◾자연어 처리 - 육아 휴직 관련 법안 분석
육아휴직관련 법안 대한민국 국회 제 1809890호 의안
import nltk
from konlpy.corpus import kobill
files_ko = kobill.fileids()
doc_ko = kobill.open("1809890.txt").read()
doc_ko
from konlpy.tag import Okt
t = Okt()
tokens_ko = t.nouns(doc_ko)
tokens_ko[:10]
- nltk 토큰(빈도수 포함) 분석
ko = nltk.Text(tokens_ko, name="대한민국 국회 의안 제 1809890호")
ko
print(len(ko.tokens))
print(len(set(ko.tokens)))
- 토큰 빈도별 그래프
import matplotlib.pyplot as plt
import set_matplotlib_korean
plt.figure(figsize=(12, 6))
ko.plot(50)
plt.show()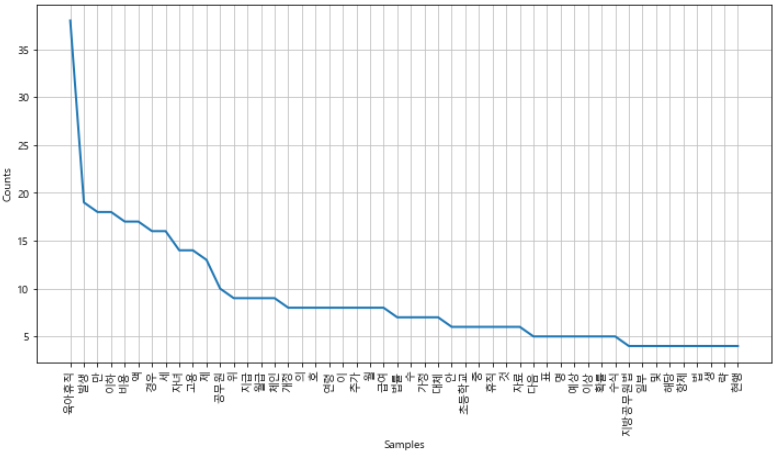
# stop_words 처리
stop_words = [
'.',
'(',
')',
',',
"'",
'%',
'-',
'X',
')',
'x',
'의',
'자',
'에',
'안',
'번',
'호',
'을',
'이',
'다',
'만',
'로',
'가',
'를',
]
ko = [each_word for each_word in ko if each_word not in stop_words]
ko[:10]
ko = nltk.Text(ko, name='대한민국 국법 의안 제 1809890호')
plt.figure(figsize=(12, 6))
ko.plot(50)
plt.show()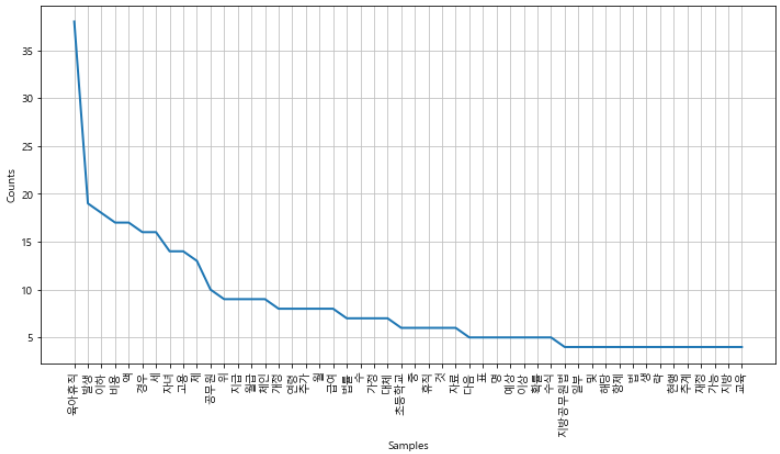
- 특정 단어의 빈도 확인
ko.count("초등학교")
- 특정 단어가 등장하는 위치 확인
plt.figure(figsize=(12, 6))
