미션
개발기간: 21/03/29 - 21/04/02
개발내용: json parser
주요기능:
jsonData를 입력하면 type과 value, 타입에 따른 속성을 분석하여
tree구조로 가시화시켜 보여준다.
개발사이트: [jsonamiParser] click😃
깃헙링크: [fe-w8-json-parser]
구현과정

파일구성: index/parsing/createHtml
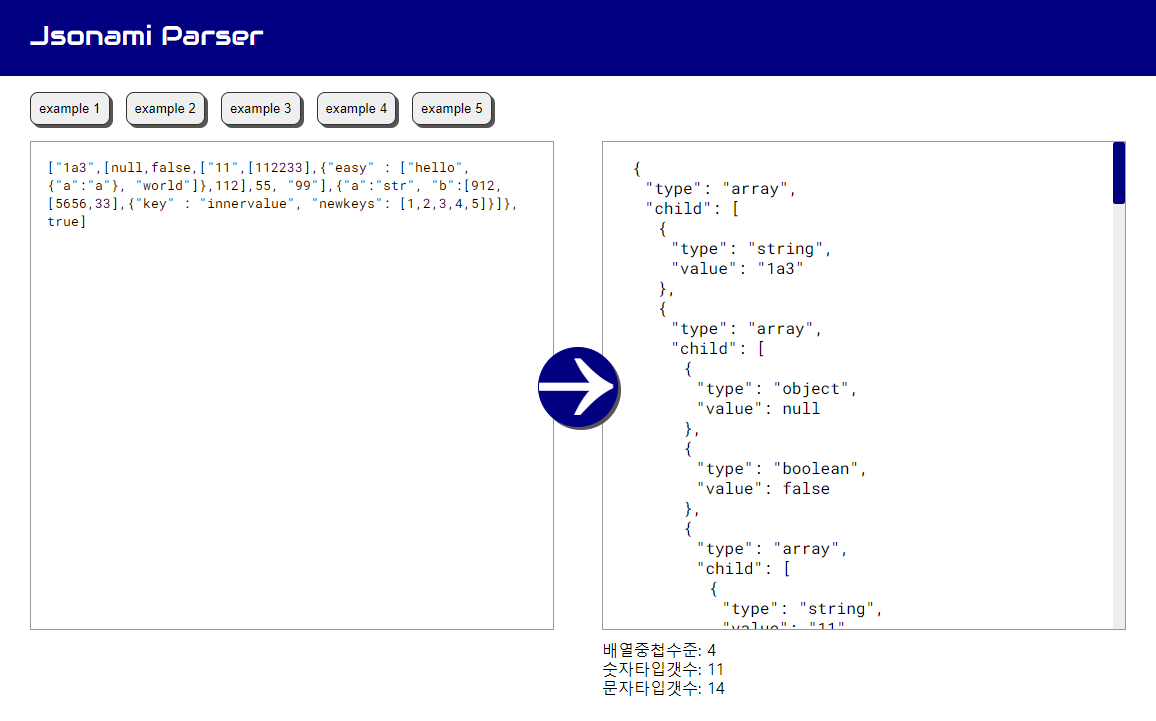
jsonParsing: tokenizer, lexer, parser 3 가지 모듈로 나누어 구현하기.
> tokenizer

1. 문자열을 순회하며 의미가 있는 최소 단위(토큰)으로 추출
-> 토큰 정보가 모인 배열 반환
2. 구분 기준
- seperator (배열 [ ] , 객체 { })
- null
- boolean
- number
- string
3. 위 구분기준에 부합하지 않을 경우 에러처리

ex_)string의 " double quotation이 누락된 경우
4. 전위전산자, 후위전산자의 효과적 사용(++i, i++)
for문 forEach, while 만의 방법만을 떠올렸는데 상황에 따라 미리 값을 변경시키거나, 다음 차례에 값을 변경시키는 조건을 걸수 있는게 매우 코드를 읽기 쉽고 단순화 시켜주었다.
