기존 Autoregressive language model paradigm에서 벗어나서 Diffusion model을 기반으로 한 large langauge model이 등장했다. 확률분포로서 language model을 바라보게 되는데, model distribution을 optimize해서 원래 분포를 찾아가는 과정이라고 볼 수 있다.
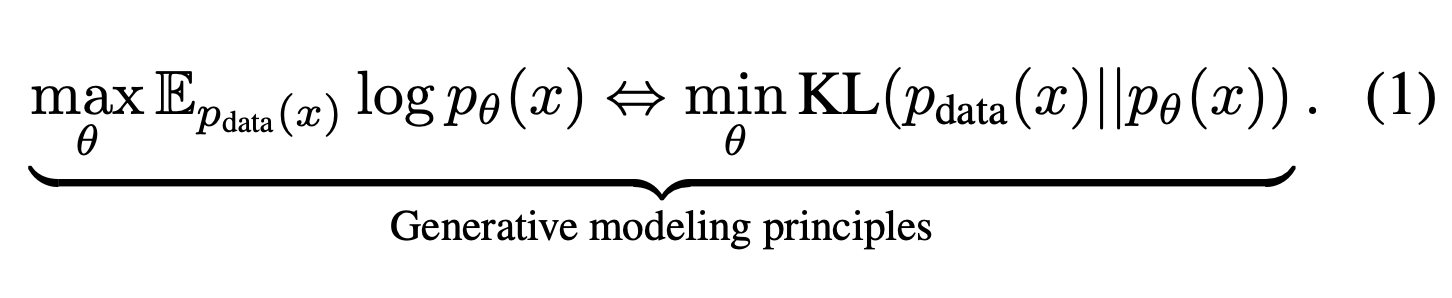
Autoregressive model (ARM)은 next token prediction으로 model distribution을 추정해가는 방식이다.
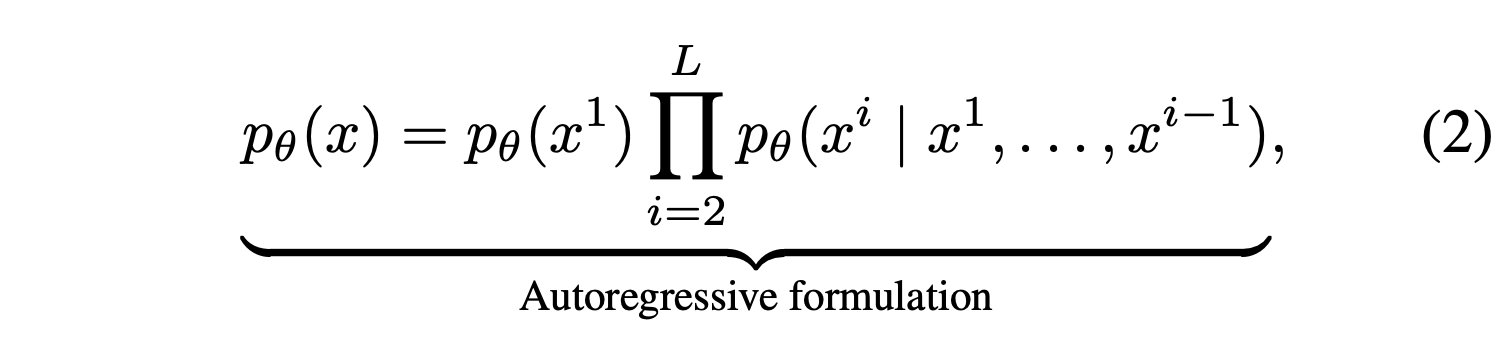
그러나, ARM이 유일한 modeling 방식이냐고 묻는다면, 그렇지 않다. ARM이 큰 모델을 만들 수 있음은 Transformer model, data size, FIsher consistency 덕분에 가능한 것이다. 또한 Instruction following과 in context learning ability는 conditional generative model의 intrinsic property라고 볼 수 있다. ARM은 lossless data compressor, 즉 데이터 손실 없이 압축하는 모델이라고 이해하는 것인데 이는 다른 모델에서도 성립하는 성질이다.
ARM의 단점은 reversal reasoning, 즉 역으로 답을 찾아가는 과정을 잘 하지 못한다는 점이 있다. 저자들은 이 논문에서 Masked diffusion model을 통해 앞선 ARM의 특성을 가지면서도 reversal reasoning을 해결하는 모델인 LLaDA (large language diffusion with masking)을 제안한다. 핵심적으로는 discrete random masking process와 mask predictor를 어떻게 구현하는지를 살펴보아야 한다.
