강의 복습 내용
[DAY 18]
(5강) Sequence to Sequence with Attention
1. Seq2Seq with attention Encoder-decoder architecture Attention mechanism
- Seq2Seq Model
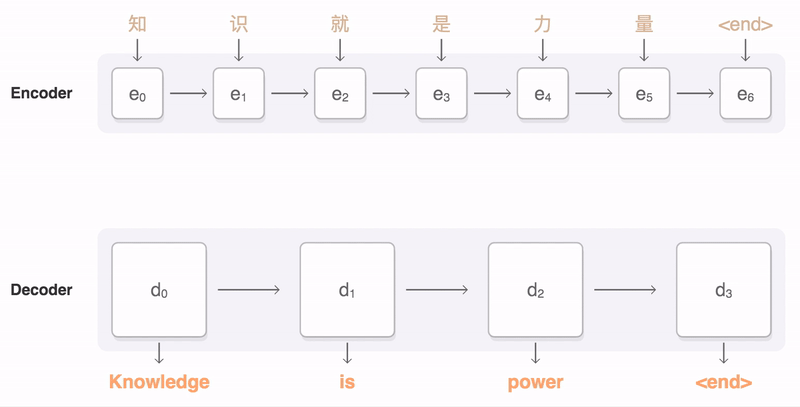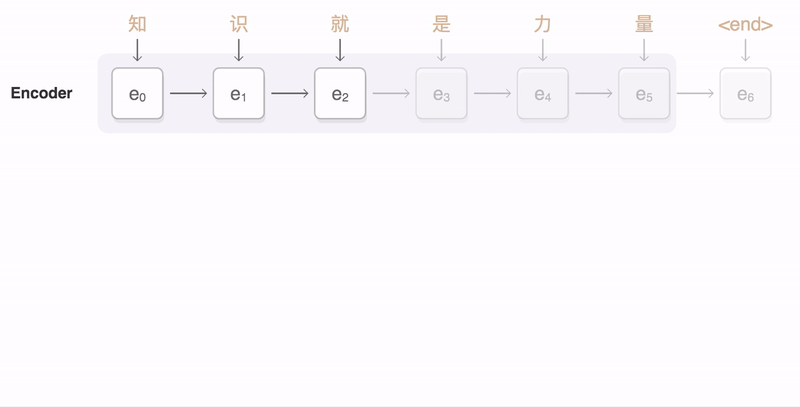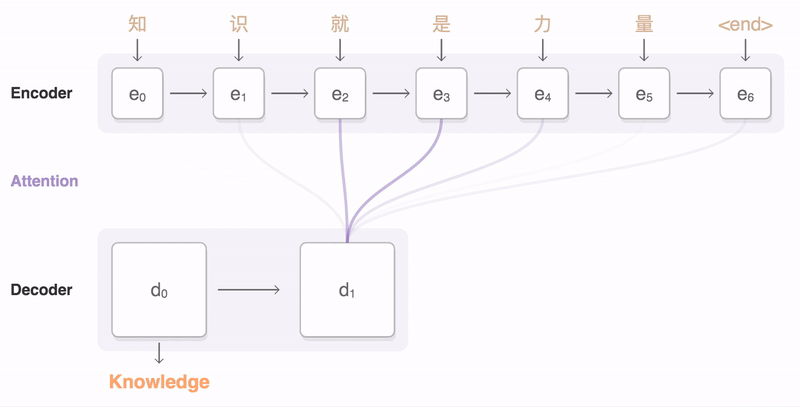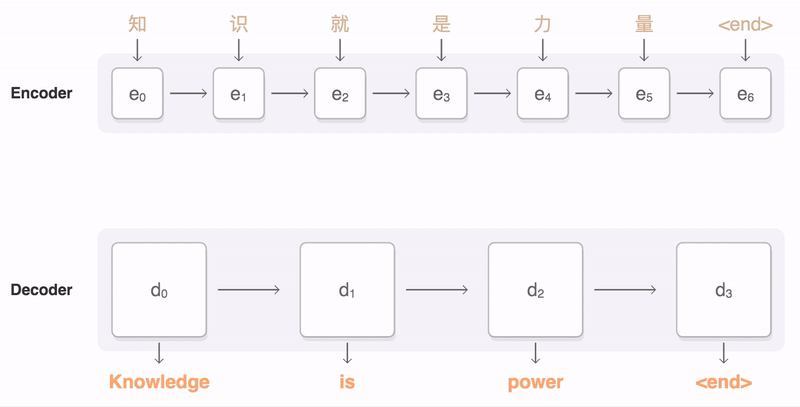
- It takes a sequence of words as input and gives a sequence of words as output
- It composed of an encoder and a decoder
- Seq2Seq Model with Attention
- Attention provides a solution to the bottleneck problem
- Core idea: At each time step of the decoder, focus on a particular part of the source sequence
- Use the attention distribution to take a weighted sum of the encoder hidden states
- The attention output mostly contains information the hidden states that received high attention
- Concatenate attention output with decoder hidden state, then use to compute 𝑦1(hat) as before
- Different Attention Mechanisms
- Luong attention: they get the decoder hidden state at time 𝑡, then calculate attention scores, and from that get the context vector which will be concatenated with hidden state of the decoder and then predict the output.
- Bahdanau attention: At time 𝑡, we consider the hidden state of the decoder at time 𝑡 − 1. Then we calculate the alignment, context vectors as above. But then we concatenate this context with hidden state of the decoder at time 𝑡 − 1. So before the softmax, this concatenated vector goes inside a LSTM unit.
- Luong has different types of alignments. Bahdanau has only a concat-score alignment model.
- Attention is Great!
- Attention significantly improves NMT performance
- It is useful to allow the decoder to focus on particular parts of the source