> lexer
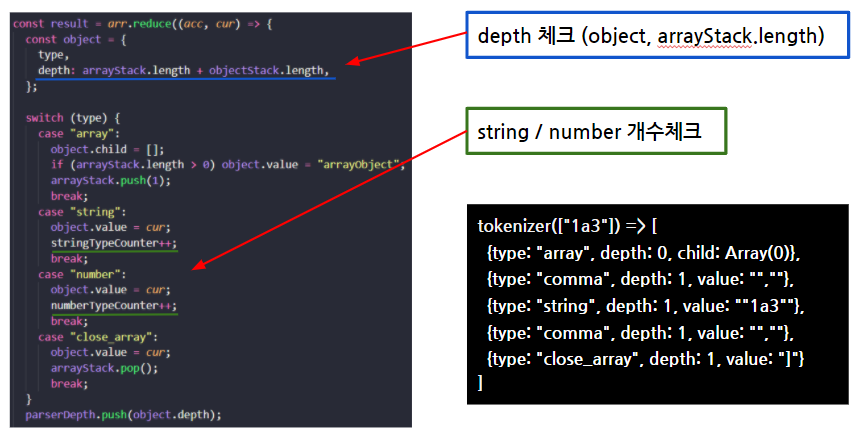
1. 어휘분석(lexical analysis), 잘라낸 토큰마다 의미를 담은 배열을 반환한다.
export const DEFINEKEYWORD = {
"[": "array",
"{": "object",
",": "comma",
":": "colon",
'"': "string",
n: "null_object",
f: "boolean",
t: "boolean",
"]": "close_array",
"}": "close_object",
}; DEFINEKEYWORD에 해당하는 값을 해당 토크의 type으로 정의한다.
위 기준에 부합하지 않는 경우 type을 number로 처리해준다.
2. array, object Stack 관리
배열의 중첩 수준, 객체 중첩 수준 등 json parser된 결과 데이터를 분석할 때 array, object Stack을 사용하였다.
배열, 객체 타입의 토큰을 만났을 때 stack에 임의요소를 추가하여 stack length를 증가시켰고, 닫힌 배열과 객체를 만나면 stack.pop()으로 length를 줄여 depth 관리를 하였다.
const object = {
type: "array",
depth: arrayStack.length
}
>parser
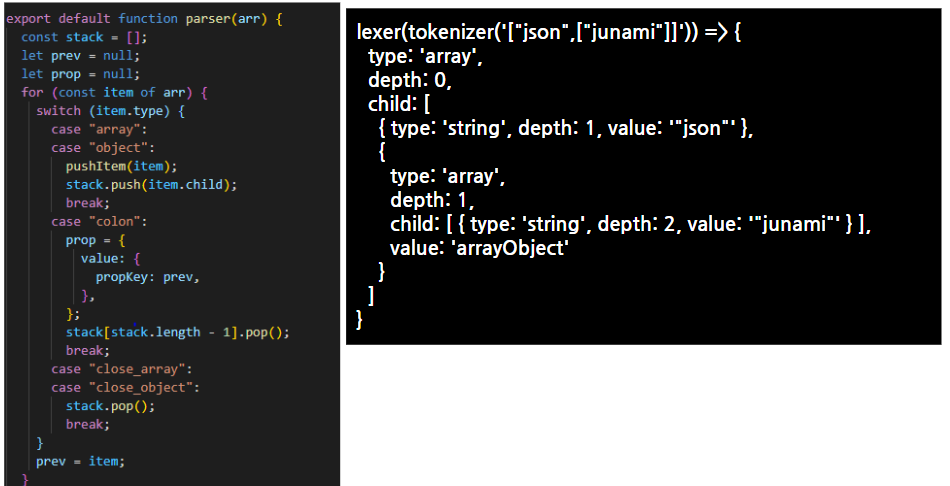
1. 렉서에서 정해준 토큰 의미에 맞춰 구조를 분석해 객체형태의 parserTree를 만든다.
2. 스택방식 구현
[GitHub🐱:parser_stack ver]
- 결과를 반환할 stack 배열에 lexer에서 반환된 item들을 하나씩 stack에 넣어준다.
- array, object 타입일 경우 stack에 비어있는 child 배열( [ ] )을 넣어주어 후에 나올 요소들 (string, null_obj, boolean, string)을 자식 요소에 넣을 수 있도록 한다.
