◼import
import pandas as pd
import numpy as np
import re
import folium
import googlemaps
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
from urllib.parse import urljoin
from tqdm import tqdm◼개요
- 시카고 최고의 샌드위치 50 기사 : 링크
- 식당명, 메뉴명, 가격,주소, 위치 추출
- 지도에 각 식당 시각화
◼메인 페이지 분석
- 페이지 요청
- url_base = 'https://www.chicagomag.com'
- url_sub = '/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/'
- 관리를 위해 base와 sub로 분리
# User-Agnet 생성 모듈
from fake_useragent import UserAgent
url_base = 'https://www.chicagomag.com/'
url_sub = '/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/'
url = url_base + url_sub
# html = urlopen(url) : Error 403 서버에서 접근 차단(자동 봇 차단)
# 크롬 개발자 도구 -> Network 상세 내용 확인
# User-Agent 생성
# ua = UserAgent()
# ua.ie
# req = Request(url, headers={'User-Agent' : ua.ie})
req = Request(url, headers={'User-Agent' : "Chrome"})
html = urlopen(req).read()
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
- 구글 크롬 개발자 도구를 활용해 순위 부분의 태그 및 속성 확인
- 태그
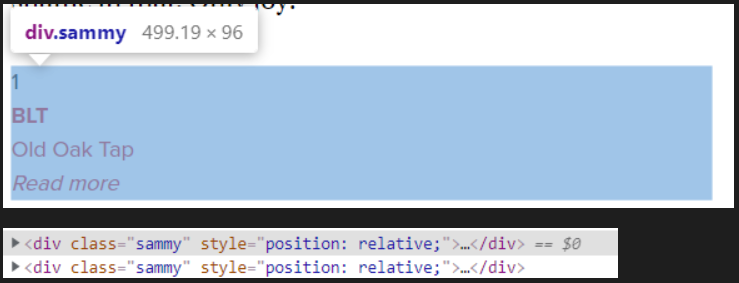
div, 클래스sammmy확인
- 태그
- find_all 명령 사용 (또는 selcet 명령 사용)
print(len(soup.find_all("div", class_="sammy"))) # 개수 확인
print(soup.find_all("div", class_="sammy"))
# print(soup.select('div.sammy'))
- 한 항목 확인
tmp_one = soup.find_all("div", class_="sammy")[0]
# 랭킹
print(tmp_one.find(class_="sammyRank").get_text())
# 가게 이름, 메뉴
print(tmp_one.find(class_="sammyListing").get_text())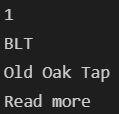
- re 모듈의 split으로 메뉴, 가게명 분리
tmp_string = tmp_one.find(class_="sammyListing").get_text()
# \n 또는(|) \r\n인 경우 분리
print(re.split('\n|\r\n', tmp_string))
print(re.split('\n|\r\n', tmp_string)[0])
print(re.split('\n|\r\n', tmp_string)[1])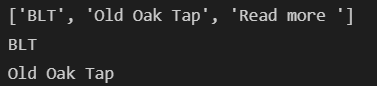
- 링크 주소 확보 : ("a").get("href")
print(tmp_one.find('a').get("href"))
- 반복문을 통해 각 정보 확보
# 각 정보를 담을 빈 리스트
# 모든 정보를 얻은 후 DataFrame으로 합치면 된다.
rank = []
main_menu = []
cafe_name = []
url_add = []
# div의 sammy 태그 추출
list_soup = soup.find_all("div", class_="sammy")
# 정보 추출
for item in list_soup:
# 랭킹
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
# 메인 메뉴
main_menu.append(re.split('\n|\r\n', tmp_string)[0])
# 카페 이름
cafe_name.append(re.split('\n|\r\n', tmp_string)[1])
# url 주소
# urljoin(a, b) : b가 상대 주소라면 a와 결합하고 b가 절대 주소라면 결합하지 않는다.
url_add.append(urljoin(url_base, item.find('a').get('href')))- 확보 데이터 DataFrame으로 정리
data = {"Rank" : rank, "Menu" : main_menu, "Cafe" : cafe_name, "URL" : url_add}
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df = pd.DataFrame(data)
df.head(2)
- 데이터 저장
df.to_csv(
"../data/03/03. best_sandwiches_list_chicago.csv", sep=",", encoding="UTF-8"
)◼하위 페이비 분석
- 데이터 확인
df = pd.read_csv('../data/03/03. best_sandwiches_list_chicago.csv', index_col = 0)
df.head(2)
- 구글 크롬 개발자 도구를 활용해 순위 부분의 태그 및 속성 확인
- 태그 p, 클래스 addy 확인
# 페이지 확인
req = Request(df.get("URL")[0], headers={'User-Agent' : 'Chrome'})
# req = Request(df.get("URL")[0], headers={'User-Agent' : ua.ie})
html = urlopen(req)
soup_tmp = BeautifulSoup(html, "html.parser")
print(soup_tmp.prettify())
- 가격과 주소 확인
- 한 줄로 이루어진 것을 확인
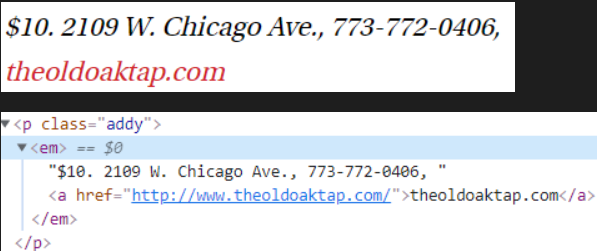
# 태그 p, 클래스 addy로 확인
soup_tmp.find('p', class_='addy').get_text()
정규식(Regular Expression)- .x : 임의의 한 문자(x가 마지막으로 끝난다)
- x+ : x가 1번이상 반복한다.