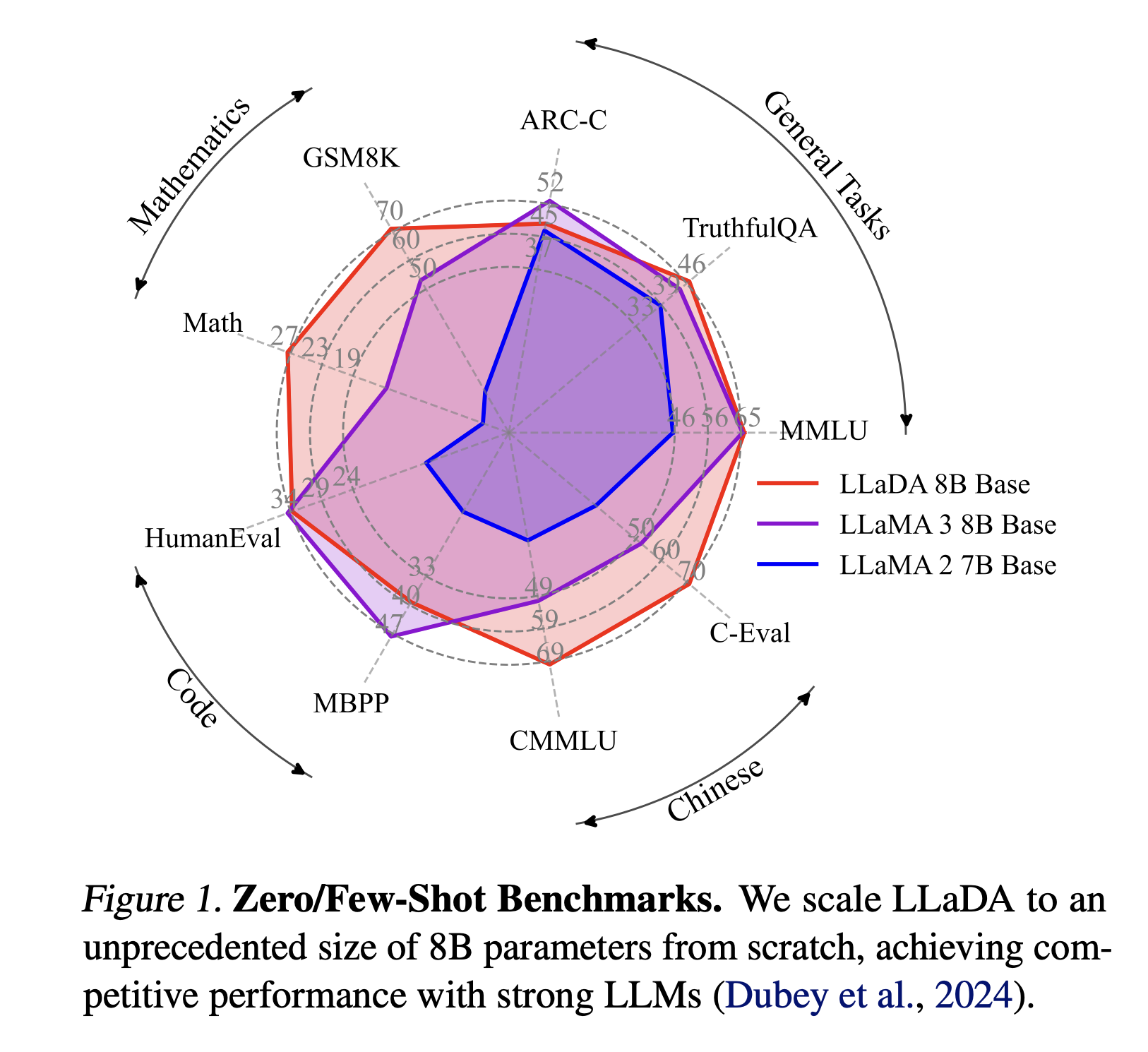
결과적으로는 LLaMA2 7B 보다 좋은 성능을 보이며, LLaMA3 8B와도 비교 가능한 성능을 보였다. 또한 코드, 수학, 중국어에서 기존 모델들보다 좋은 성능을 보이는 것을 확인할 수 있었다.
Approach
Probabilistic Formlation
이제 좀 더 자세히 LLaDA의 구조를 살펴보자. 기존 ARM과는 다르게, 모델 분포를 forward process 와 reverse process를 통해 정의한다. Forward process는 순차적으로 sequence를 0에서 1로 시간이 지나면서 마스킹을 하게 되고, reverse process는 이를 다시 복원하는 과정이다.
여기서 가장 중요한 것은 Mask predictor 로 마스킹된 토큰을 예측하는 예측기이다. t 시점의 input 를 받아서 전체 마스킹 토큰 M을 한번에 예측하는 것이다. Mask predictor의 학습은 마스킹된 토큰들에 대한 Cross entropy loss를 통해 이루어 진다.
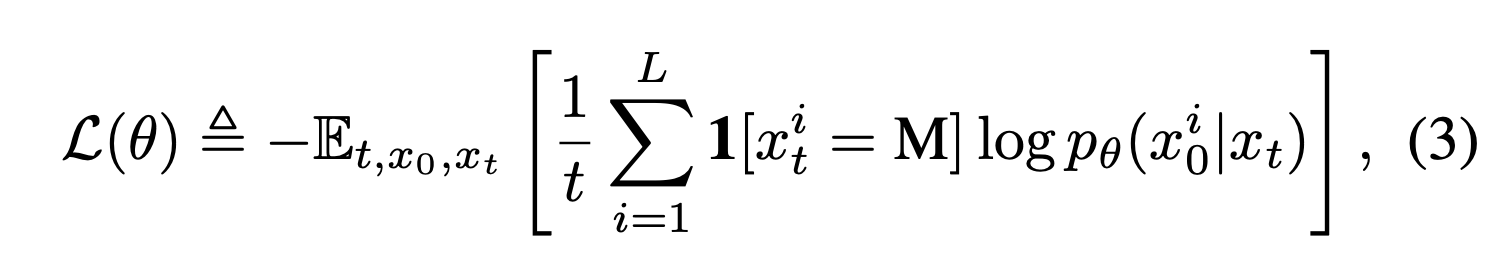
학습이 끝나면, 학습된 mask predictor로 파라미터화한 reverse process에 대해, 모델 분포 를 marginal distribution으로 하여 복원을 진행하게 된다. 특히 앞선 forward process에서의 loss function은 모델 분포의 upper bound가 되므로, 이를 learning objective로 삼을 수 있다.
