CNN(Convolution Neural Network)를 사용하는 이유
컨브넷(convnet)이라고도 불리는 합성곱 신경망(convolutional neural network)는 컴퓨터 비전 에플리케이션에 사용된다.
그렇다면 왜 컴퓨터비전에서는 MLP(Multi layer perceptron)이 아닌 CNN을 사용할까? 그 이유는 다음과 같다.

x 라는 표시의 이미지를 픽셀 단위로 보았을 때 위는 사람이 인식하기에 동일한 x 이미지이다. 이를 만약 MLP를 사용해 학습하게 되면 MLP에서는 이미지 픽셀1개가 1개의 노드 이므로 위처럼 이미지가 shift하게 되면 노드의 값들이 많이 바뀌게 되어 많은 weight 값들이 무력화 된다.
따라서 CNN은 feature extraction을 통해 이미지를 학습하게 된다. CNN은 Filter값을 사용자가 만들거나 선택할 필요없이 Deep Learning Network 구성을 통해 이미지 분류 등의 목적에 부합하는 최적의 filter값을 학습을 통해 스스로 생성한다.

CNN의 전체적인 개요
CNN은 기본적으로 several layers of convolutions이 결과값에 Relu, Tanh 같은 Nonlinear function을 적용한 것들이다. 먼저 input image에 convolution을 적용하여 output을 꺼낸다. 해당 output은 input image의 local connection으로 연결이 되어 있으며, 각각의 layers들은 각기 다른 filters를 적용한다.
- CNN 과정 이미지:
위의 이미지에서 첫번째 Conv layer 에서는 edge같은 제일 작은 차원의 특성을 인식할 것이다. 그뒤 점점 뒤의 Conv layer로 갈수록 좀 더 높은 차원 특징(예를 들면 얼굴, 핸드폰, 자동차)을 인식하게 된다.
마지막의 fully connected 는 일반적인 Multi Layer Perceptron이다.
Convolution: Local feature들을 찾는 방법
- 이미지의 좌상단 부터 한칸씩 이동하면서(stride가 1일 경우) convolution연산은 순차적으로 진행한다.
- 개별 convolution 연산은 filter 에 매핑되는 원본 이미지 배열과 filter 배열을 element-wise하게 곱셈을 적용한뒤 합을 구한다.

Stride
- stride는 입력 데이터(원본 image또는 feature map)에 Conv Filter를 적용시킬 때 Sliding Window가 이동하는 가격을 의미한다.
- stride를 키우면 공간적인 feature 특성을 손실할 가능성이 높아지지만. 이것이 중요 faeature들의 손실을 반드시 의미하는 것은 아니다. 오히려 불필요한 특성을 제거하는 효과를 자겨올 수 있으며. Convolution의 연산 속도도 향상시킨다.

Zero-Padding
- Filter를 적용해서 Convolution 연산 수행 시 출력 feature map이 입력 feature map대비 작아지는 것을 막기 위하여 배열의 둘레를 확장하고 0으로 채운것
- 위의 효과와 더불어 모서리 주변의 Conv연산 횟수가 증가하여 모서리 주변 feature들의 특징을 보다 강화하는 장점이 있다.
- Zero-padding을 적용하는것을 Wide Convolution, 안하는것을 Narrow Convolution 이라고 한다.

필터(Filter)와 커널(Kernel)
- 필터는 여러개의 kernel로 구성되어 있으며 개별 filter는 필터 내에서 서로 다른 값을 가질 수 있다.
- keras에서 컨볼루션 api인
Conv2D(filter=10, kernel_size=3)를 살펴보면 3x3 사이즈의 kernel로 이루어진 10개의 filter를 적용하겠다는 뜻이다. - convolution layer층에서 4개의 feature map이 나왔다는 것은 4개의 filter를 적용했다는 것이다.
