When modern software applications run slowly, the problem is usually data, too much data to be processed.
Terms
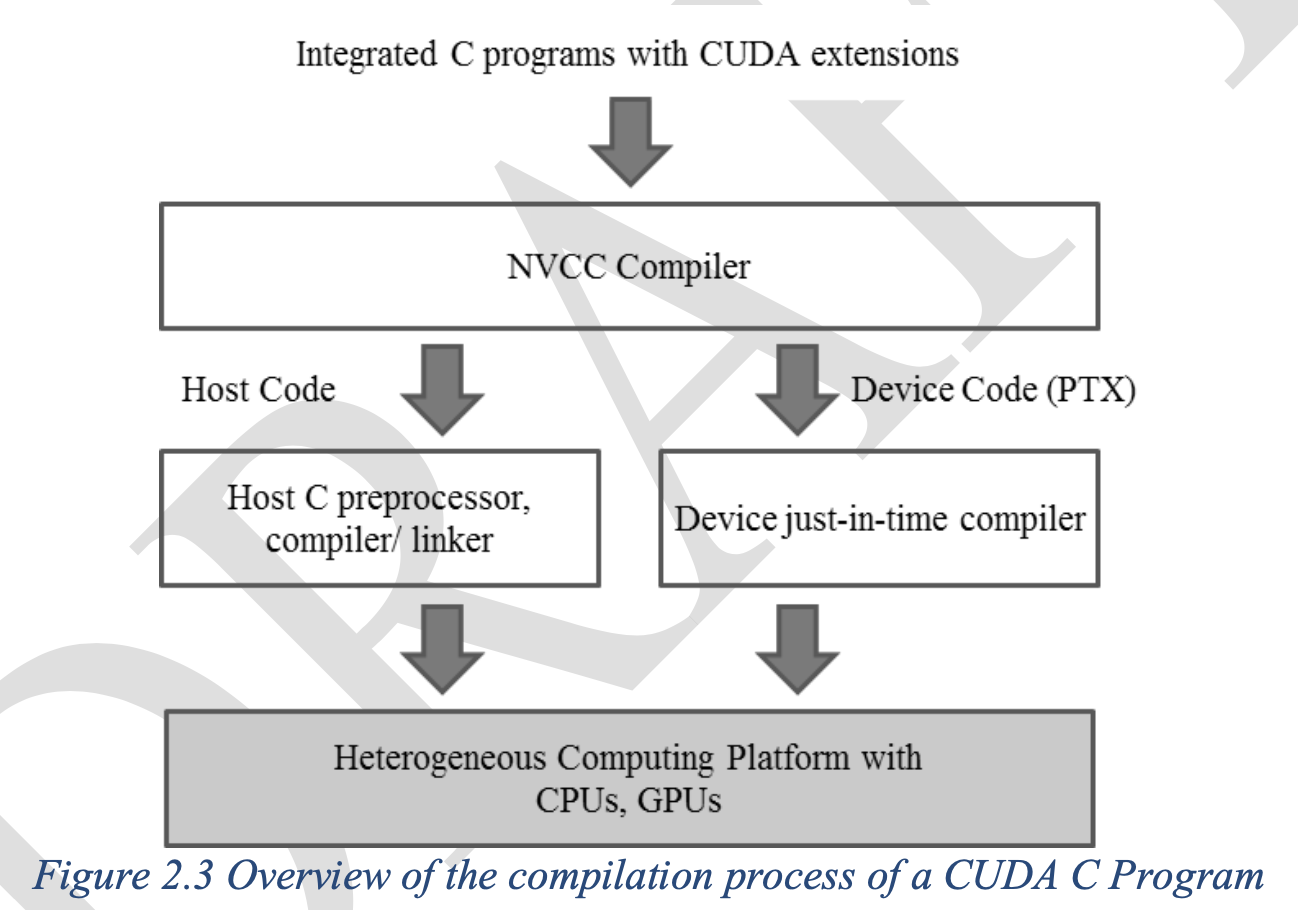
host = CPU / devices = GPUs
kernels = The device code is marked with CUDA keywords for data-parallel functionsand their associated helper functions and data structures.
grid all the threads that are generated by a kernel launch
Threads a simplified view of how a processor executes a sequential program in modern computers. It consists of the followings:
- code of the program
- particular point in the code that is being exeucted
- values of its variables and data structures
- sequential execution
CUDA API for managing device global memory
cudaMalloc()
- Allocates object in the device global memory
- Two parameters
- Address of a pointer to the allocated object
- Size of allocated object in terms of bytes
The address of the pointer variable should be cast to (void **) because the function expects a generic pointer; the memory allocation function is a generic function that is not restricted to any particular type of objects
cudaFree()
- Frees object from device global memory
- Pointer to freed object
cudaMemcpy()
- memory data transfer
- Requires four parameters
- Pointer to destination
- Pointer to source
- Number of bytes copied
- Type/Direction of transfer (ex. cudaMemcpyHostToDevice, DeviceToHost, DeviceToDevice, or, HostToHost)
The vecAdd function, outlined in Figure 2.6, allocates device memory, requests data transfers, and launches the kernel that performs the actual vector addition.
Vector Add (Hello world of Parallel Programming)
A vector addition kernel function
// Compute vector sum C = A+B // Each thread performs one pair-wise addition __global__ void vecAddKernel(float* A, float* B, float* C, int n) { int i = threadIdx.x + blockDim.x * blockIdx.x; if (i<n) C[i] = A[i] + B[i]; }
__global__ indicates that the function is a kernel and that it can be called froma host functions to generate a grid of threads on a device

vector addition kernal launch statement
int vectAdd(float* A, float* B, float* C, int n) { // d_A, d_B, d_C allocations and copies omitted // Run ceil(n/256) blocks of 256 threads each vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n); //<<<# of block in the grid, # of threads in each block>>> }
Final host code in vecAdd
void vecAdd(float* A, float* B, float* C, int n) { int size = n * sizeof(float); float *d_A, *d_B, *d_C; cudaMalloc((void **) &d_A, size); cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice); cudaMalloc((void **) &d_B, size); cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice); cudaMalloc((void **) &d_C, size); vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n); cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost); // Free device memory for A, B, C cudaFree(d_A); cudaFree(d_B); cudaFree (d_C); }
Error Check
cudaError_t err = cudaMalloc((void **) &d_A, size);
if (error != cudaSuccess) {
printf(“%s in %s at line %d\n”, cudaGetErrorString( err), __FILE__, __LINE__);
exit(EXIT_FAILURE);
}