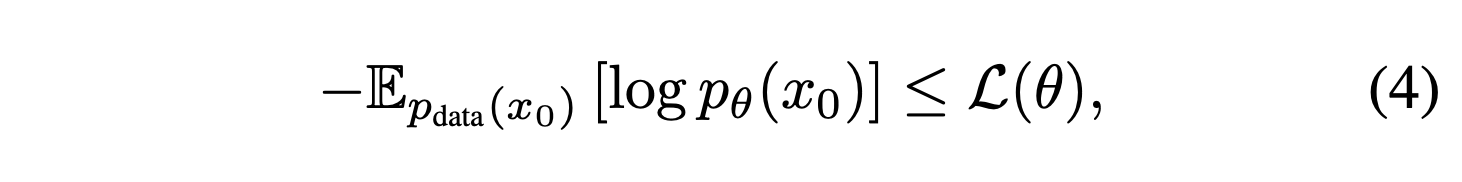
이 과정에서 masking ratio는 t로 시간에 따라 변화하게 된다. 이는 scale에서 큰 차이를 가져오게 되며 in context learning ability까지도 영향을 미친다. 자세한 reverse process algorithm은 아래와 같다.

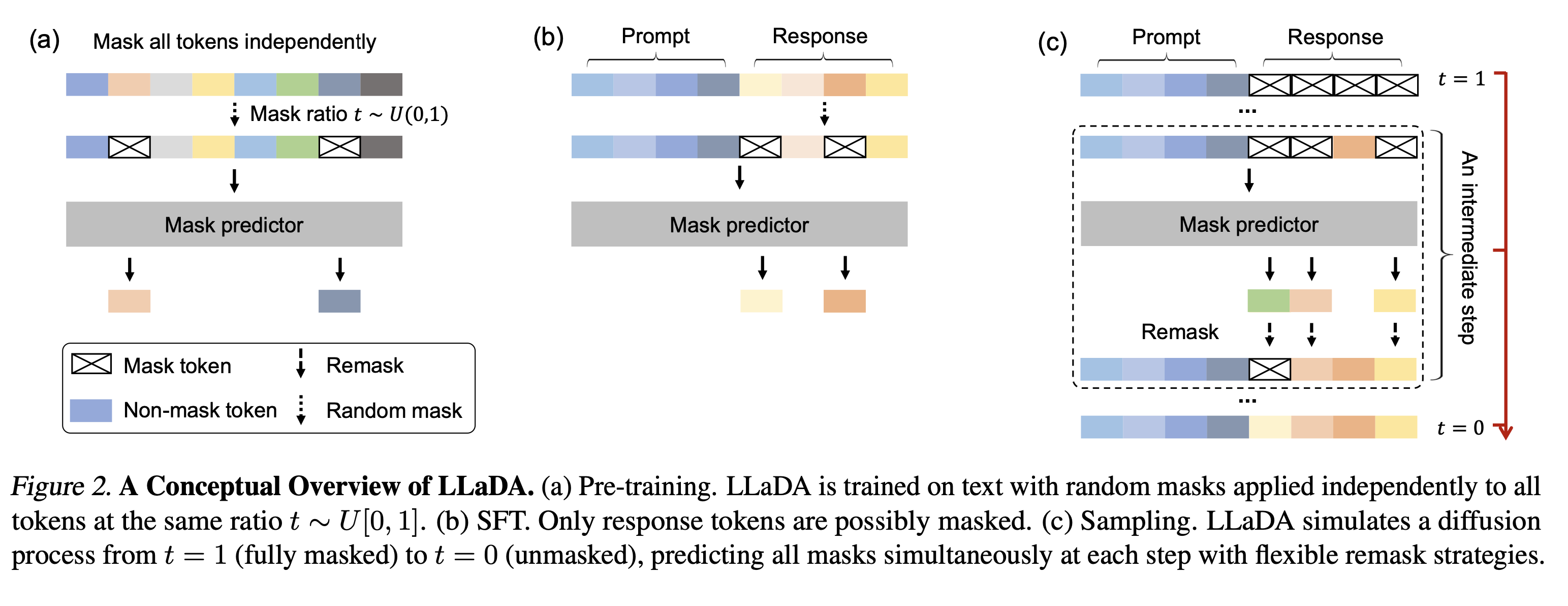
Pretraining

사전학습은 그림의 (a) 번처럼 이루어진다. maksing 된 토큰에서 unmasking하는 reverse process를 통해 학습이 이루어진다. 여기서 토큰 마스킹은 각 토큰에 대해 독립적으로 이루어 진다. LLaDA는 트랜스포머 구조를 mask predictor로 사용하며, causal mask를 사용하지 않는 bidirectional 구조이다. 논문에서는 1B, 8B 모델 두가지를 학습하였으며, 대부분의 하이퍼파라미터는 바꾸지 않고 학습을 진행하였다고 말한다. Grouped Query Attention은 Diffusion nature에 맞지 않으므로 일반 multi head attention을 사용하고, KV caching도 필요 없으므로 하지 않았다고 한다. 2.3T 데이터셋에 0.13M H800 GPU Hour 동안 학습을 했다고 한다. (진짜..길다…..) 학습 과정에서 training sequence에서 t는 sampling을 통해 얻었다고 한다.