- Attention solves the bottleneck problem
- Attention allows the decoder to look directly at source; bypass the bottleneck
- Attention helps with vanishing gradient problem
- Provides a shortcut to far-away states
- Attention provides some interpretability
- By inspecting attention distribution, we can see what the decoder was focusing on
- The network just learned alignment by itself
- Attention significantly improves NMT performance
- Attention Examples in Machine Translation
- It properly learns grammatical orders of words
- It skips unnecessary words such as an article
(6강) Beam Search and BLEU
2. Beam search
- Greedy decoding
- Greedy decoding has no way to undo decisions!
- How can we fix this?
- Exhaustive search
- Ideally, we want to find a (length 𝑇) translation 𝑦 that maximizes
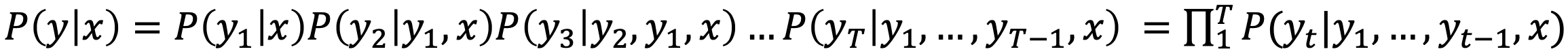
- We could try computing all possible sequences 𝑦
- This means that on each step 𝑡 of the decoder, we are tracking 𝑉𝑡 possible partial translations, where 𝑉 is the vocabulary size
- This O(𝑉𝑡) complexity is far too expensive!
- Ideally, we want to find a (length 𝑇) translation 𝑦 that maximizes
- Beam search
- Core idea: on each time step of the decoder, we keep track of the 𝑘 most probable partial translations (which we call hypothese)
- 𝑘 is the beam size (in practice around 5 to 10)
- A hypothesis 𝑦 , ... , 𝑦 has a score of its log probability:
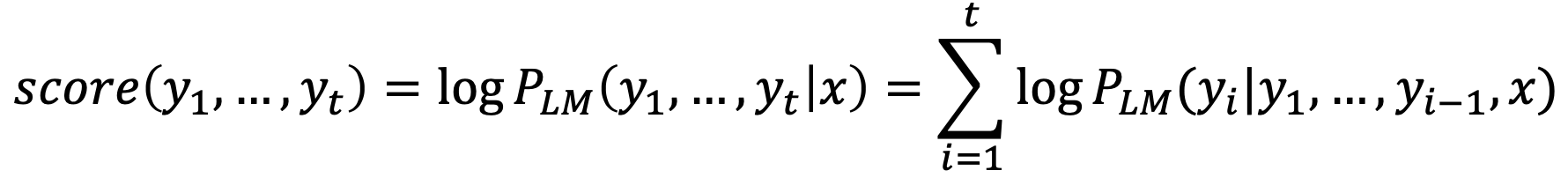
- Scores are all negative, and a higher score is better
- We search for high-scoring hypotheses, tracking the top k ones on each step
- Beam search is not guaranteed to find a globally optimal solution.