- x? : x가 존재하거나 존재하지 않는다.
- x* : x가 0번이상 반복한다.
- x|y : x 또는 y를 찾는다.(or 연산자와 동일하다.)
# 가격과 주소만을 가지기 위해 `.,`으로 분리
# 텍스트로 변환
price_tmp = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split('.,', price_tmp)[0]
price_tmp
- 텍스트 구성 : $숫자.(숫자) 주소
- 가격이 끝나는 지점의 위치를 이용해 주소 시작 지점을 찾을 수 있다.
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]
print(tmp)
print(price_tmp[len(tmp) + 2:])
- 반복문으로 데이터 확보
# tqdm : for문의 동작 확인
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row.get("URL"), headers={'User-Agent' : 'Mozilla/5.0'})
html = urlopen(req)
soup_tmp = BeautifulSoup(html, "lxml")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split('.,', gettings)[0]
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2 : ])
len(price), len(address)
- 데이터 프레임 추가
df["Price"] = price
df["Address"] = address
# df 수정
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()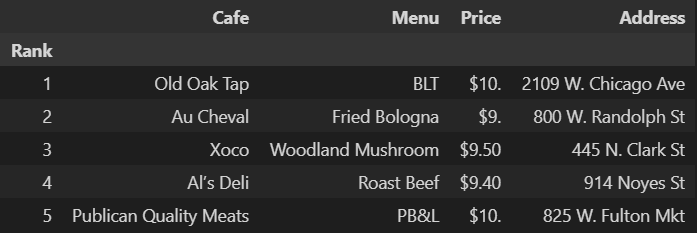
- 데이터 저장
df.to_csv(
"../data/03/03. best_sandwiches_list_chicago2.csv", sep=',', encoding="UTF-8"
)◼지도 시각화
- 데이터 확인
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.head(2)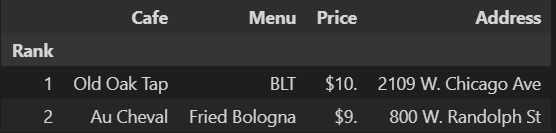
- 위도 경도 확인
gmaps_key = '개인키'
gmaps = googlemaps.Client(key=gmaps_key)
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row.get("Address") == "Multiple location":
target_name = row.get("Address")+ ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
- 데이터 프레임 추가
df["lat"] = lat
df["lng"] = lng
df.head(2)
- folium 지도 시각화
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
[row.get('lat'), row.get('lng')],
popup=row.get("Cafe"),
tooltip=row.get('Menu'),
icon=folium.Icon(
icon='coffee',
prefix="fa",
icon_color = 'black',
color = 'orange'
)
).add_to(mapping)
mapping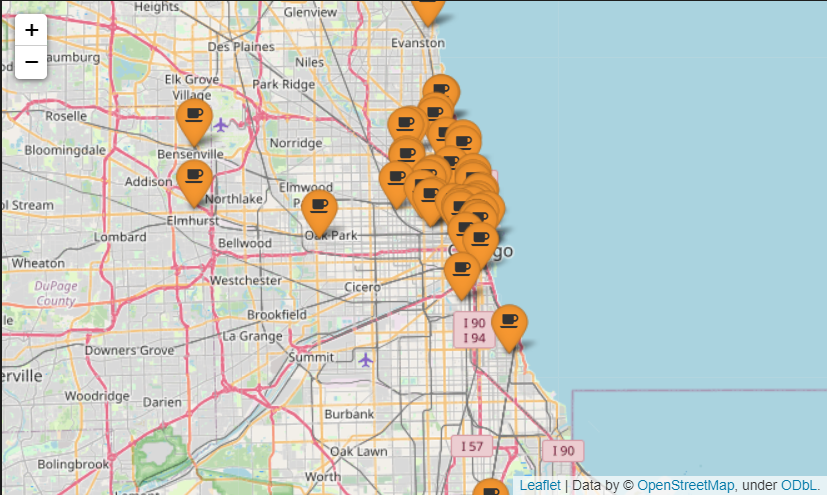

후라이드 치킨