- Kernel의 크기가 크면 클수록 Feature Map 에서 더 많은 Feature 정보를 가져 올 수 있다. 하지만 큰 사이의 Kernel로 Conv 연산을 할 경우 더많은 연산량과 파라미터를 필요로해 3x3 kernel를 많이 쓴다.
Feature Map
- filter로 Conv연산을 실행한 2차원 행렬
- k개의 filter를 사용한다면 k개의 feature map이 생성된다.

아래의 사진을 통해 하나의 컬러 이미지에서 Feature Map을 어떻게 생성하는지 알아보도록하자
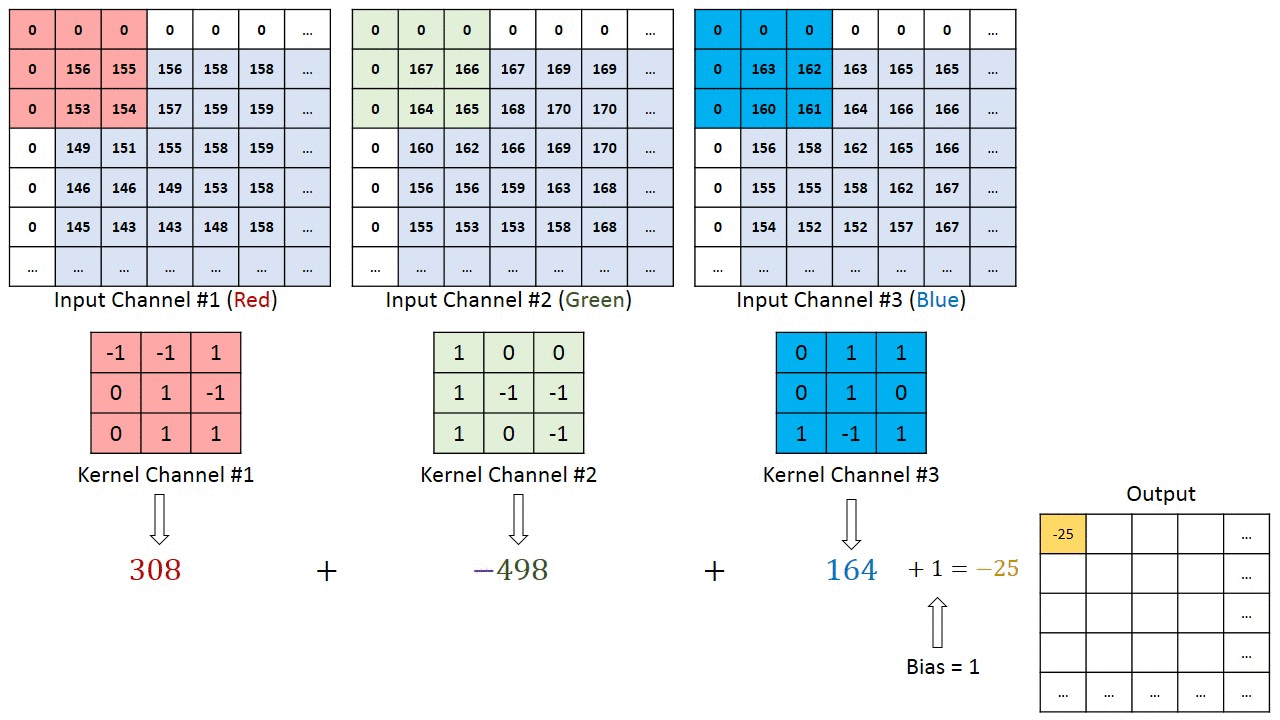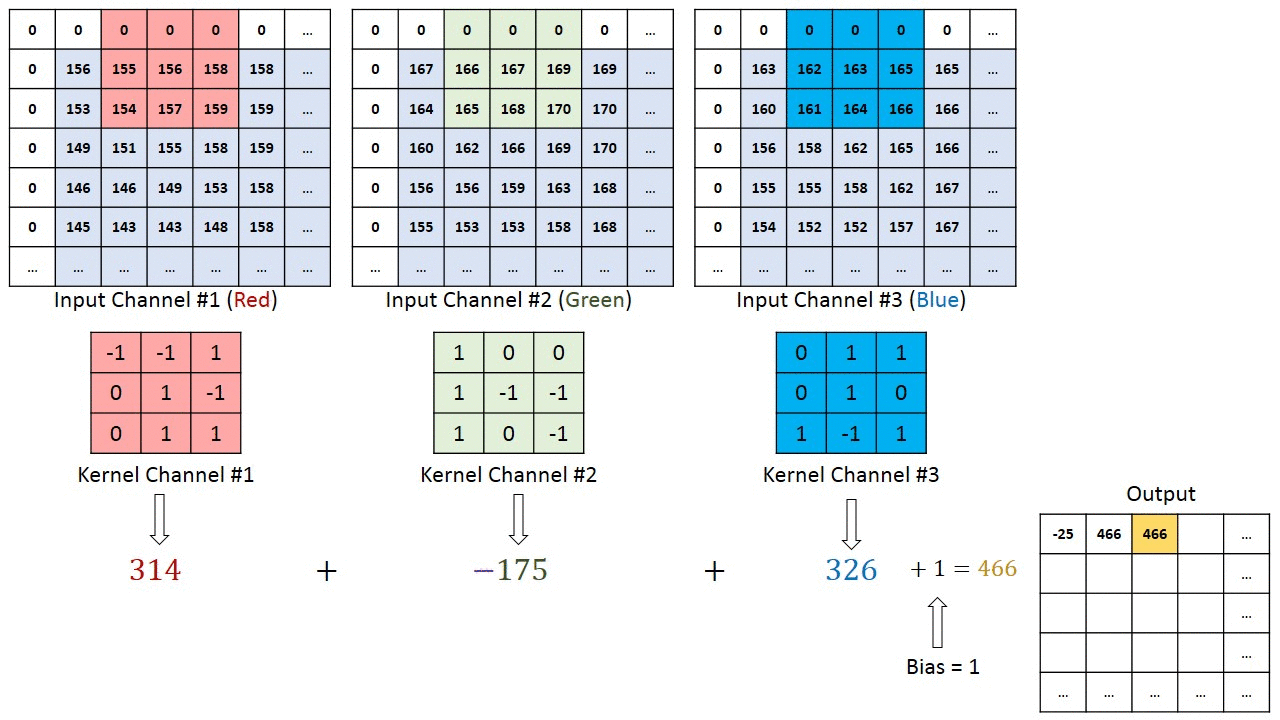