- But it is much more efficient than exhaustive search!

- Beam search: Stopping criterion
- In greedy decoding, usually we decode until the model produces a <"END"> token
- In beam search decoding, different hypotheses may produce <"END"> tokens on different timesteps
- When a hypothesis produces <"END">, that hypothesis is complete
- Place it aside and continue exploring other hypotheses via beam search
- Usually we continue beam search until:
- We reach timestep 𝑇 (where 𝑇 is some pre-defined cutoff), or
- We have at least 𝑛 completed hypotheses (where 𝑛 is the pre-defined cutoff)
- Beam search: Finishing up
- We have our list of completed hypotheses
- How to select the top one with the highest score?
- Each hypothesis 𝑦 , ... , 𝑦 on our list has a score

- Problem with this: longer hypotheses have lower scores
- Fix: Normalize by length
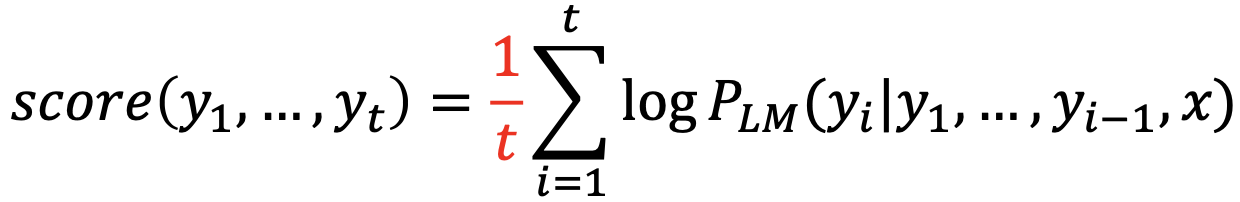
- Core idea: on each time step of the decoder, we keep track of the 𝑘 most probable partial translations (which we call hypothese)
3. BLEU score
-
Precision and Recall
- 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = #(𝑐𝑜𝑟𝑟𝑒𝑐𝑡 𝑤𝑜𝑟𝑑𝑠) / 𝑙𝑒𝑛𝑔𝑡h𝑜𝑓𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑖𝑜𝑛
- 𝑟𝑒𝑐𝑎𝑙𝑙 = #(𝑐𝑜𝑟𝑟𝑒𝑐𝑡 𝑤𝑜𝑟𝑑𝑠) / 𝑙𝑒𝑛𝑔𝑡h𝑜𝑓𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒
- 𝐹−𝑚𝑒𝑎𝑠𝑢𝑟𝑒 = 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑟𝑒𝑐𝑎𝑙𝑙 / ((𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑟𝑒𝑐𝑎𝑙𝑙) / 2)
-
BLEU score
- BiLingual Evaluation Understudy (BLEU)
- N-gram overlap between machine translation output and reference sentence
- Compute precision for n-grams of size one to four
- Add brevity penalty (for too short translations)
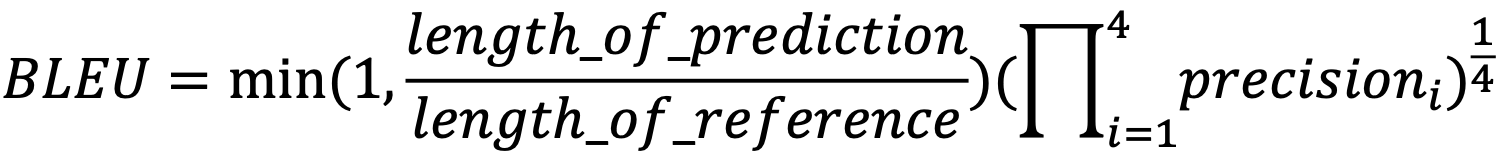
- Typically computed over the entire corpus, not on single sentences
- BiLingual Evaluation Understudy (BLEU)
Further Question
BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까요?
