논문 제목: Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN은 object detection 모델에서 2-stage detector의 대표적인 R-CNN계열의 시초가 되는 모델이다. R-CNN계열로는 R-CNN, fast R-CNN, faster R-CNN 등이 있다.
R-CNN 개요
논문의 저자들은 VOC 2012 데이터를 기준으로 기존의 방법들보다 mAP(mean average precision)이 30%이상 향상된 더 간단하고 확장 가능한 detection 알고리즘인 R-CNN을 소개한다.
또한 2가지 인사이트에 대해 설명한다.
- localize와 segementation을 위해 bottom-up(상향식)방식의 region proposals에 CNN을 적용했다.
- labeled data가 부족할 때, 보조작업(auxiliary task)를 supervised pre-training과 뒤를 이은 domain-specific fine-tuning을 통해 상당한 성능 향상을 이뤘다.
R-CNN이란 이름은 Regions with CNN features로, 그렇게 불리는 이유는 CNN과 Region proposals를 결합했기 때문이다.
R-CNN은 sliding-window 방식과 CNN 구조를 사용한 그 당시 최근에 제안된 OverFeat 보다 좋은 성능을 보이는 것을 확인했다.
 사진1
사진1
R-CNN은 <사진1> 같이 작동한다.
- 이미지를 입력한다.
- 약 2000개의 bottom-up region proposals를 추출한다.
- CNN을 이용해 각각 region proposal의 특징을 계산한다.
- linear SVMs를 이용해 각각의 label을 분류한다.
위 사진 중간의 "warped region"은 각각의 region proposal의 크기가 다르므로 이를 CNN에 입력으로 넣어주기 위해 크기를 맞춰주는 역할을 한다.
Three Modules for R-CNN
R-CNN은 위의 프로세스를 수행하기 위해 3가지 모듈로 나뉜다.
- Region Proposals: detector가 이용가능한 영역 후보의 집합
- CNN: 각각의 region에 대한 고정된 크기의 feature vector를 추출
- Linear SVMs: 분류를 진행
1. Region Proposals
 사진2
사진2
R-CNN은 category-independent region proposals를 위해 selective search algorithm을 사용해 각 이미지에서 2000장의 후보 영역을 찾는다.
selective search
 사진3. selective search
사진3. selective search
- 색상, 질감, 영역크기 등을 이용해 non-objective segmentation을 수행한다. 이 작업을 통해 좌측 제일 하단 그림과 같이 많은 small segmented areas들을 얻을 수 있다.
- Bottom-up 방식으로 small segemented areas들을 합쳐서 더 큰 segemented areas들을 만든다.
- (2)의 작업을 반복하여 최종적으로 2000개의 region proposal을 생성한다.
2000장의 region proposals를 얻게 되면 warp를 통해 이미지를 227x227로 사이즈를 통합시켜준다.(CNN arichitecture는 고정된 227x227 pixel size의 입력을 요구한다.)
2. CNN
 사진4
사진4
R-CNN에서는 CNN arichitecture를 AlexNet을 이용했다. 이때, classification dataset을 이용해 pre-trained된 AlexNet 구조를 이용한다. 이후 Domain-specific fine-tuning을 통해 CNN을 다시 학습시킨다. 이렇게 학습된 CNN은 region proposals 2000개의 각각의227x227 image를 입력받아 4096-dimensional feature vector를 추출한다.
Domain-specific fine-tuning
 사진5
사진5
2000장의 region proposals와 ground-truth box의 IoU(Intersection of Union)을 비교하여 IoU가 0.5보다 큰 경우 positive samples, 0.5보다 작은 경우 negative samples로 나눈다. 이렇게 sample을 나눴을 때, ground truth만 positive sample로 정의할때 보다 30배 많은 학습데이터를 얻을 수 있다. 많은 데이터를 통해 overfitting을 방지한다. Positive sample는 객체가 포함되어 있는 sample을 의미하고, negative sample은 객체가 포함되지 않은 배경 sample을 의미한다. 이렇게 나눈 후 positive sample 32개 + negative sample 96개 = 128개의 이미지로 이루어진 하나의 미니 배치를 만든다.
이렇게 생성된 배치들을 이용해 fine-tuning을 진행한다. fine-tuning을 하기 위해서 기존의 pre-trained된 AlexNet의 마지막 softmax layer를 수정해서 N+1 way classification을 수행하게 한다. 이때, N은 R-CNN에서 사용하는 dataset의 객체들의 종류의 개수이고, 1을 더해준 이유는 배경인지 판단하기 위해서이다. SGD를 통해 N+1 way classification을 수행하면서 학습된 CNN 구조는 domain-specific fine-tuning을 이룬다.
마지막의 N+1 way classification을 위해 수정한 softmax layer는 R-CNN 모델 사용시 사용하지 않는다. 왜냐하면 softmax layer는 fine-tuning을 위해 사용한 것이고, 원래 R-CNN에서 CNN 구조의 목표는 4096-dimensional feature vector를 추출하는 것이기 때문이다.
