◾자연어 처리 설치
Windows, Python 3.8 기준
- JDK 다운로드 및 환경변수 설정
- JAVA_HOME
- pip install konlpy : 한글 자연어 처리
- pip install tweepy==3.10.0
- conda install -y -c conda-forge jpype1==1.0.2
- conda install -y -c conda-forge wordcloud
- conda install -y -c nltk
- conda install -y scikit-learn
- punkt, stopwords 다운로드
import nltk
nltk.download()◾형태소 분석
- 한국어 자연어 처리 : konlpy
- 문장 - 어절 - 형태소 - 음절
- 형태소 : 언어의 최소 의미 단위
kkma 엔진
from konlpy.tag import Kkma
kkma = Kkma()
kkma.sentences("한국어 분석을 시작합니다 재미있어요~~")
kkma.nouns("한국어 분석을 시작합니다 재미있어요~~")
kkma.pos("한국어 분석을 시작합니다 재미있어요~~")
#### Hannanum 엔진
```python
from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.analyze("한국어 분석을 시작합니다 재미있어요~~")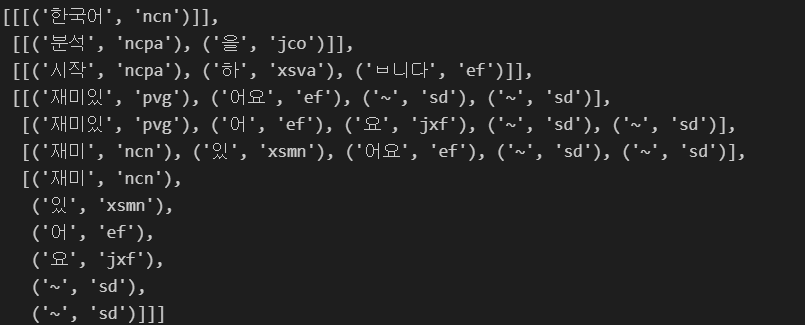
hannanum.morphs("한국어 분석을 시작합니다 재미있어요~~")
hannanum.nouns("한국어 분석을 시작합니다 재미있어요~~")
hannanum.pos("한국어 분석을 시작합니다 재미있어요~~")
Okt(Twitter) 엔진
# from konlpy.tag import Twitter -> Okt
from konlpy.tag import Okt
t = Okt()
t.nouns("한국어 분석을 시작합니다 재미있어요~~")
t.pos("한국어 분석을 시작합니다 재미있어요~~")
t.phrases("한국어 분석을 시작합니다 재미있어요~~")
t.morphs("한국어 분석을 시작합니다 재미있어요~~")
◾워드클라우드 : 이상한 나라의 엘리스
워드클라우드: 메타 데이터에서 얻어진 태그들을 분석하여 중요도나 인기도 등을 고려하여 시각적으로 늘어 놓아 웹 사이트에 표시하는 것- 각 태그들은 그 중요도(혹은 인기도)에 따라 글자의 색상이나 굵기등 형태가 변함
- 워드클라우드는 단어의 빈도만 표현하는 방법
- 이상한 나라의 앨리스
- 본문에서 'said'가 많이 등장하므로 따로 stopword 처리
text = open('alice.txt').read()
alice_mask = np.array(Image.open("alice_mask.png"))
stopwords = set(STOPWORDS)
stopwords.add("said")# 앨리스 그림
plt.figure(figsize=(8, 8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation="bilinear")
plt.axis('off')
plt.show()
- generate를 생성하고
words_를 확인하면 빈도가 있는 단어를 확인할 수 있다.