ko.dispersion_plot(["육아휴직", "초등학교", "공무원"])
plt.show()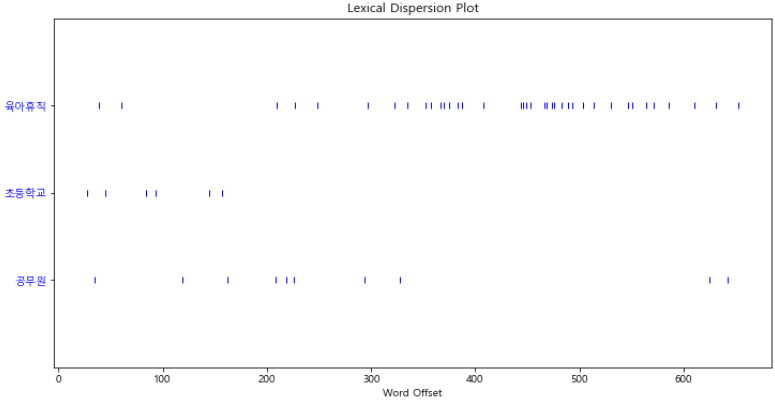
연어(collocation): 함께 위치하는 단어들이란 뜻으로, 어휘의 조합 또는 짝을 이루는 말을 일컫는다.
ko.concordance("초등학교")
- 빈도 분포 확인
ko.vocab()
from wordcloud import WordCloud
data = ko.vocab().most_common(150)
wordcloud = WordCloud(
# 한글을 wordCloud하기 위해서 폰트 변경
font_path="C:/Windows/Fonts/malgun.ttf",
relative_scaling=0.2,
background_color="white"
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
◾나이브 베이즈 정리(Naive Bayes Classifier)
나이브 베이즈 분류- 기계 학습 분야에서 특성들 사이의 독립을 가정하는 베이즈 정리를 활용한 확률 분류기의 일종이다.
- 적절한 전처리를 거치면 더 진보된 방법들과도 충분히 경쟁력을 가진다.
1. 감성 분석 : 영어
from nltk.tokenize import word_tokenize
import nltk- 학습용 데이터 준비
train = [
('i like you', "pos"),
('i hate you', "neg"),
('you like me', "neg"),
('i like her', "pos"),
]- 전체 말뭉치 만들기
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
- 말 뭉치 대비 단어가 있고 없음을 표기
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t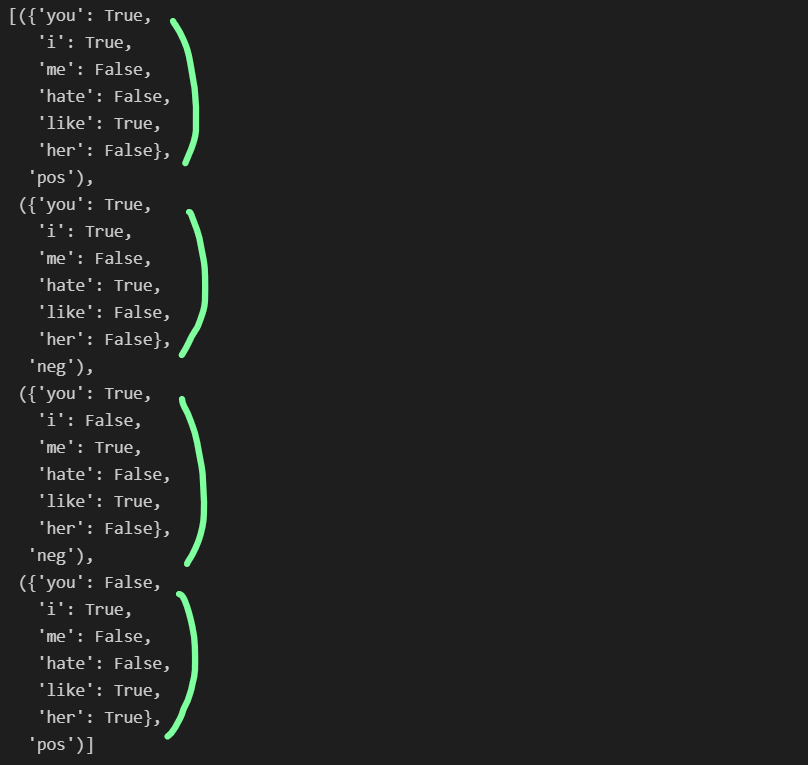
- Naive Bayes 분류기 훈련
- 각 단어별로 독립적인 확률 계산하기 때문에 Naive하다고 한다.
