논문 제목: R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN 개요
기존의 Fast/Faster R-CNN과 같은 2-stage detector들은 RoI pooling layer를 기준으로 두 부분으로 나뉜다. 앞 부분은 RoI와 독립적으로 계산되는 fully conovlutional subnetwork와 뒷 부분에 RoI별로 계산되는 subnetwork가 존재한다. 이러한 구조를 따르는 이유는 앞부분의 feature extractor가 image classification을 위한 구조로 translation invariance를 학습하는 반면 뒷부분은 object detection을 위한 translation variance를 학습하는 tranlsation dilemma를 해결하기 위해서 이다. 이때, RoI별 subnetwork 연산 때문에 모델 전체의 계산 효율성이 저하된다.
이러한 문제를 해결하기 위해 논문의 저자들은 fully convolutional network를 이용해 연산되는 position-sensitive score maps를 제안한다. 그 다음 position-sensitive RoI pooling layer를 적용한다. 해당 layer 다음의 연산에는 가중치를 사용하지 않는다. (즉, no conv/fc) 따라서 RoI wise 연산의 부담이 기존의 모델 구조들에 비해 줄어들게 된다.
제안된 모델은 Faster R-CNN + RestNet-101과 유사한 정확도(mAP)를 보여주며 2.5~20배 정도 빠른 속도를 보여줬다. 또한 ResNet과 같이 fully convolutional image level classifiers를 효과적으로 fully convolutional object detector로 변환하는 방법을 보여줬다.
Approach
overview
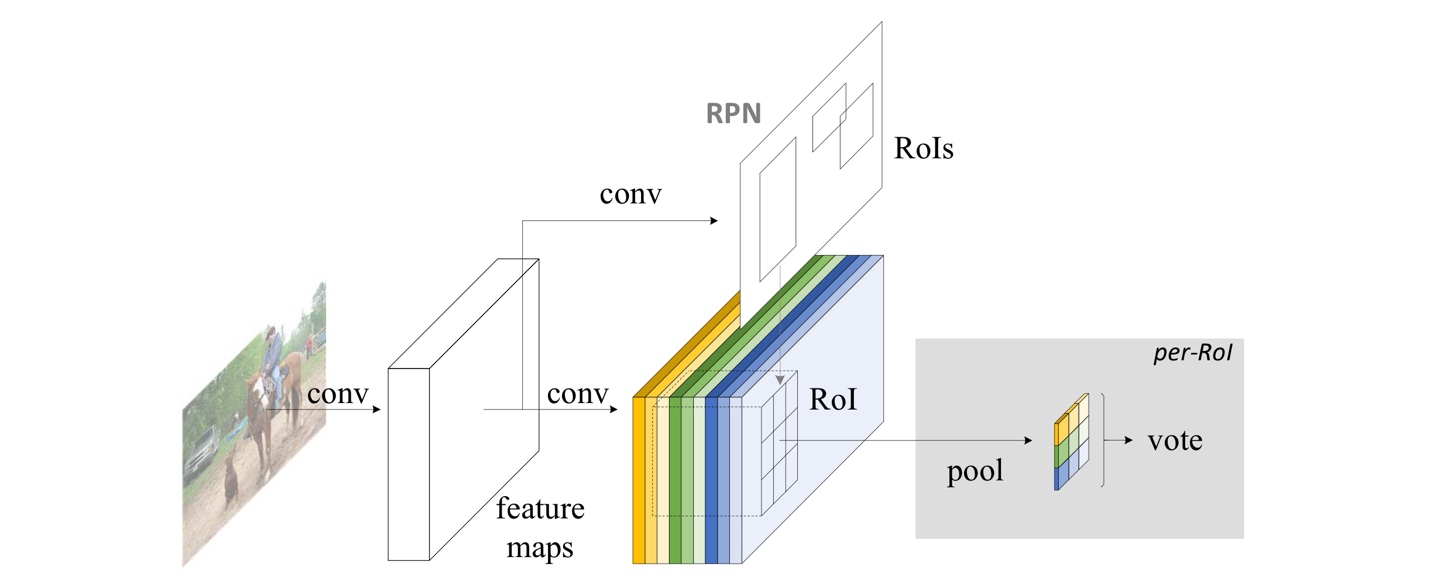
 사진 1. R-FCN architecture
사진 1. R-FCN architecture
 사진 2. Faster R-CNN architecture
사진 2. Faster R-CNN architecture
기존의 R-CNN 계열의 모델과 같이 2-stage detector로 (i)region proposal (ii)region classification 으로 구성된다. Faster R-CNN의 RPN을 이용해 후보 구역을 추출한다. 이러한 RoI들은 제안된 R-FCN 모델을 통해 해당 구역의 category를 분류한다. R-FCN의 학습가능한(learnable parameter가 존재하는) layer들은 모두 convolutional이고, 전체 이미지에 대해 연산을 수행한다.
마지막 convolution 연산을 통해 각각의 category별로 개의 position-sensitive score map들을 얻는다. 따라서 데이터셋이 C개의 category로 이루어진 경우 -channel output을 얻는다. (+1: background)
 사진 3. position-sensitive score maps
사진 3. position-sensitive score maps
score map들은 상대적인 위치를 나타내는 x 격자에 대응된다. 예를 들어 k=3인 경우, 9 score map은 하나의 객체 category의 [top-left, top-center, top-right,...,bottom-right]를 encode한다.
