◾문장 유사도 측정
- 두 점 사이의 거리를 구하는 것 : 유클리드 거리()
- 문장을 점처럼 일종의 벡터로 표현할 수 있다면 거리를 구하여 유사한 문장을 찾을 수 있다.
CountVectorizer,TfidfVectorizer등으로 문장을 벡터로 변환할 수 있다.
◾Count Vectorize
CountVectorizer- 단어들의 카운트(출현 빈도(frequency))로 여러 문서들을 벡터화, 카운트 행렬, 단어 문서 행렬 (Term-Document Matrix, TDM))
- 모두 소문자로 변환시키기 때문에 me 와 Me 는 모두 같은 특성이 된다.
- CountVectorizer 선언
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)- 훈련용 문장
- 훈련용 문장 구성
contents = ['상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아']- 형태소 분석 엔진 선언(한글은 형태소 분석이 필수)
from konlpy.tag import Okt
t = Okt()Okt().morphs(): 텍스트를 형태소 단위로 나누는데, 이때 각 단어에서 어간을 추출
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens
nltk로 구분하기 쉽도록 형태소로 나눈 것으로 다시 문장으로 합쳐준다.
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize
- 벡터 라이즈 수행
- 네 개의 문장에 전체 말뭉치 단어는 17개
X = vectorizer.fit_transform(contents_for_vectorize)
X
num_samples, num_features = X.shape
num_samples, num_features
# vectorizer.get_feature_names_out() : ndarray 형태로 반환
vectorizer.get_feature_names()
- 벡터 형태 확인
X.toarray().transpose()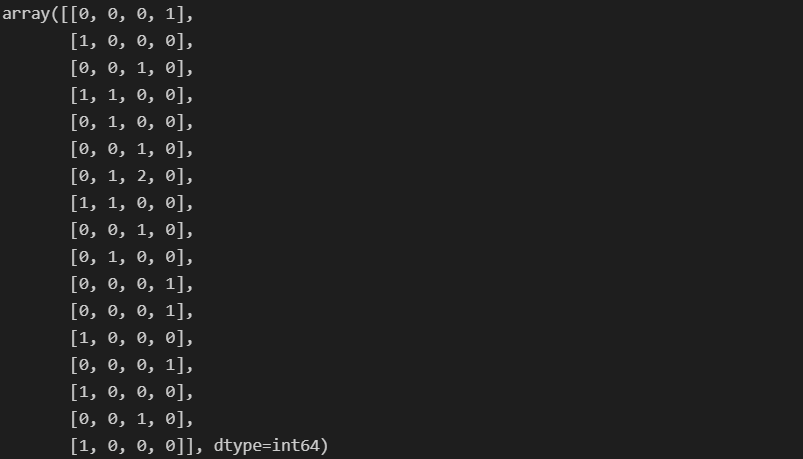
- 테스트용 문장
- 테스트용 문장
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize
- 벡터로 표현
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
- 거리 계산
- 단순 기하학적인 거리
- scipy의 linalg 사용 : 선형 대수 함수
- Norm은 벡터의 길이 혹은 크기를 측정하는 방법(함수)
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]
dist
print('Best post is',dist.index(min(dist)), 'dist =', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])
- 벡터 확인
- 관건은 벡터로 잘 만드는 것과 벡터 사이의 거리를 잘 계산하는 것
for i in range(0, len(contents)):
print(X.getrow(i).toarray())
print('-'*40)
print(new_post_vec.toarray())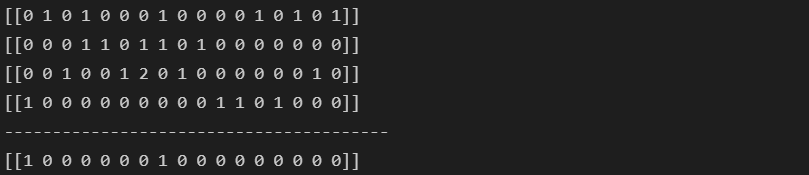
◾Tfidf Vectorize
TF-IDF: 정보 검색과 텍스트 마이닝에서 이용하는 가중치로 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치- 위키 피디아
- 한 문서에서 많이 등장한 단어에 가중치를(Term Freq.) 전체 문서에서 많이 나타나는 단어는 중요하지 않게(Inverse Document Freq.)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')- 훈련용 데이터(Count Vecotize의 데이터 사용)
X = vectorizer.fit_transform(contents_for_vectorize)
num_samples, num_features = X.shape
num_samples, num_features
X.toarray().transpose()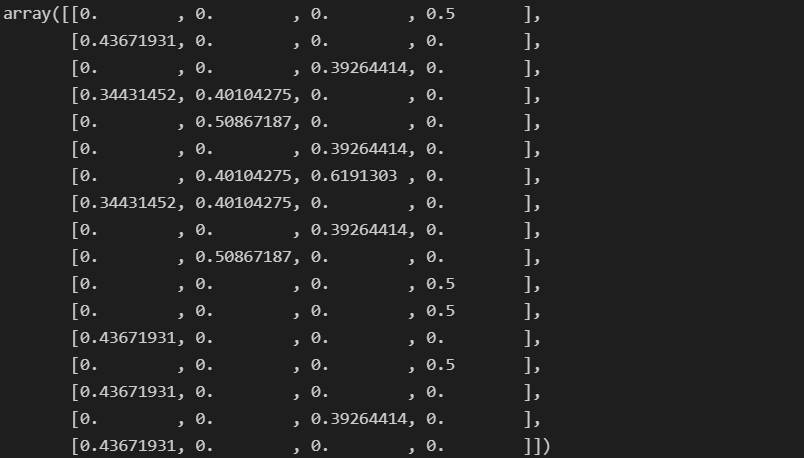
- 테스트용 데이터(Count Vectorizer 데이터 사용)
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
- 거리 계산
- 두 벡터의 크기를 비교할 때 1로 normalized하여 비교한다.
- 한 쪽 특성이 과하게 도드라지는 것을 막을 수 있다.
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
dist = [dist_norm(each, new_post_vec) for each in X]
dist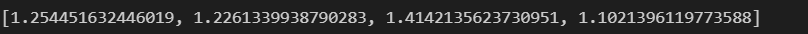
print('Best post is',dist.index(min(dist)), 'dist =', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])

후라이드 치킨