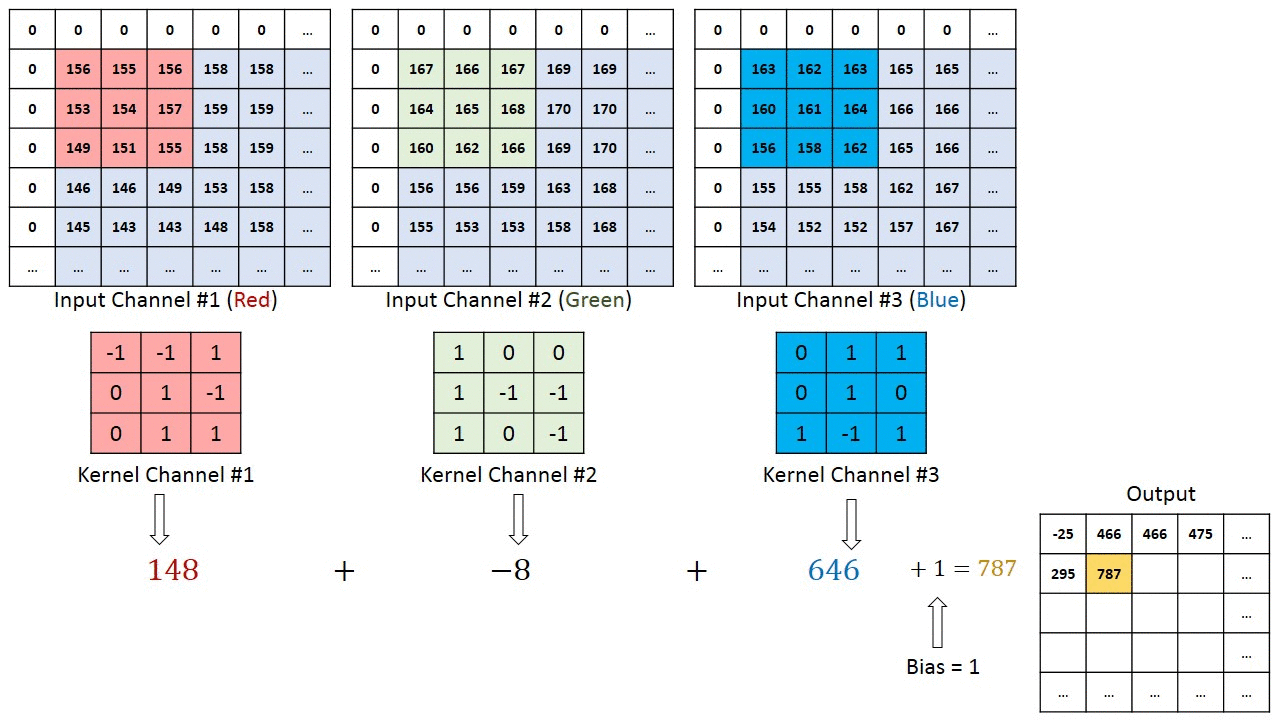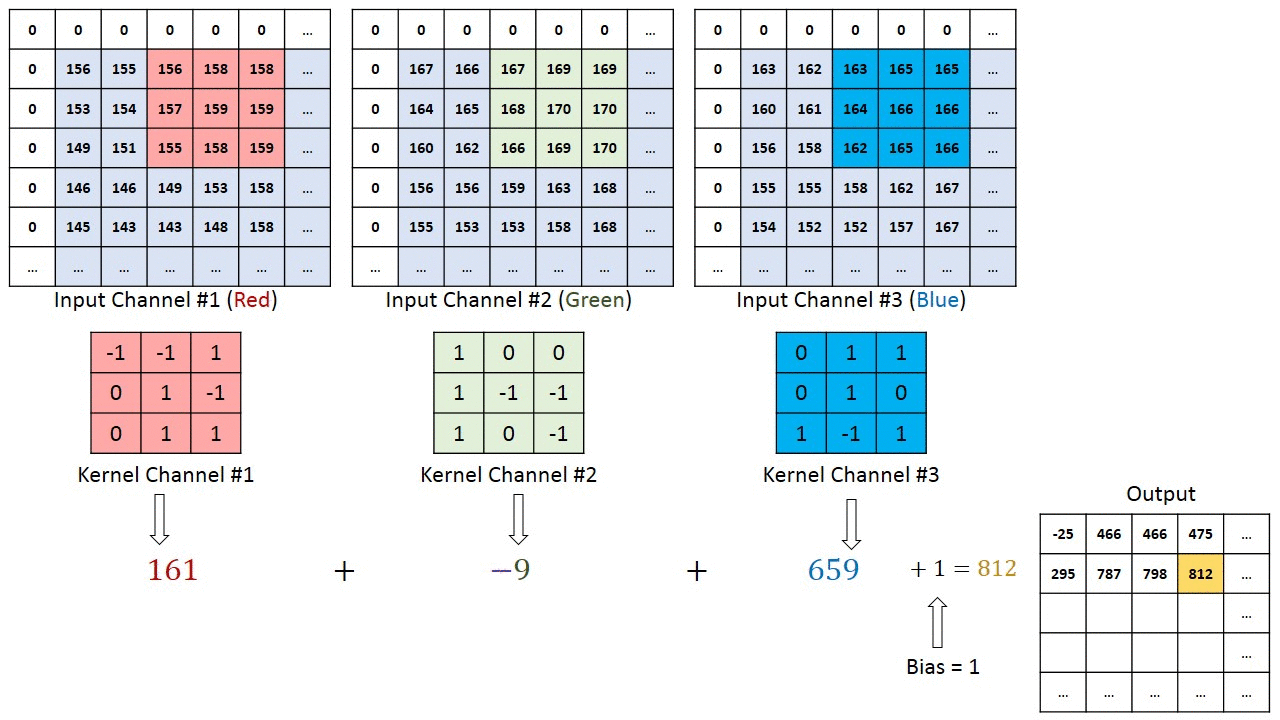
컬러이미지는 총 R,G,B 3개의 channel 로 이루어져있다. 따라서 하나의 필터는 channel의 수는 input의 channel수와 같다.