Supervised Finetuning

SFT는 그림의 (b)를 살펴보면 된다. SFT를 위해서는 paired data 이 필요하다. 프롬프트와 응답 쌍으로 이루어진 데이터셋을 통해 conditional distribution 를 모델링하는 것이다. 이를 위해 프롬프트는 마스킹 하지 않고, 응답에 대하여 마스킹을 진행한다. 그리고, SFT를 위한 mask predictor를 학습시킨다. pre-training과 달라진 점은 단지 가 로 바뀐 점이다.
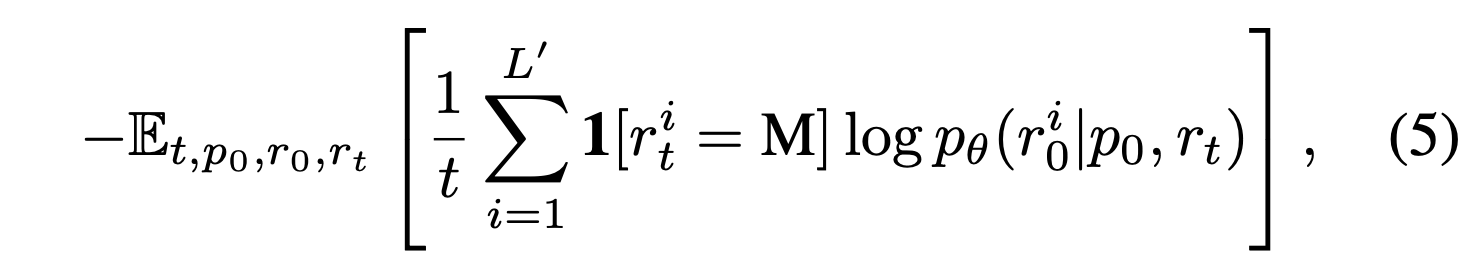
pretrianing 과정과 동일하게 다른 추가적인 최적화 테크닉은 사용하지 않았으며, 4.5M 데이터셋에 대해 학습을 진행했다고 한다. EOS 토큰으로 데이터 길이를 관리했으며 샘플링 시에는 이를 삭제하여 응답 길이를 자동으로 조절하도록 하였다고 한다.
Inference

이제 실제로 생성하는 과정이다. 그림에서는 (c)를 보면 된다. LLaDA도 생성모델로서 샘플링과 likelihood 계산을 모두 할 수 있다. 먼저 샘플링을 통해서 prompt 가 주어졌을 때, reverse process를 통해 전체가 마스킹된 시퀀스에서 출발하여, 복원을 통해 답변을 생성한다. 이 때 단계별로 마스크를 복원하는 과정에서 몇번의 스텝을 통해 복원할지는 하이퍼파라미터로 두었다. 이를 통해 효율성과 샘플링 품질 간의 trade-off를 조정하고자 하였다. timestep은 uniform하며 generation 길이도 하이퍼파라미터로 두어 처음에 fully masked sequence의 길이를 얼마로 할 것인지를 정해두었다고 한다. 앞선 학습 과정에서는 시퀀스 길이를 정해두지 않고 자동으로 조절되도록 하였기에, 생성 시에 길이를 마음대로 결정해도 이미 학습한 것이라 괜찮다.
좀 더 자세히 에서 로의 스텝을 생각해보자. 그러면 먼저 모델에 를 주입하고, mask predictor는 한번에 모든 마스킹된 토큰을 예측한다. 다음으로는 “remask”를 진행하게 되는데, 답변 를 얻게될 expectation에 따라 만큼을 다시 마스킹한다. 원칙적으로 이 remasking은 전부 랜덤으로 진행해야 한다. 그러나, LLM의 sampling 방식에 영감을 받아 저자들은 두가지 deterministic sampling strategy를 채택했다. 한 가지는 low-confidence remasking으로 가장 predicted confidence가 낮은 토큰을 remasking 대상으로 선정한다. 두번째로 SFT 이후에 LLaDA를 여러개의 시퀀스 블록으로 나눈 뒤, 각 블록에서 autoregressive 하게 remasking을 진행하는 autoregressive remasking을 할 수도 있다. 각 블록 내에서 우리는 reverse process를 적용해 샘플링을 할 수 있다.
추가적으로 likelihood evaluation을 위해서 우리는 모델의 upperbound 를 사용하게 된다. 이 upper bound와 같은 수식이지만 더작은 분산과 안정성을 가진 수식으로 아래 수식을 사용하게 된다.