wc = WordCloud(
background_color="white", max_words=2000, mask=alice_mask, stopwords=stopwords
)
wc = wc.generate(text)
wc.words_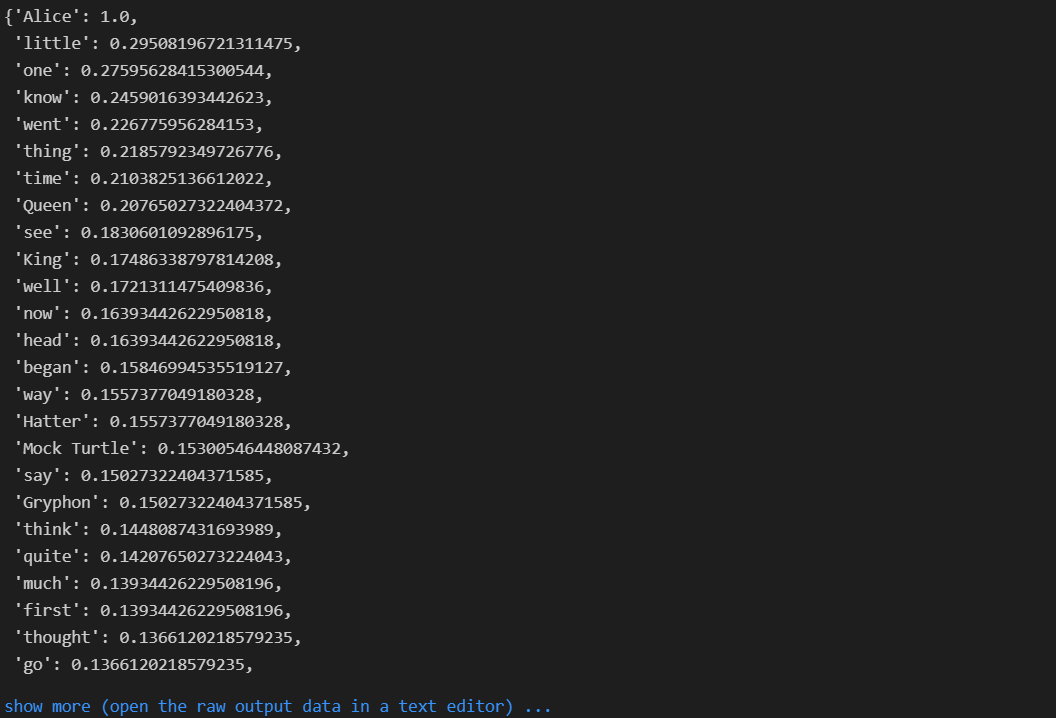
plt.figure(figsize=(12, 12))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()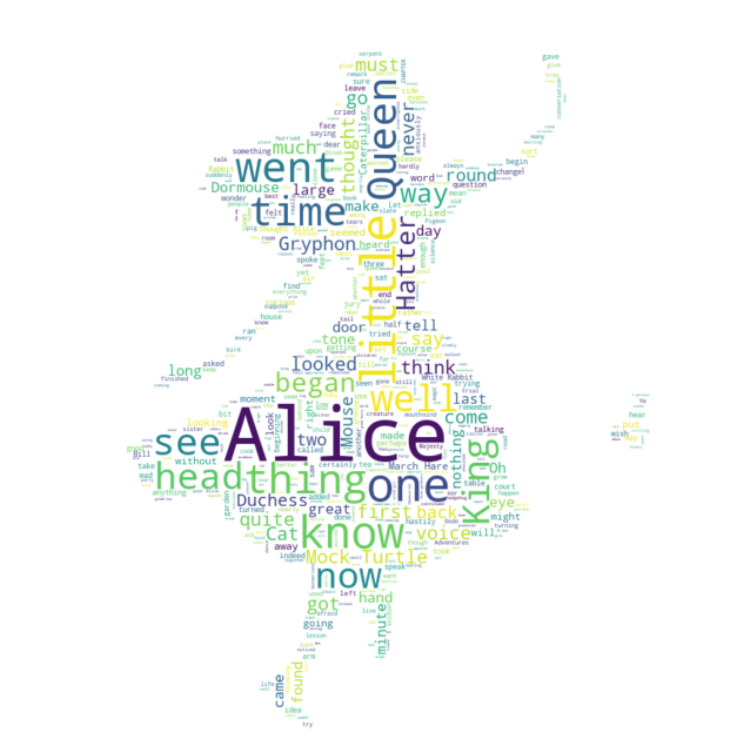

후라이드 치킨