- close_array, object의 경우에는 stack.pop()을 통해 마지막 요소(child 배열)를 뽑아낸다. 그럼 그 다음에 올 item은 더이상 자식요소 배열에 들어가지 않고 형제요소로 stack에 저장될 수 있다. (앞에서 child배열에 저장했던 요소들은 item.child에서 여전히 값을 잘 나타내 주고 있다.)
ex_)
1. array를 만났을 때 stack → [{item.type, item.depth}] [ ]
2. array의 자식요소들을 stack의 마지막에 저장하기
stack.[stack.length-1].push(item.child)
→ [{item.type, item.value, item.child}] [item.child]
3. close_array를 만나면
→ [{item.type, item.value, item.child}] 3. 재귀함수로 구현
[GitHub🐱:parser_recursion ver]
3-1. array, object open: 새로운 child를 갖게되는 array, object를 만나면 재귀호출이 일어난다.
switch (lexer.type) {
case "array":
addChildNode(
reparser(lexers, {
type: "array",
child: [],
value: "arrayObject",
})
);
break;3-2. array, object close: child를 벗어나기 위해 자기 자신을 반환한다.
return parentNode
3-3. 기타 type: child요소로 집어넣는다.
parentNode.child.push(category);회고
이번 미션 코드는 이해를 다 하고나서 보니 정말 어려운게 없다.
그런데도 드라이버 역할을 수행하는 과정은 힘들었다. 페어프로그래밍 특성 상 서로 이해하는 바가 일치해야하는데 이해가 느려서 질문도 참 많이 했고, 매일 페어활동을 마치고 개별적으로 공부하는 시간을 가져야만 했다. 개인 미션을 수행할 때보다 아침에 더 일찍 일어나서 하나라도 더 보탬이 되기 위해 코드를 복습하고 미흡하나마 기능 및 리팩토링을 하려고 노력했다.
<아쉬운점이 있다면!>
사실 이번 미션은 재귀함수와 정규표현식을 공부하고 응용하는게 미션 목표 중의 하나였다고 생각한다. 하지만 재귀함수는 개별적으로 공부하여 미흡하게 구현방식을 이해했으나 정규표현식은 거의 사용하지 않았다. 때문에 주말에 꼭 시간을 내어 정규표현식을 공부하고 이번 미션에서 정규표현식을 적극활용했던 페어팀의 자료를 꼭 읽어보려고 한다.
<배운 것은?>
물론, 위 두가지를 적용하지 못했지만 오히려 더 심플하고, 간결한 코드를 작성했다고 생각한다. 특히 파트너 제이슨의 토크나이져 타입분류를 전산자로 하고, 스택방식으로 parser구현하는 아이디어는 나에겐 평소접해보지 못한 방식이면서도 쉬웠기 때문에 큰 걸 배웠다고 말할 수 있다. 나중에 코딩할 때 적용하기 위해 기억해둬야겠다.
또, 깃 커밋을 남길 때 굉장히 꼼꼼하게 남기는게 인상깊었다. pr보낼 때도 커밋이 좋은 정보가 되고있었다. 지난 주엔 커밋도 타입별로 남기는 것을 배웠다면 이번엔 꼼꼼하게 작성하는 걸 배우게 되었다. 훌륭한 파트너들이랑 페어프로그래밍을 하니 배우는게 많다. 또 지난주보다는 깃을 좀 이해하게 되어 다행이고, 히로쿠 배포를 지난 주 시도하다 포기했는데 이번엔 배포까지 완료할 수 있어서 뿌듯하기도 하다.
<다음 미션때는~>
위에서 말했듯 드라이버하기에 급급해 하지만 다음 주엔 설령 내가 이해하고 따라가지 못하더라도 내 생각을 먼저 정리하고 전달하려고 한다. 파트너랑, 또 다른 조원들이랑도 많은 대화를 하면서 미션을 구현하는 다양한 방법들을 파악하도록 하자. 구현하는게 다가 아닌 것 같다. 내 머리속에 많은 게 남기도록 노력해야 겠다.
제이슨이랑, 또 2조 조원들이랑 1주일을 열심히 코딩하고👩💻,
🌸봄 산책하고 🥓🍜맛있는 것도 먹고 고민도 나누며 좋은 이야기를 나누는 보람찬 한 주였다. 그리고 이번 주를 기점으로 정말 정신 똑띠차리고 하자는 다짐을 한다!!