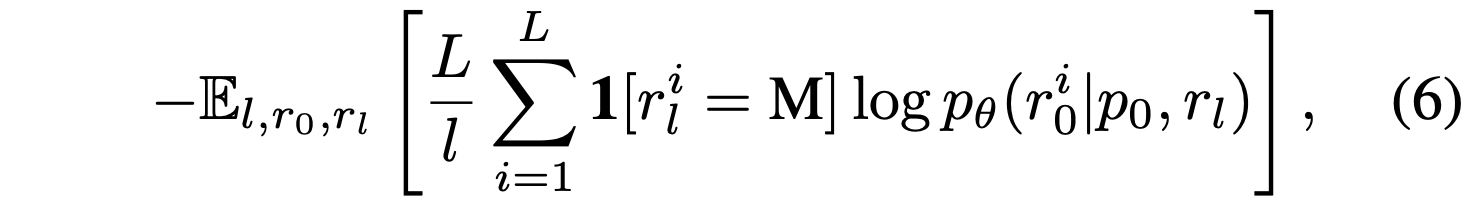
Experiments
Scalability
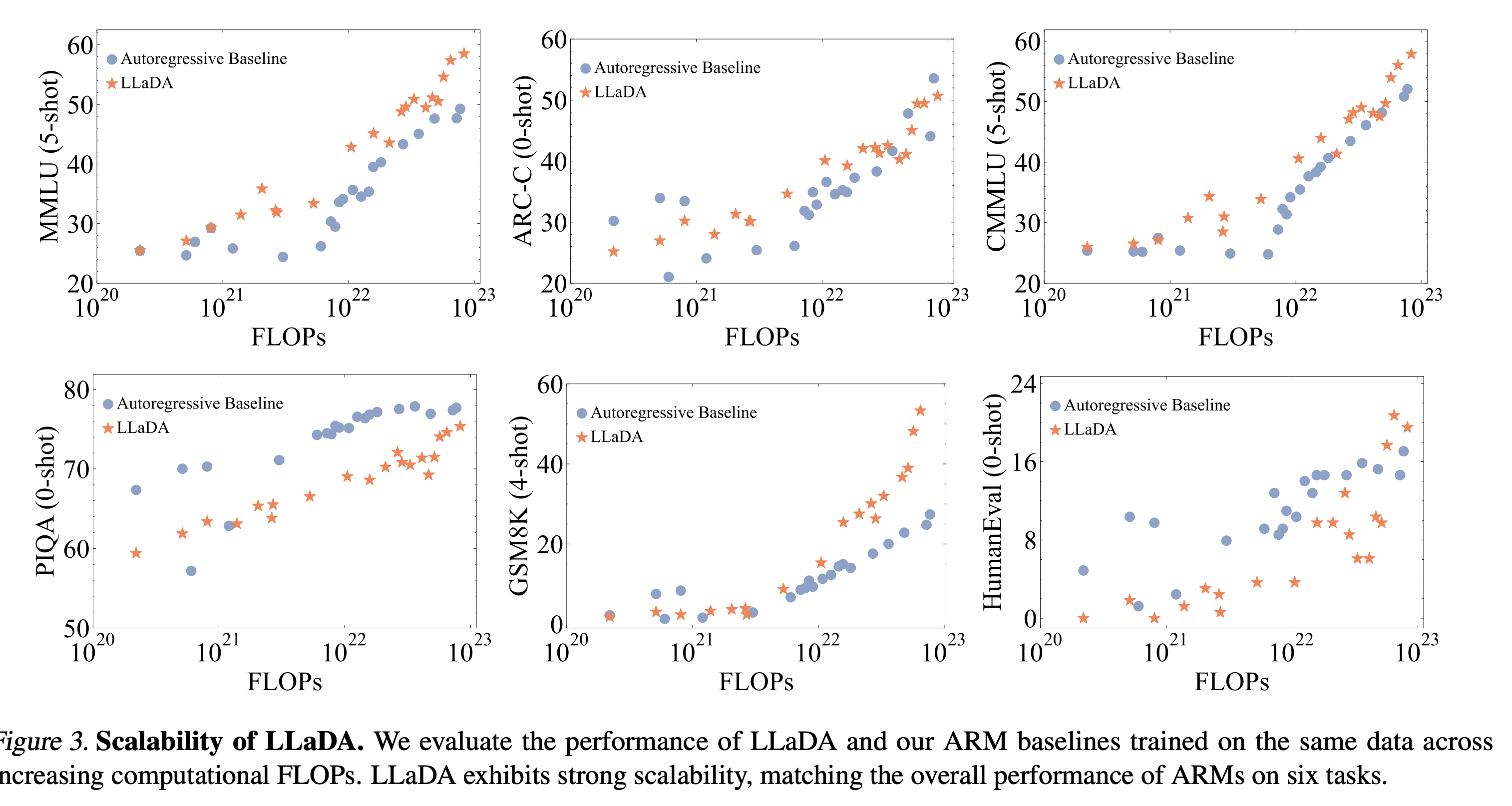
1B scale : 정확히 같은 구조, 데이터, 크기
8B scale : 약간 다른 크기, 데이터 등.
FLOPs 가 증가함에 따라 scaling이 잘 되고 있는 것을 확인할 수 있다.