IoU(Intersection of Union)
 사진6. IoU = 교집합 영역 넓이 / 합집합 영역 넓이
사진6. IoU = 교집합 영역 넓이 / 합집합 영역 넓이
 사진7. Example of IoU
사진7. Example of IoU
IoU는 위의 정의대로 구할 수 있고, 위의 예시처럼 겹치는 영역이 클수록 높은 값을 갖는다.
3. Linear SVMs
 사진8
사진8
 사진9
사진9
2000장의 region proposals에서 fine-tuning때와는 다르게 ground truth box만을 positive sample, IoU 값이 0.3보다 작은 것은 negative sample로 지정한다. 이때, IoU값이 0.3보다 큰 경우 무시한다. 이때 0.3은 gird search를 통해 찾은 값이다. 이후는 fine-tuning과 마찬가지로 positive sample 32개 + negative sample 96개 = 128개의 미니배치를 구성한 후 fine-tuning된 AlexNet에 입력하여 4096 dimensional feature vector를 추출한다. 추출된 벡터를 이용해 linear SVMs를 학습한다. SVM은 2진 분류를 수행하므로 분류하려는 객체의 종류만큼 SVM이 필요하다. 학습이 한 차례 끝난 후, hard negative mining 기법을 적용하여 재학습을 수행한다.
R-CNN에서는 단순히 N-way softmax layer를 통해 분류를 진행하지 않고, SVMs를 이용해 분류를 한다. 이는 SVM을 사용했을 때 성능이 더 좋기 때문이다. 성능 차이의 이유를 논문의 저자들은 positive sample을 정의할 때 SVM을 학습시킬 때 더 엄밀하게 정의한다는 점과 SVM이 hard negative를 이용해 학습하기 때문이라고 서술했다.
linear SVM에서는 output으로 class와 confidence score를 반환한다.
hard negative mining
 사진10. hard negative mining
사진10. hard negative mining
이미지에서 사람을 탐지하는 경우 사람은 positive sample이 되고, 그 외의 배경은 negative sample이 된다. 이때, 모델이 bounding box를 배경이라고 예측하고 실제로 배경인 경우 true negative sample라고 한다. 반면에 모델이 사람이라고 예측했지만, 실제로 배경인 경우 false positive sample에 해당한다.
객체 탐지 시, positive sample보다 negative sample이 더 많은 클래스 불균형 때문에 모델은 주로 false positive 오류를 주로 범하게 된다. 이러한 문제를 해결하기 위해 처음 linear SVMs를 학습시킬 때의 false positive sample들을 epoch마다 학습 데이터에 추가하여 학습을 진행한다. 이를 통해 모델이 강건해지고, false positive 오류가 줄어든다.
3.1 Bounding Box Regressor
 사진11
사진11
selective search 알고리즘을 통해 얻은 객체의 위치는 부정확할 수 있다. 이런 문제를 해결하기 위해 객체의 위치를 조절해주는 Bounding box regressor가 있다.