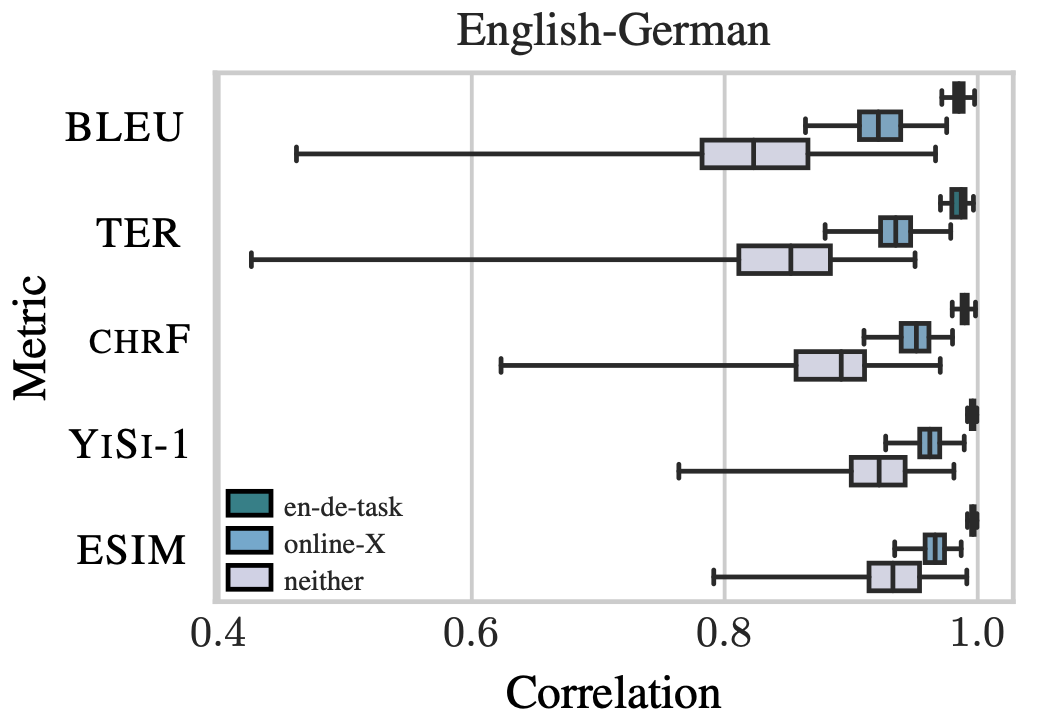
A more serious problem, however, is outlier systems, i.e. those systems whose quality is much higher or lower than the rest of the systems. We found that such systems can have a disproportionate effect on the computed correlation of metrics. The resulting high values of correlation can then lead to to false confidence in the reliability of metrics. Once the outliers are removed, the gap between correlation of BLEU and other metrics (e.g. CHRF, YISI-1 and ESIM) becomes wider. In the worst case scenario, outliers introduce a high correlation when there is no association between metric and human scores for the rest of the systems. Thus, future evaluations should also measure correlations after removing outlier systems.
Metrics are commonly used to compare two systems, and accordingly we have also investigated the real meaning encoded by a difference in metric score, in terms of what this indicates about human judgements of the two systems. Most published work report BLEU differences of 1-2 points, however at this level we show this magnitude of difference only corresponds to true improvements in quality as judged by humans about half the time. Although our analysis assumes the Direct Assessment human evaluation method to be a gold standard despite its shortcomings, our analysis does suggest that the current rule of thumb for publishing empirical improvements based on small BLEU differences has little meaning.