필터를 통한 컨볼루션 연산은 CNN에 있어 핵심이기 때문에 여러개의 필터를 사용했을 때 생성되는 Feature Map 또한 알아보도록 하겠다.
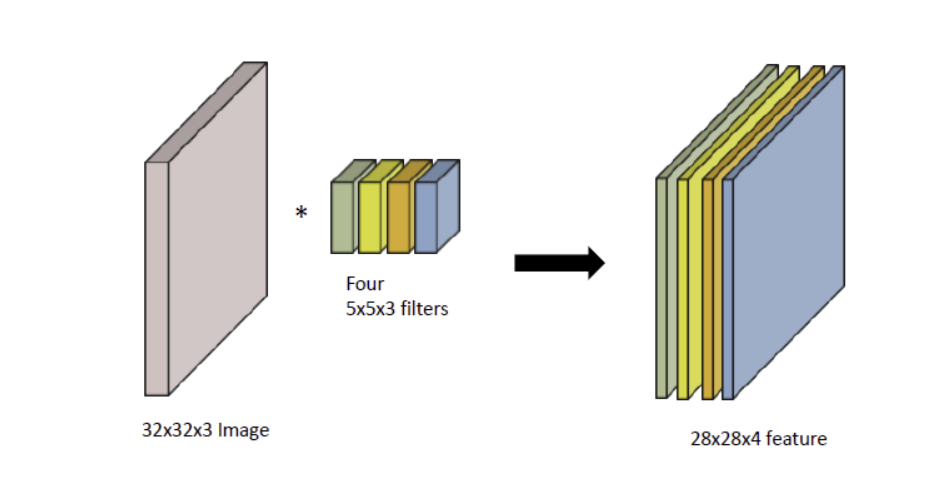
위 이미지에서의 핵심은 다음과 같다
- 입력 데이터의 채널수와 상관없이 필터 별로 1개의 Feature Map이 만들어진다 위의 자료를 보면 총 4개의 필터를 사용해 4개의 Feature Map이 생성된것을 볼 수 있다.
- 입력 이미지의 channel과 한개의 filter의 channel은 같아야한다
Convolution 연산을 하기 위한 parameter수 구하기
cnn을 학습하는데에는 많은 parameter가 필요해 많은 시간이 소요된다, 현재 cnn에 우수한 모델들을 parameter수를 줄이면서 성능을 높이는 방향으로 발전되고 있다. 따라서 cnn 아키텍쳐의 parameter의 수를 계산할 수 있어야한다.