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()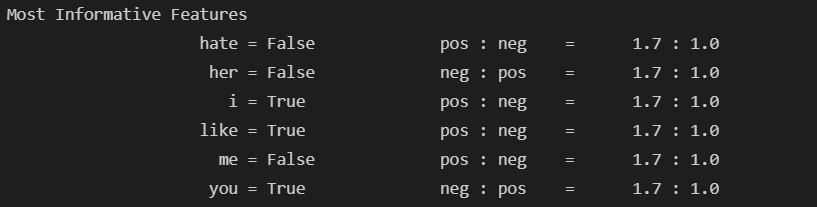
- 학습 결과 이용 테스트
test_sentence = "i like Merui"
test_sent_features = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features
- 결과
classifier.classify(test_sent_features)
2. 감성 분석 : 한글
from konlpy.tag import Okt
pos_tagger = Okt()- 학습용 데이터
train = [
('메리가 좋아', 'pos'),
('고양이도 좋아', 'pos'),
('난 수업이 지루해', 'neg'),
('메리는 이븐 고양이야', 'pos'),
('난 마치고 메리랑 놀거야', 'pos'),
]- 형태소 분석 미진행
- 메리가, 메리는, 메리랑을 모두 다른 단어로 인식한다.
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
- 계속 진행
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t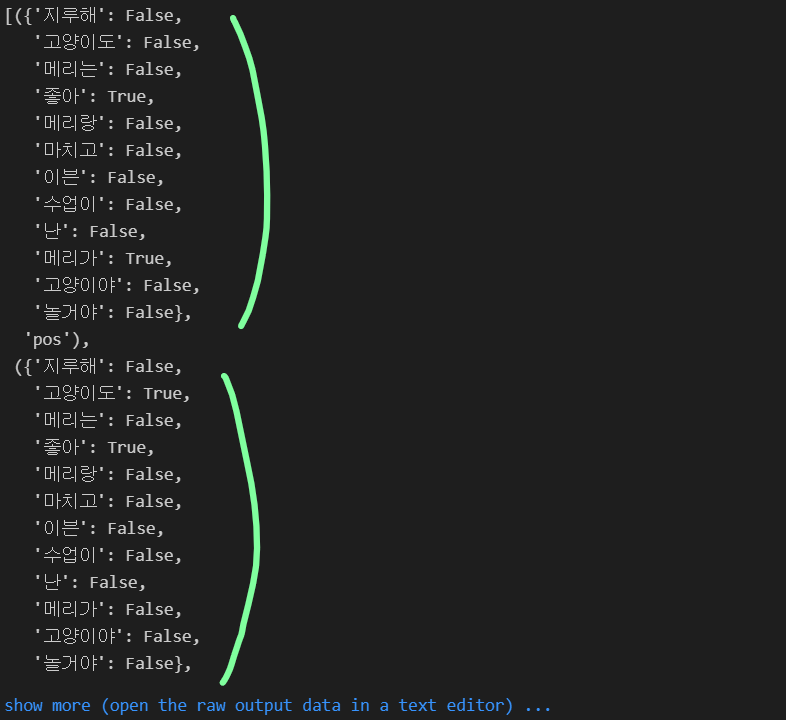