Benchmark Results
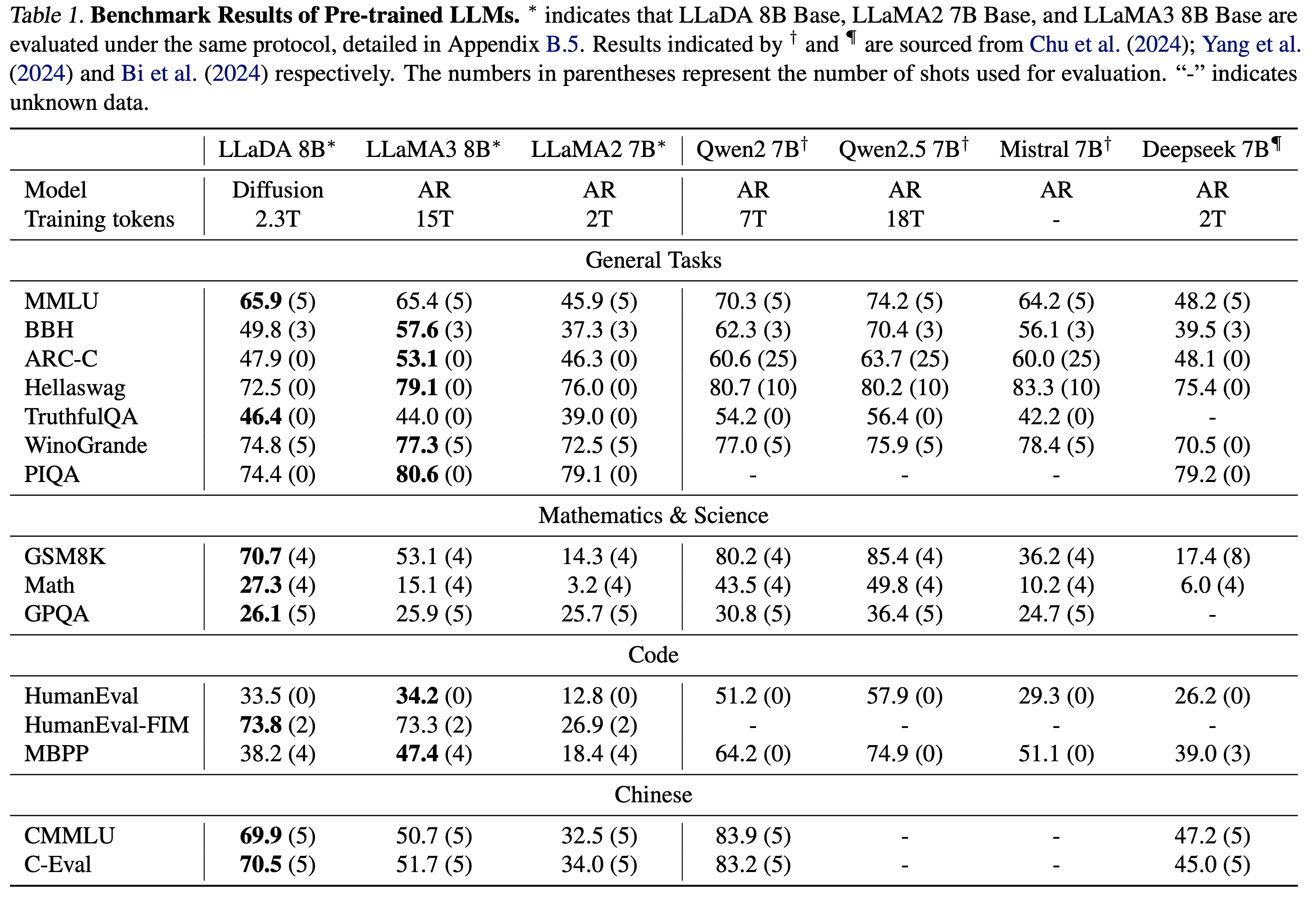
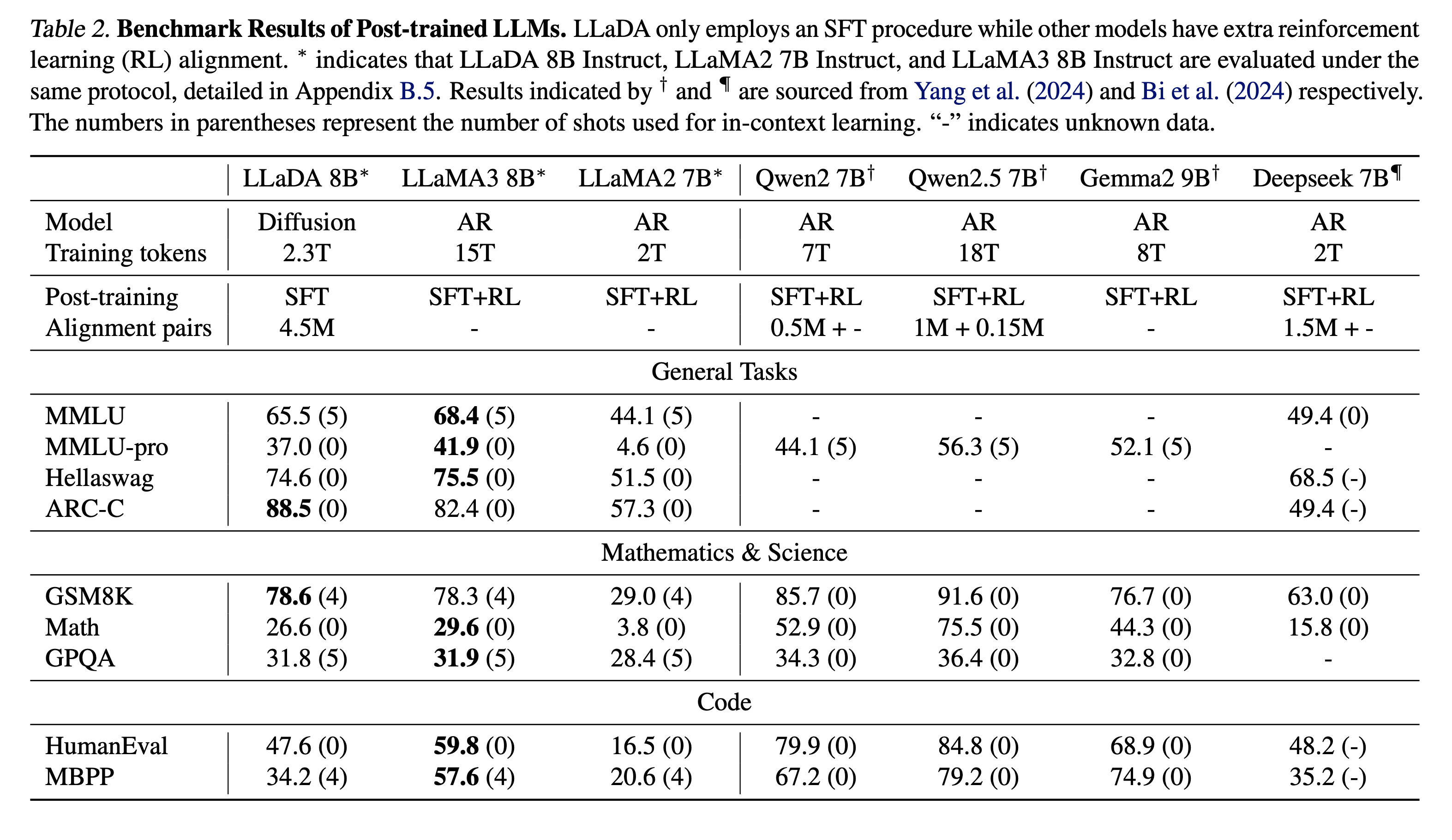
사전학습 후 제로샷 결과와 SFT 결과를 모두 기재했다. 수학과 중국어 태스크를 특히 잘 하는 것을 확인할 수 있었고 못하는 태스크의 경우에는 데이터 퀄리티의 차이에서 기인할 것이라고 말했다. 또한 RL-based alignment나 여러가지 최적화 기술들을 사용한다면 더 나은 성능을 만들 수 있을 것이라고 주장한다. 솔직히 약간의 성능 차이가 분명히 존재하지만, ARM이 아닌 다른 모델으로서 유사한 수준의 성능을 달성한 대형 언어모델이 이전에 없었기 때문에 유의미한 결과라고 생각한다.
Reversal Reasoning
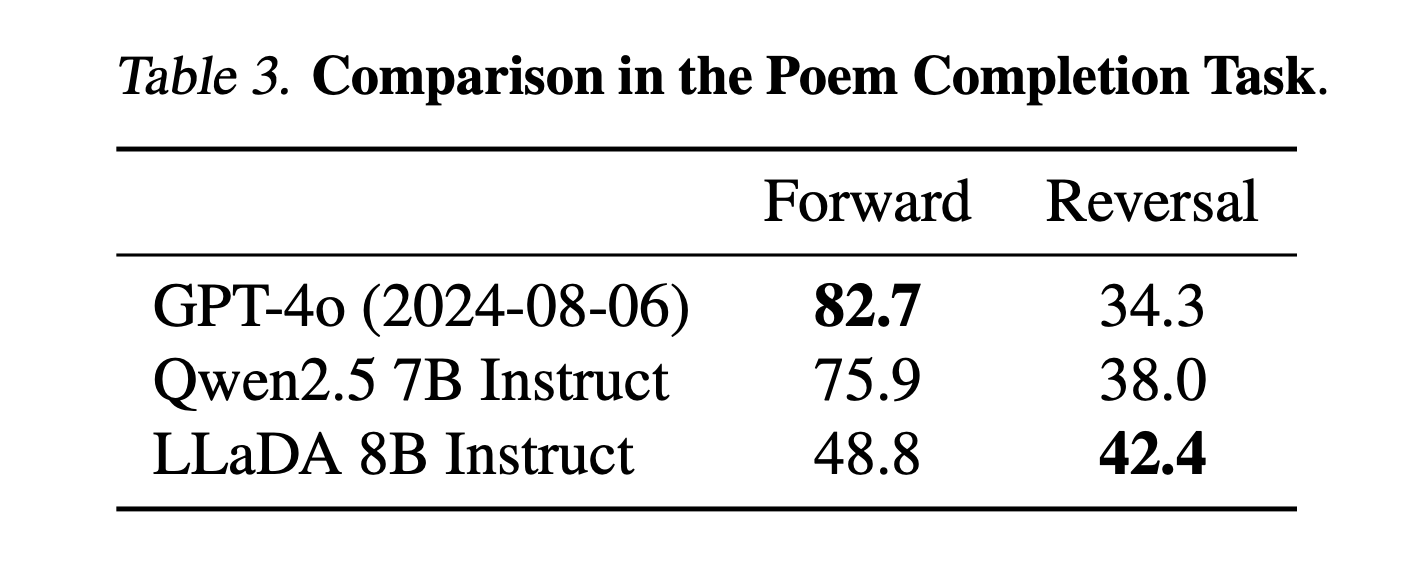
거꾸로 답변을 찾아가는 과정을 기존 대형모델들이 잘 하지 못한다는 점을 지적한다. 해당 논문에서는 중국어 시를 제시한 뒤, 앞구절이나 뒤 구절을 정확히 답변할 수 있는지를 평가했다. 뒷구절에 대한 평가의 경우 기존 모델들의 성능이 확연히 높았으나, 앞구절에 대한 경우는 (Reverse) Diffusion model이 더 좋은 성능을 보였다. Diffusion model은 특히 앞, 뒤 상관없이 편향되지 않은 성능을 보였다. Forward 에 대한 성능이 기존 모델들보다 많이 부족하긴 하지만, 학습한 데이터양이나 모델 크기를 고려한다면 좋은 성능을 보인 것이라고 생각할 수 있어보인다. 여기서 결국 LLaDA는 inductive bias 없이 모든 토큰을 균일하게 고려하여 균형잡힌 성능을 보여줄 수 있었다고 말할 수 있겠다. 실제 모델의 생성 결과는 아래와 같다.