피어 세션 정리
강의 리뷰 및 Q&A
- (5강) Sequence to Sequence with Attention
- (6강) Beam Search and BLEU
[개인]
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제] Seq2seq Model Training with Fairseq
Seq2seq Model Training with Fairseq에 대한 것으로, 하이퍼 파라미터 변경을 통해서 어렵지 않게 해결했습니다.
마스터 클래스
마스터 소개
NLP의 주재걸 교수님 (카이스트 인공지능대학원 교수님, 전 고려대학교 컴퓨터학과 교수님)
라이브 Q&A
- 교수님께서 세부 연구분야를 선정하실 때 어떻게 결정하셨는지 스토리가 궁금합니다. P stage에서 nlp, vision 등 하위태스크를 결정해야하는데 이때 참고할 만한 팁이 있을까요?
- 컴퓨터 비전이 자연어 처리에 비해 연구하기 더 수월한 분야라고 생각한다.
- 최근에는 컴퓨터 비전에서도 self supervised learning, bigdata 등 pretrain 쪽으로 방향을 잡고 있다.
- 취업을 고려하고 있다면, 컴퓨터 비전 보다는 자연어 처리 쪽이 전략적으로 좋을 수 있다.
- 왜냐하면, 컴퓨터 비전은 쉬운만큼 경쟁이 심할 수 있기 때문이다.
- 지금은 더 관심있는 분야를 선택하면 좋을 것 같다.
- 신입 AI 개발자에게 요구하는 역량은 어느정도라고 생각하시나요? 혹은 이정도는 알고 취업을 하는게 좋겠다 라는 정도의 기준이 있나요?
- 기초적인 cs 지식 (자료구조, 알고리즘 등)
- AI에 대한 코딩 스킬도 중요하다.
- 딥러닝에 대한 지식이라면, 부스트캠프에서 다루는 정도의 지식이면 될 것 같다.
- 특히, AI 이외의 개발 기술 스택도 있어야 한다.
- 그리고 논문을 빠르게 읽고 구현할 수 있으면 좋다.
- 반어법이나 돌려말하기 등 (같은 문장이라도) 실제로 어떤 문맥과 의도를 가지고 있는지를 분석하는 화용(pragmatic)분석에까지 높은 성능을 보이는 모델은 아직 못 본 것 같은데, 이런 연구가 어떻게 진행되고 있고 앞으로 어떻게 될지, 교수님은 어떤 생각을 가지고 계신지 궁금합니다.
- 자연어 처리에서 오랫동안 해결하려고 노력했던 문제이다.
- 최근의 GPT-3, GPT-2, BERT 등과 유사한 모델들을 보면서 대용량의 데이터와 대량의 파라미터를 넣으면 모든 문제가 해결되는 것인가?에 대한 의문이 생긴다.
- 또한, 언어에 대한 깊이 있는 이해가 없어도, 언어 모델을 만들 수 있는 것인가?
- 만약 자연어 처리 문제를 완벽하게 정복하면, 범용적인 인공지능을 만들었다고 볼 수 있지 않을까 싶다.
- 많은 NLP 데이터를 구할 때 인터넷이 방대한 자료의 소스가 될 것 같은데, 웹의 여러 텍스트 데이터를 크롤링 하는 것도 현업에서 많이 쓰이나요? 크롤링이 산업 현장에서 NLP 딥러닝 엔지니어에게 유효한 기술 스택인지 궁금합니다.
- 필요한 기술 스택이라고 생각한다.
- 데이터 수집과 전처리를 외주 업체에 맡기는 것이 아닌 경우에는 직접 크롤링을 사용해서 데이터를 수집하고 전처리할 필요가 있다.
- 크롤링 기술 자체는 어렵지 않기 때문에, 충분히 할 수 있다.