N개의 training pair인 에 대해 = (,,,)는 해당 region에 대한 추정값으로 각각은 region 중심의 x,y좌표와 width와 height를 나타내고, 이에 대응되게 = (,,,)은 해당 region에 대한 ground truth이다.
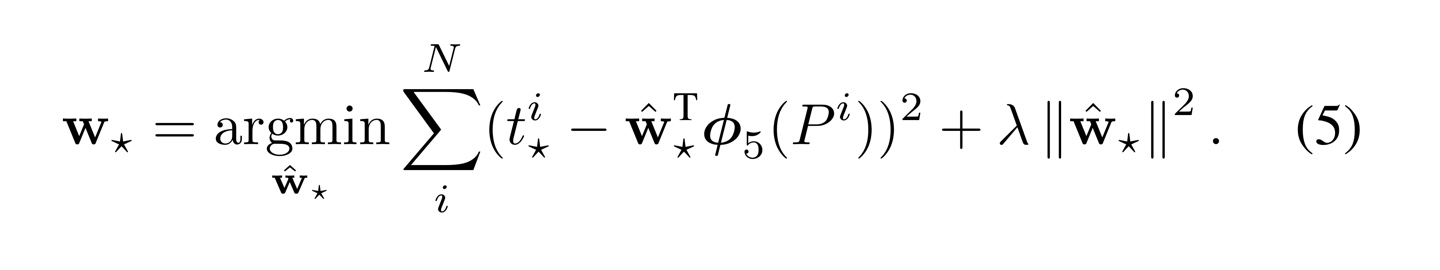
위의 식을 최적의 를 찾고 싶다. (, 별 표기가 어려워 a로 대치)
: 학습되는 가중치
(): 에 해당하는 feature vector. 여기서 feature vector는 fine-tuning된 CNN의 output
: ridge regression을 위한 상수(논문에서는 1000 사용)
는 밑을 참고
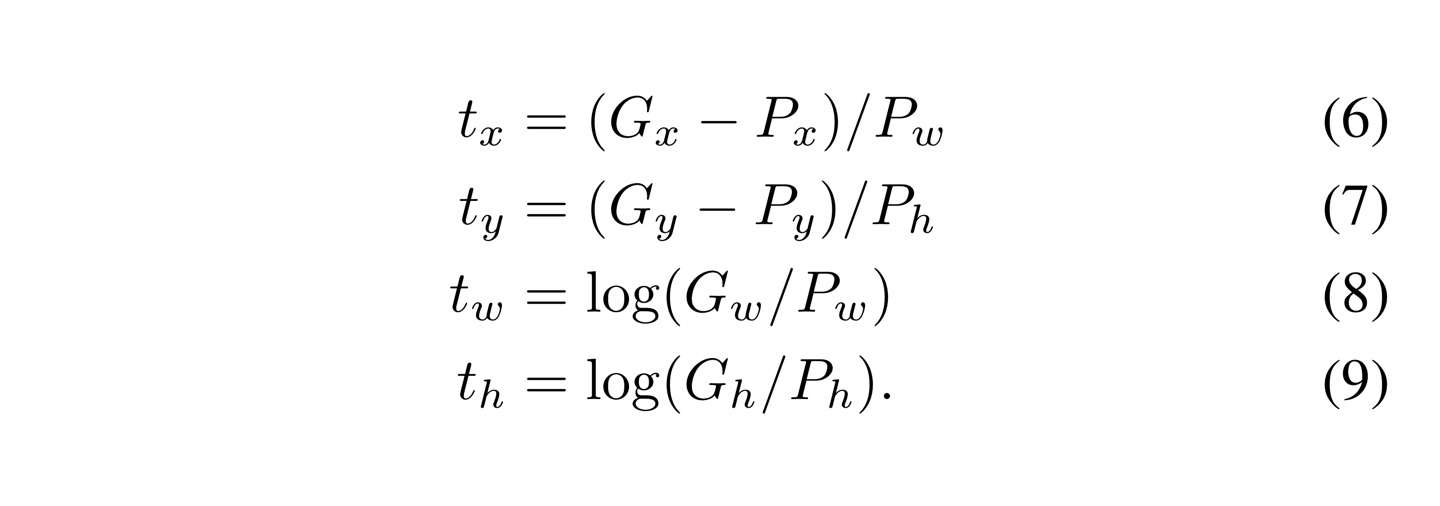
위의 식을 통해 찾은 를 이용해 라는 transformation 함수를 정의할 수 있다.
즉, 다음과 같이 정의할 수 있다. () = ()
이를 통해서 ground truth 의 추정값인 를 다음과 같이 추정할 수 있다.

위와 같이 추정하는 이유는 그림 10을 참조
위와 같은 training pair를 정의할 때, P는 ground truth와 IoU 값이 0.6이상인 경우만 사용한다. 왜냐하면 겹치는 영역이 많이 작을 경우, 학습의 어려움이 존재하기 때문이다.
Non maximum Supression
R-CNN을 통해 얻게 되는 2000개의 bounding box를 전부 다 표시할 경우우 하나의 객체에 대해 지나치게 많은 bounding box가 겹칠 수 있다. 따라서 가장 적합한 bounding box를 선택하는 Non maximum supression 알고리즘을 적용한다.
 사진12. non maximum supression
사진12. non maximum supression
non maximum supression 알고리즘은 다음과 같다.
- bounding box별로 지정한 confidence scroe threshold 이하의 box를 제거한다.
- 남은 bounding box를 confidence score에 따라 내림차순으로 정렬한다. 그 다음 confidence score가 높은 순의 bounding box부터 다른 box와의 IoU값을 조사하여 IoU threshold 이상인 box를 모두 제거한다.
- 2의 과정을 반복하여 남아있는 box만 선택한다.
단점
- 이미지 한 장당 2000개의 region proposal을 추출하므로 학습 및 추론의 속도가 느리다.
- 3가지 모델을 사용하다보니 구조와 학습 과정이 복잡하다. 또한 end-to-end 학습을 수행할 수 없다.
References
R-CNN 논문(Rich feature hierarchies for accurate object detection and semantic segmentation)
https://herbwood.tistory.com/5
https://ganghee-lee.tistory.com/35
https://m.blog.naver.com/PostView.nhn?blogId=sogangori&logNo=221073537958&proxyReferer=https:%2F%2Fwww.google.com%2F
R-CNN youtube 강의 영상(by Cogneethi)
코드참조

내용이 정말 잘 정리되어 있어서 도움이 많이 되었습니다. 감사합니다!
혹시 포스트에 사용된 사진들 중 사진5와 사진9는 직접 만드신건가요? 아니라면 혹시 출처를 알 수 있을까요~?