- 학습
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()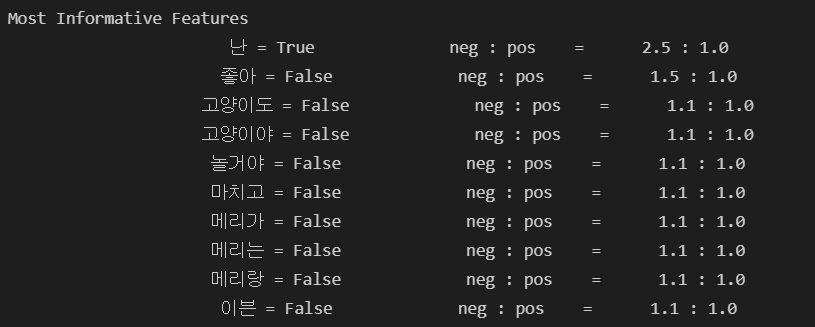
- 테스트
test_sentence = "난 수업이 마치면 메리랑 놀거야"
test_sent_features = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features
- 잘못된 결과 획득
classifier.classify(test_sent_features)
- 형태소 분석 진행
- 형태소 분석을 한 후 품사를 단어 뒤에 붙여준다.
def tokenize(doc):
return ["/".join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]
train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs
- 말뭉치 만들기
tokens = [t for d in train_docs for t in d[0]]
tokens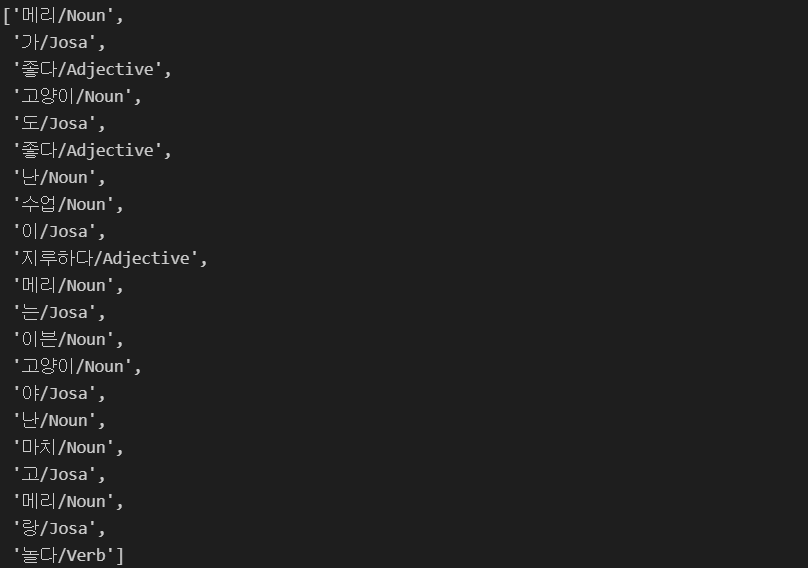
- 말 뭉치 대비 단어가 있고 없음을 표기
def term_exists(doc):
