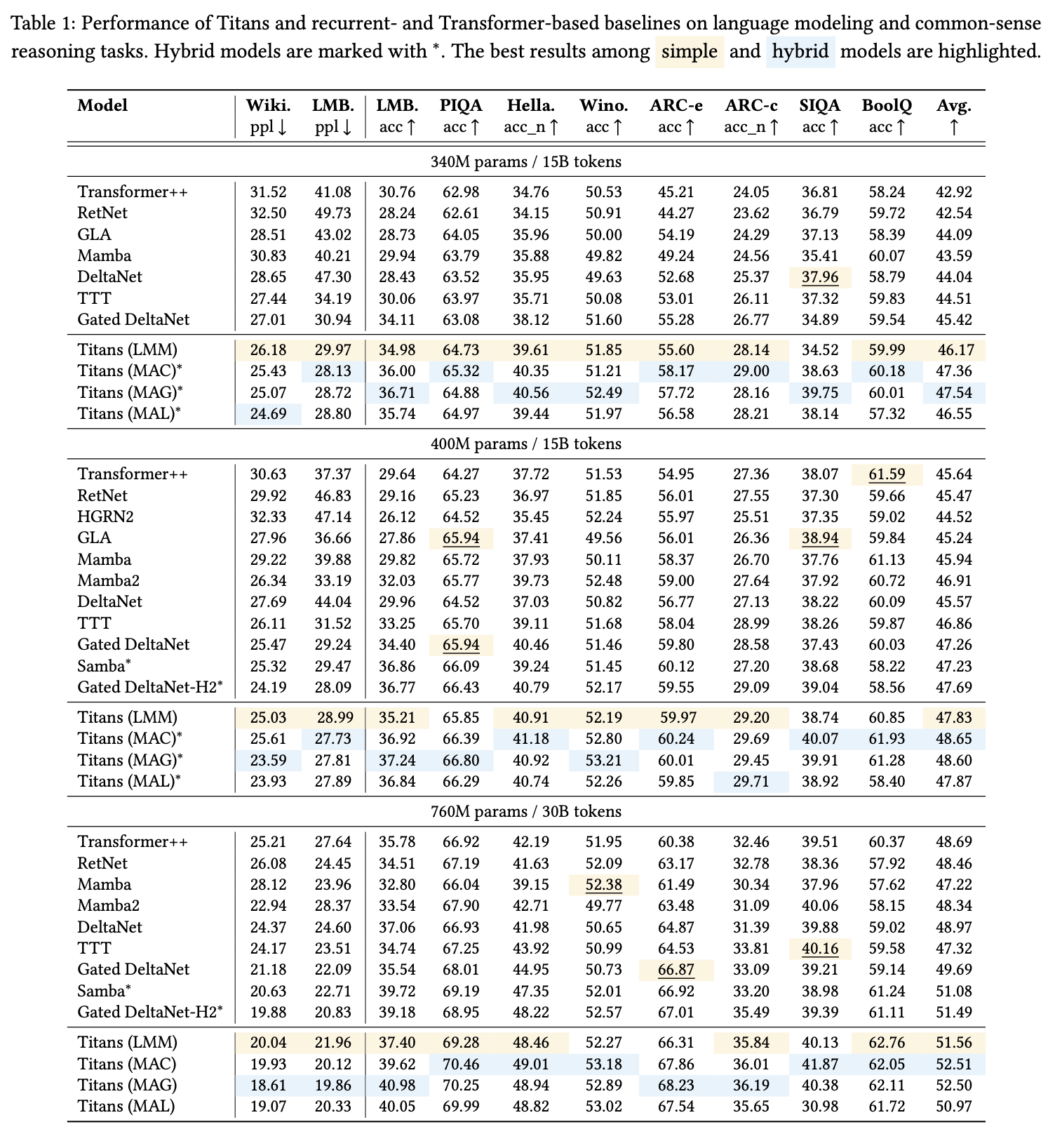
- 전체적으로 좋은 성능을 보이는 것을 확인할 수 있었으며 length 가 16K 까지 늘어나는데도 꽤 좋은 성능을 보였다
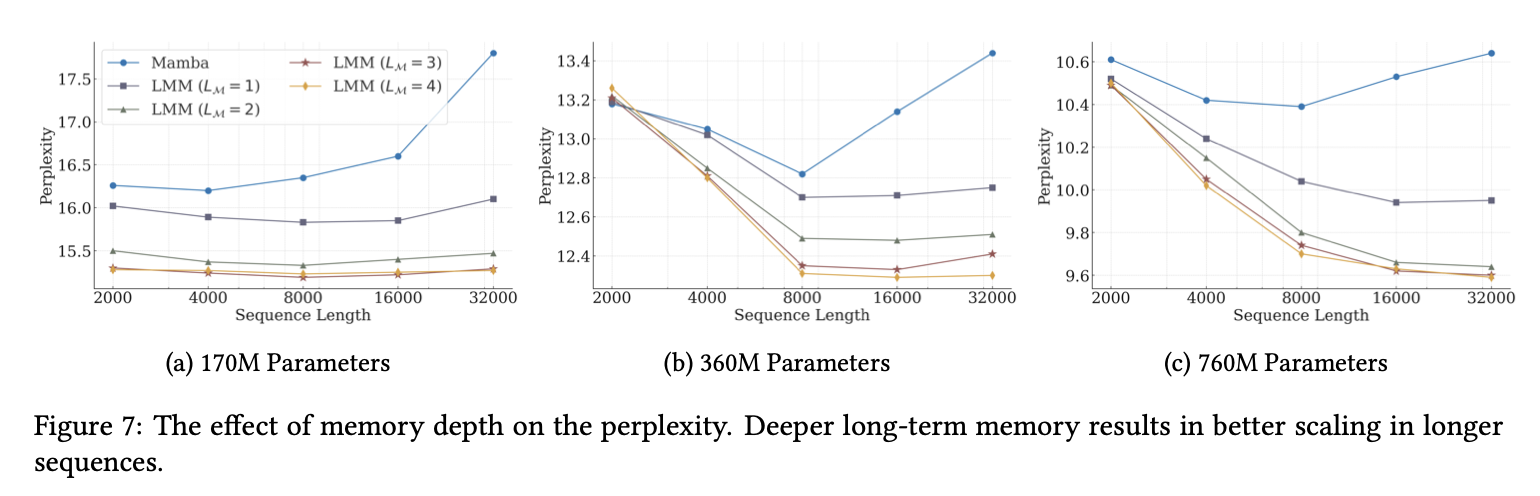
- 또한 메모리에 대한 영향력을 확인했을 때, memory가 깊어질수록 더좋은 perplexity를 가지는 것을 볼 수 있었다. 다만, 이는 training 속도 저하를 야기하므로 이에 대한 balancing이 중요해 보인다.