- AI를 공부하다 보면, 신기하면서도 한편으로는 직관적으로 와닿지 않아 답답한 느낌이 있습니다. 교수님께서는 이 부분을 받아들이고 넘어가시나요? 이런 점들 때문에 공부를 지속하기 힘들어 지쳐가는데요, 딥러닝 분야를 공부하면서 계속해서 연구할 수 있게 하는 본인만의 원동력이 있으신가요?
- 요즘은 전반적으로 협업의 중요성이 강조되고 있다.
- 혼자서 해결하려고 하기 보다는 팀 단위로 빠르게 문제를 해결하려고 한다.
- 따라서, 혼자서 어떤 것을 준비하기 보다는 팀 단위로 준비해보는 것이 좋을 것 같다.
- 사람마다 문제를 보는 관점이 다르기 때문에, 다른 사람들과의 소통이 중요하다.
- GPT-3 를 활용하려 할 때, 네이버 같은 회사가 아니고서는 학습시킬 수가 없어서, OpenAI 의 허가를 받아야 하는 것으로 알고 있습니다. 개인이나 작은 단체는 이런 모델을 어떻게 학습하고 활용할 수 있을까요? 앞으로 더 규모가 큰 모델이 나온다면 어떻게 대처해야할까요?
- 많은 기업들과 연구자들이 가지고 있는 고민이다.
- 현재까지는 구체적인 해결 방안은 없다.
- 결국에는 자본력이 뒷받침될 수 있는 규모의 경제가 성립되어야 한다.
- 최소한 최신 모델을 따라해볼 수 있도록 정부 차원의 지원이 필요하다.
- 채용공고 기준으로 CV분야를 더 많이 찾아볼 수 있는데, 시장에서 NLP의 실제 수요는 어떨까요? AI 엔지니어로서 NLP분야의 서비스를 구현하는데 있어서 무엇을 공부하고, 어떤 함정들을 조심해야할까요? (언어학적 지식이나, 데이터 활용의 윤리적 문제 등)
- 교수님 본인의 생각으로는, 취업 시장에서는 자연어 처리가 조금 더 유리하다고 생각한다.
- 다만, 자연어 처리를 공부했다가 아니라, 성과적으로 보여줄 수 있는 무언가가 중요하다.
- 본인의 내실을 다지는 것도 중요하지만, 외부적으로 내세울 수 있는 성과도 중요하다.
- 따라서 실적이나 외부적인 스펙도 신경을 많이 쓰자.
- 방금 말씀해주신 부분의 연장선상인데,,, 실적 위주로 달성하려면.. 연구 관련 공부를 위해 탑 다운 방식의 접근 방식이 좋을까요?? 딥러닝 관련하여 공부해야 할 요소들이 매우 많은데, 바닥부터 관련 개념들을 다 섭렵해가며 공부하자니 시간이 너무 많이 드는거 같습니다.
- 최신 논문만 봐도 한계가 있으며, 기초 공부만 해도 한계가 있다.
- 양쪽의 적절한 비율을 찾아서 공부하는 것이 중요하다.
- 그렇기 때문에, 무엇을 공부할지는 사전에 미리 계획하고 공부하는 것이 중요하다.
- 자신에게 있어서 무엇이 필요한지를 알고 방향성을 갖고 공부하자.
- 박사 유학에 관심이 있는 학생입니다! 교수님께서도 석박을 해외에서 하신 것으로 알고 있는데 ML 분야에서, 넓게는 CS 분야에서 박사유학에 대한 교수님의 의견이 궁금합니다(장단점 등).
- 교수님 본인의 생각으로는 석박사를 추천한다.
- 그리고 해외를 경험할 수 있다는 것만으로도 좋은 기회라고 생각한다.
- 다만, 연구 및 기술 측면으로 보면, 전 세계적으로 상향 평준화되어 있다고 생각한다.
- 그렇기 때문에, 국내 석박도 나쁘지는 않을 것 같다.
- 다만, 미국에서 석박을 하면 미국에 취업을 할 수 있는 기회가 많이 생긴다.