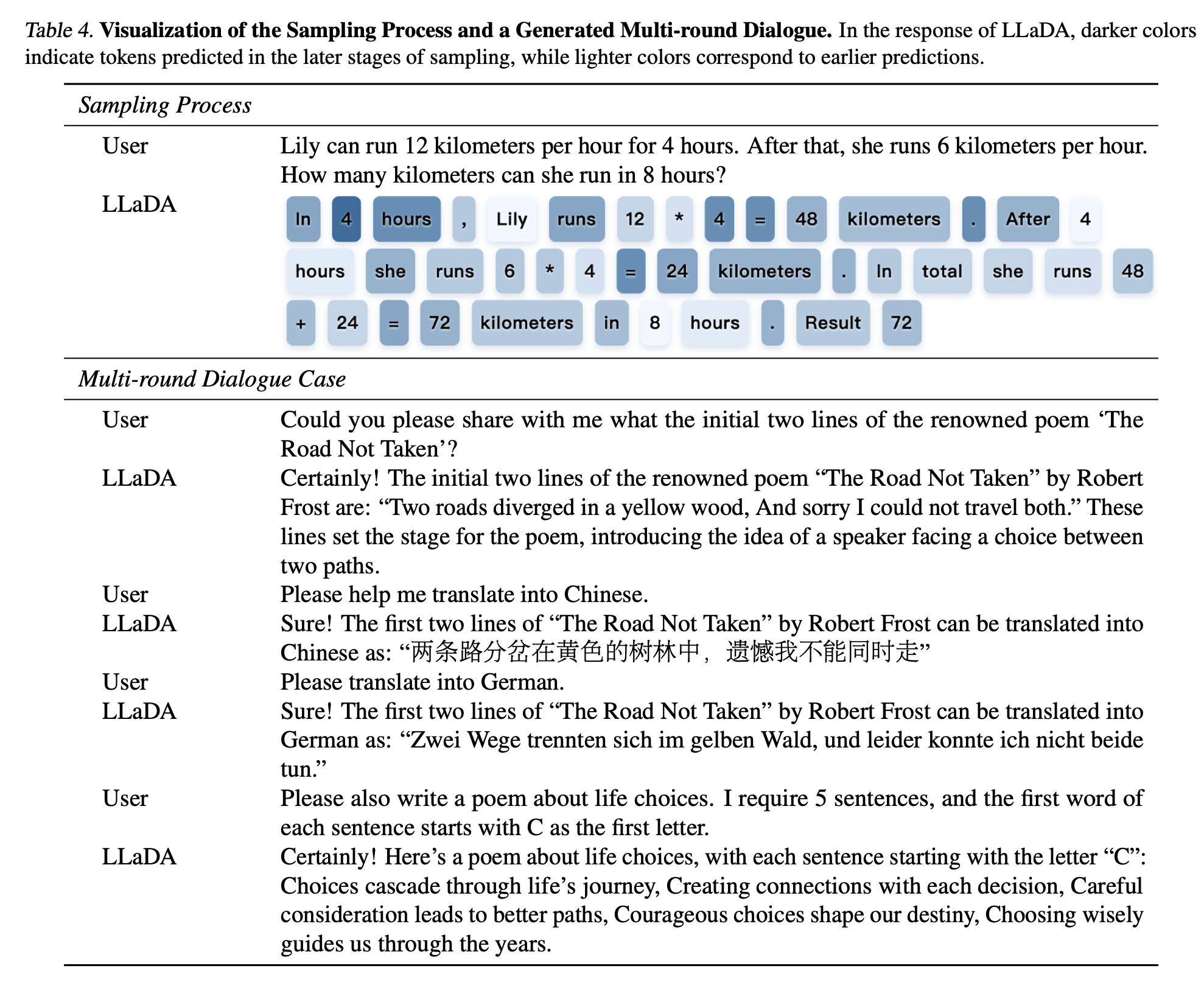
Case Study
실제 생성 결과에 대한 예시를 보여준다. multi-round dialogue나 sampling을 모두 잘 하는 것으로 보여서 여러가지 사용 가능성이 충분해 보인다.
Conclusion
결론적으로 기존 모델들이 Autoregressive 구조로 모델링하는 것에 집중하고 있었다면 해당 모델은 Diffusion modeling을 채택하여 동시에 모든 토큰을 생성해내는 방식으로 새로운 패러다임을 제시했다는 데에 의의가 있다고 볼 수 있다.
아마도 training, inference 과정에서 현재 autoregressive 방식에 비해서 sampling step이 훨씬 많이 필요할 것이므로 여기서 오는 computational inefficiency가 존재하겠지만, 이런 부분들을 개선할 수 있다면 좋은 대안 모델이 될 수 있을 것이라 생각된다. 코드와 체크포인트를 공개해준다면 추가적인 확인과 실험도 진행해보고자 한다.