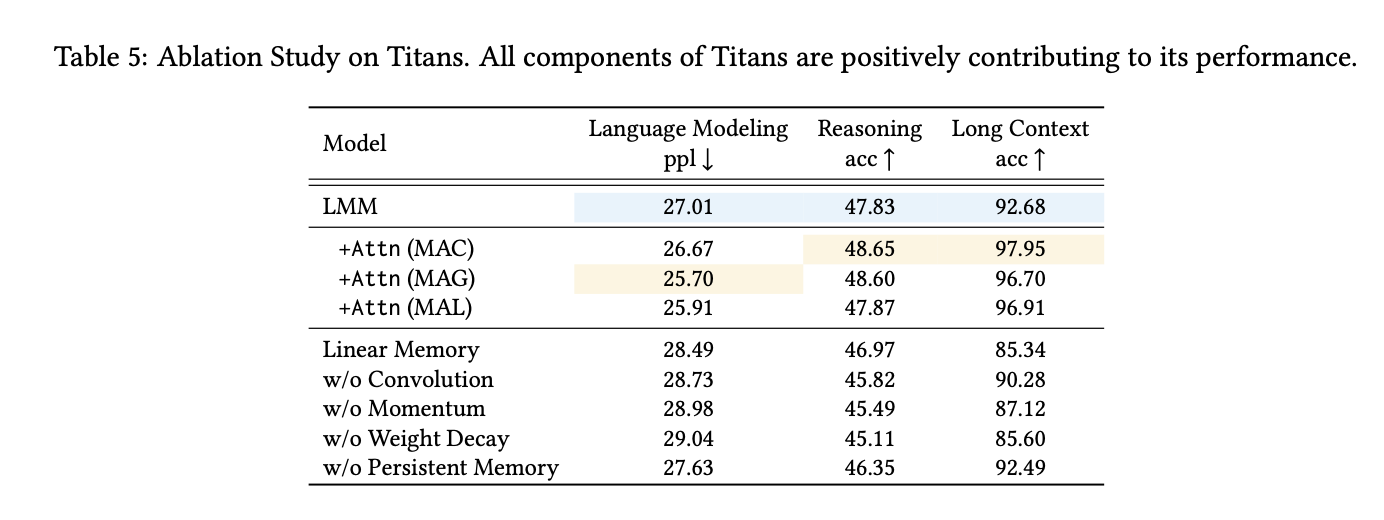
- 마지막으로 ablation을 통해 각 component의 효용성을 보여주며 논문은 마무리된다.
- subquadratic nature에서 다양한 아키텍처들이 등장하고 있는데 메모리 관점의 접근은 신선하다고 느껴졌고 좀 더 탐구해볼만한 주제라고 느껴졌다.

M.S Student @ KAIST GSAI