◾정밀도와 재현율의 트레이드 오프
- 정밀도(Precision)과 재현율(Recall)을 조정하는 방법
- 결정 임계값을 조정해 조정할 수 있지만, 두 개는 상호 보완적인 평가지표이기 때문에 하나가 오르면 다른 하나가 떨어지기 쉽다.
# 데이터 읽기
import pandas as pd
# 와인 통합 데이터
wine = pd.read_csv('wine.csv', sep=',', index_col=0)
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)# Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print("Train Acc :", accuracy_score(y_train, y_pred_tr))
print("Test Acc :", accuracy_score(y_test, y_pred_test))
classification_report: 평가 지표를 한번에 볼 수 있다.
# classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test)))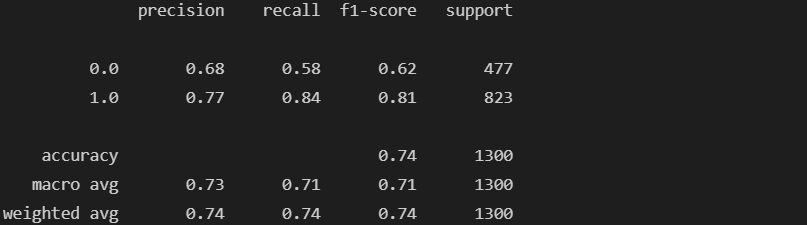
confusion matrix: Prediction 성능을 측정하기 위해 예측 value와 실제 value를 비교하기 위한 표positive negative positive TP FN negative FP TN
# confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, lr.predict(X_test)))
precision_recall curve: Threshold를 변화시키면서 Precision과 Recall을 Plot 한 Curve
# precision_recall curve
import matplotlib.pyplot as plt
import set_matplotlib_korean
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10, 8))
pred = lr.predict_proba(X_test)[:, 1]
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label='precision')
plt.plot(thresholds, recalls[:len(thresholds)], label='recall')
plt.grid()
plt.legend()
plt.show()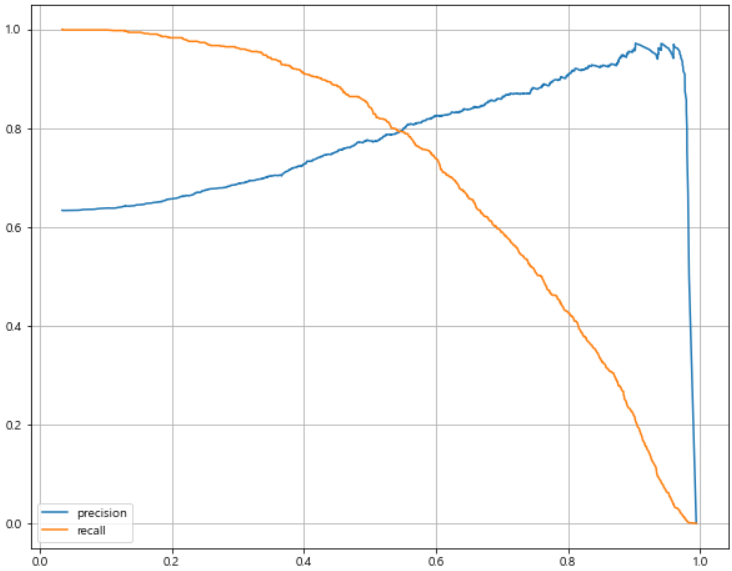
- 기본적인 경우
threshold = 0.5로 계산
# 예측 확률과 값 연결
import numpy as np
pred_proba = lr.predict_proba(X_test)
np.concatenate([pred_proba, y_pred_test.reshape(-1, 1)], axis=1)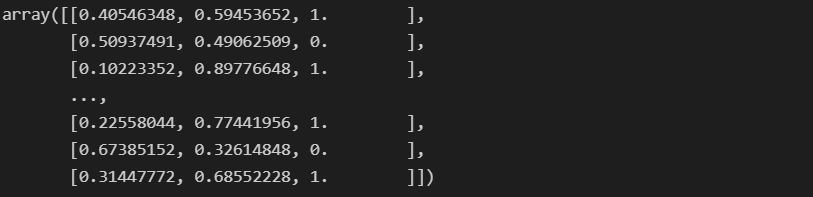
# threshold 값 변경하기 - Binarizer
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:, 1]
binarizer.threshold, pred_bin
# classification_report 재확인
from sklearn.metrics import classification_report
print(classification_report(y_test, pred_bin))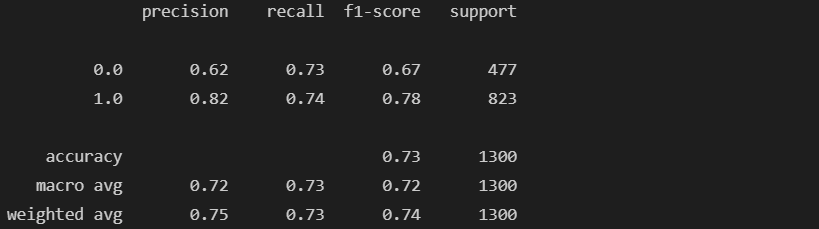

후라이드 치킨