return {word : (word in set(doc)) for word in tokens}
train_xy = [(term_exists(d), c) for d, c in train_docs]
train_xy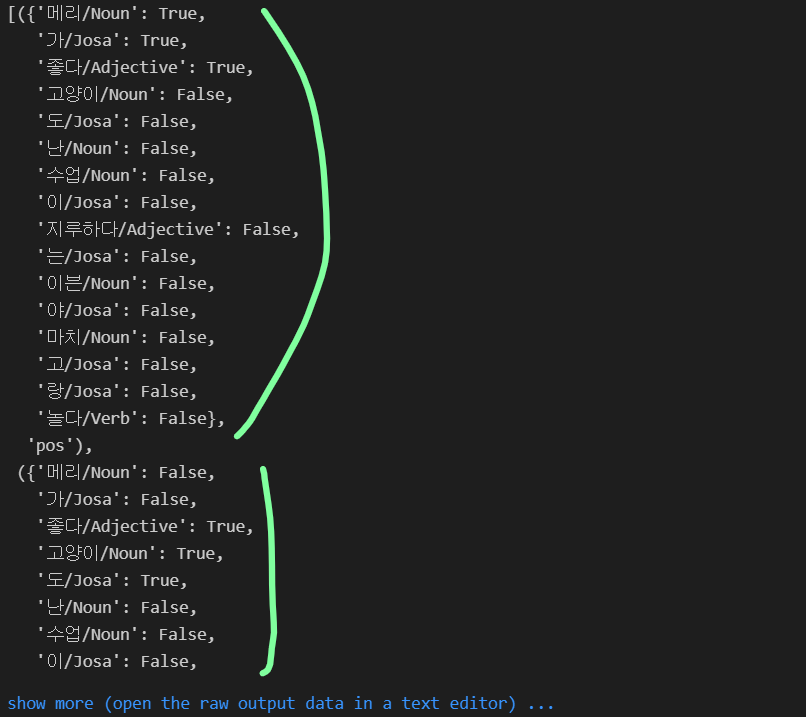
- 학습
classifier = nltk.NaiveBayesClassifier.train(train_xy)
classifier.show_most_informative_features()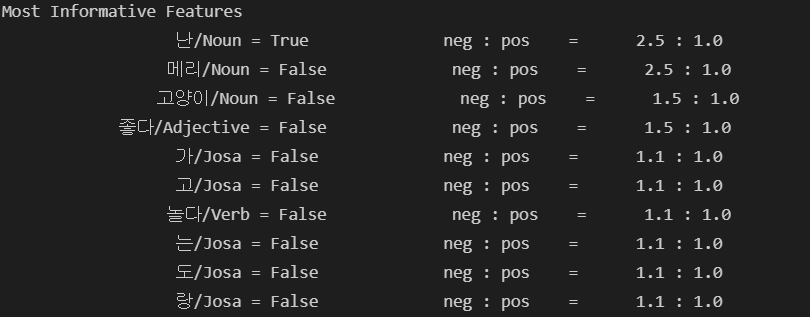
test_sentence = [("난 수업이 마치면 메리랑 놀거야")]
test_docs = pos_tagger.pos(test_sentence[0])
test_docs = (tokenize(test_sentence[0]))
test_docs
test_sent_features = {word : (word in test_docs) for word in tokens}
test_sent_features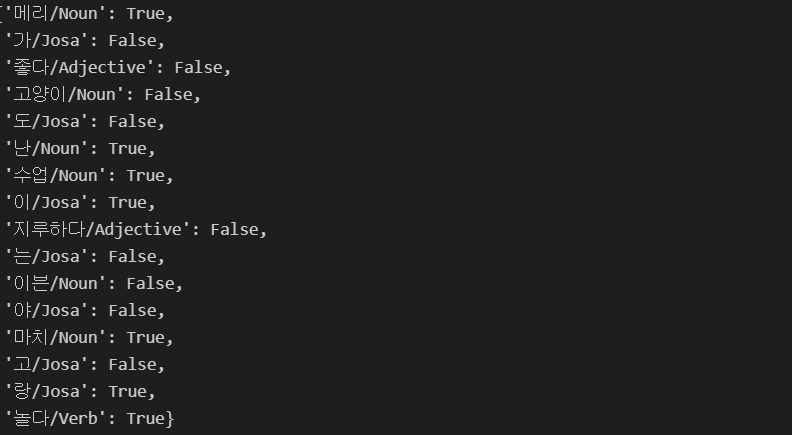
- 결과가 잘못 나온 것같은데.. 어디가 문제인지 잘 모르겠다.
- 잘못된 부분을 찾으면 수정할 예정
classifier.classify(test_sent_features)

후라이드 치킨