- 결론은 갈 수 있다면 가라!
- 교수님 해외 온라인 석사는 어떻게 생각하시나요?
- 학위가 필요한 경우라면 모르겠지만, 일반적으로 내실이 없는 경우가 많다.
- 그리고 학비를 지불하고도 케어를 받지 못한다는 이야기를 많이 들었다.
- 실효성에 대한 의문이 든다.
- 저는 프론트엔드에 관심이 많습니다. AI와 백엔드와의 결합은 쉽게 떠오르는데 프론트엔드 단에서의 AI 기술 결합은 어떤게 존재할지 궁금합니다. 또한 이러한 분야를 공부하기 위해서는 어떤 부분을 추가적으로 살펴봐야 할까요?
- 교수님 본인의 생각으로는 굉장히 유망한 분야라고 생각한다.
- 분명 필요한 분야이지만, 프론트엔드에 적용하기에는 가성비가 떨어진다고 생각한다.
- 대학원을 가는 목적이 연구가 아닌 취업이 목적이라면 어떻게 생각하시나요? 취업을 위해서 석사 학위가 필요한 경우가 많다고 생각해서 석사까지 하고 취업할 생각을 하고 있는데, 교수님의 의견이 궁금합니다
- 최근 이런 케이스를 많이 봐왔다.
- 실제로 메이저급 회사에서도 석박사에게 더 중요한 일을 맡기는 경향이 있다.
- AI와 관련된 교육 과정은 대학원에 많이 포진되어 있다.
- 최신 기술들의 경우 학부 과정에서 다루기는 쉽지 않다.
- 그래서 일반적으로 회사들은 학사보다 석박사를 선호한다.
- 따라서, 교수님 본인 생각으로는 석박사가 나쁘지 않다고 생각한다.
- 다만, 대학원을 가는 경우, 일반적으로 조금 더 많은 기회가 있다.
- 퍼포먼스 향상을 위해서 C++을 사용하는 것으로 알고 있습니다. 애초에 python에서 사용하는 모듈이 C 혹은 C++로 구현되어 있는데, C++을 사용하는 것으로 큰 성능 향상을 얻을 수 있나요?
- 그렇다. 성능 향상을 얻을 수 있다.
- 자연어처리 석사생으로 대화 에이전트의 발화 생성에 관심을 가지고 연구중입니다. NLP 분야는 트랜스포머 이후로 업계 트렌드가 빠르게 발전하여 연구자로서 커버해야 하는 양이 많습니다. 시간이 부족하다고 느끼는데요 성공적인 논문을 쓰고 졸업하기 위해 알려주실 수 있는 연구 팁이 있을까요?
- 동료들과의 협업이 중요하다고 생각한다.
- 그리고 커뮤니케이션 스킬 또한 중요하다.
- LSTM 이나 GRU 가 transformer 이후로 패러다임이 바뀌었다고 들었는데, LSTM 이나 GRU 의 실용적 유통기한은 어느정도 일 것이라 보시나요?
- 실제로 이미 자연어 처리는 transformer로 전부 대체가 된 상황이다.
- 그렇다고 해서 LSTM GRU가 사장된 기술이냐고 하기에는 아직 섯부른 판단인 것 같다.
- 시퀀셜한 패턴이 중요한 경우에는 transformer보다 LSTM과 GRU의 성능이 더 좋을 수 있다.
후기
관심 분야가 자연어 처리이기 때문에, 재미있게 들었고 알찬 정보를 얻을 수 있었습니다. 다만, 질문과 동떨어진 답변이 많아 아쉬웠습니다.
총평
오늘은 피어세션과 마스터 클래스 그리고 과제 해설이 연속해서 진행되었습니다.
그러다 보니 피곤하기도 했고 집중력이 확 떨어졌습니다.
무엇보다 개인 공부할 시간이 줄어들어서 너무 아쉬웠습니다.
이번 주 금요일에도 비슷하게 진행된다고 하니, 마음의 준비를 단단히 해야겠습니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!