R-FCN은 position-sensitive RoI pooling layer로 끝난다. 이 layer는 마지막 convolution 연산의 output(position-sensitive score maps)를 합산하고 각각 RoI의 점수를 생성한다.
Backbone architecture
R-FCN에서 backbone network로 ResNet-101을 사용한다. 이때, ImageNet dataset으로 pre-train시키고, 마지막의 global average pooling과 fc층을 제거해서 사용한다. 이후 차원축소를 위한 1x1 convolution 연산을 추가한다. 마지막으로 -channel convolution 연산을 통해 position-sensitive score maps를 구한다.
Position-sensitive score maps & Position-sensitive RoI pooling
각각의 RoI의 위치 정보를 명시적으로 encode하기 위해서 RoI들을 x bins의 격자로 나눈다. 즉 다음 그림4와 같이 나눈다.
 사진 4. regular grid
사진 4. regular grid
-th bin의 pixel 는 , 의 범위에 속한다.
사진 5. position-sensitive RoI pooling
position-sensitive RoI pooling은 다음과 같이 정의된다.
: c번째 category의 -th bin의 풀링된 결과
: score map들 중 하나의 score map
: RoI의 top-left corner
: number of pixels in the bin
: all learnable parameters of the network
position-sensitive RoI pooling의 수식을 보면, 그림 5에 나온것 처럼 score map의 특정 색깔 부분은 pooling 이후 x grid의 한 부분과 대응된다. 즉, 대응되는 색깔에 대해 특정 영역(-th bin)에 대해서만 연산을 수행한다.
이러한 결과로 xx(C+1)의 feature map을 얻게 된다. 이 때 연산은 영역에 속한 픽셀들을 더하고 이를 픽셀의 개수(n)로 나누므로 average pooling을 수행하는 것을 알 수 있다.
cf) 논문의 저자들은 average pooling이 아닌 max pooling을 수행해도 상관없다고 밝혔다.
위의 사진5를 확인하면 xx(C+1) feature map 이 후 vote(averaging)를 통해 (C+1)-dimensional vector를 얻게 된다.
(C+1)-dimensional vector를 softmax 함수를 통해 확률 값으로 바꾼 뒤 cross-entropy loss를 이용해 모델 학습에 이용한다.
Bounding box regression은 위의 classification과 유사한 방법으로 이뤄지며 classification의 (C+1)을 4( x,y,w,h 이므로 4)로 바꾼 새로운 branch를 통해 수행할 수 있으며 Fast R-CNN의 bounding box regression과 같은 loss function을 이용해 모델을 학습한다.
(참고: Fast R-CNN post)
position-sensitive score maps와 position-sensitive RoI pooling을 통해 RoI layer 이후 학습가능한 parameter가 존재하지 않아 RoI별 연산에서 거의 연산이 cost-free가 된다. 따라서 학습과 추론시 둘 다 속도가 향상된다.
Training
: RoI's ground-truth label
: cross-entropy loss
: bounding box regression loss in Fast R-CNN
R-FCN의 손실함수는 위의 수식과 같다. 논문에서 을 사용했다. Poistive sample은 ground-truth와 IoU가 0.5이상인 경우로 정의했고, 이외는 negative sample로 정의했다.
RoI별 연산이 무시해도 좋을 정도로 연산량이 적기 때문에 cost-free한 online hard example mining(OHEM)을 적용하기 쉽다. 방법은 다음과 같다.
- N개의 proposal에 대해 forward를 통해 loss를 모두 계산한다.
- N개의 loss를 정렬한 후 상위 B개의 RoI를 선택한다.
- 선택된 B개의 RoI들의 loss로 backpropagation을 수행한다.
RPN과 R-FCN이 feature들을 공유하기 위해 Faster R-CNN의 4-step alternating training 방법을 적용했다.
(참고: Faster R-CNN post)
A trous and stride
R-FCN 모델에서 backbone network로 사용된 ResNet-101 부분에서 conv4 이후 conv5의 stride를 2에서 1로 변경해서 score map의 resolution을 증가시켜서 성능을 향상할 수 있었다. 또한 conv5에서 stride=1인 경우의 보상으로 atrous convolution 연산을 적용했을 때, 성능을 향상시킬 수 있었다.
 사진 6. atrous trick
사진 6. atrous trick
Visualization
 사진 7. visualization score map(true)
사진 7. visualization score map(true)
 사진 8. visualization score map(false)
사진 8. visualization score map(false)
사진 7,8은 score map을 시각화한 것이다. 위의 사진들을 통해 candidate box가 실재 object와 정확하게 겹치면 bin들이 강하게 활성화 되는 것을 확인할 수 있다. 반대의 경우 활성화되지 않는 것을 확인할 수 있다.
Experiments
 사진 9. experiment on PASCAL VOC 2007
사진 9. experiment on PASCAL VOC 2007
 사진 10. experiment on MS COCO
사진 10. experiment on MS COCO
Conclusion
논문의 저자들은 간단하지만 정확하고 효율적인 object detection 모델인 R-FCN을 제안했다. R-FCN은 Faster R-CNN과 경쟁할만한 정확도를 이루면서 train과 test에서 훨씬 빠른 속도를 보여줬다.
References
R-FCN 논문: R-FCN: Object Detection via Region-based Fully Convolutional Networks
https://herbwood.tistory.com/16
https://hellopotatoworld.tistory.com/1