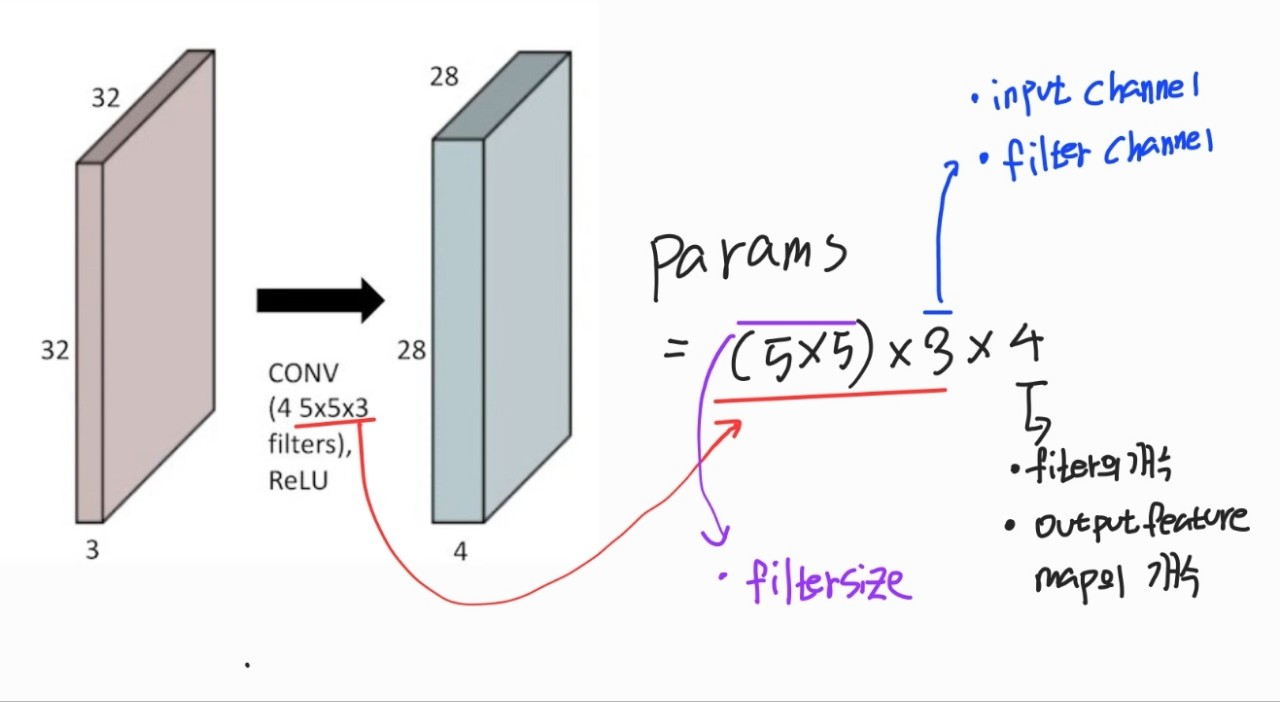
parameter를 구하는 방법
parmeter수 = Kernel Size x Kernel Size x input channel x Output Channel
Pooling
- Conv연산이 적용된 feature map의 일정 영역 별로 하나의 값을 추출하여 feature map의 사이즈를 줄이는것(sub sampling)
- 일반적으로 Pooling 크기와 stride를 동일하게 부여하여 모든 값이 한번에 처리 될 수 있도록 한다.
- 비슷한 feature 들이 서로 다른 이미지에서 위치가 달라지면서 다르게 해석되는 현상을 중화시켜준다.
- Max pooling(지정된 블록의 최대값을 대표값으로):

- Averaging Pooling(블록내 원소들의 평균값을 대표값으로):

Pooling을 하게되면 Feature Map의 크기를 줄여 위치의 변화에 따른 feature 값의 영향도를 줄여서 오버피팅 감소등의 장점을 얻을 수도 있다. 하지만 최근에는 Pooling의 특징상 특정 위치의 feature값이 손실 되는 이슈 등으로 사용하지 않는 경향을 보이고 있으며 Stride로 Feature Map 크기를 줄이는 것이 Pooling 보다 더 나은 성능을 보인다는 연구 결과가 있다.
Fully Connected Layer
Convolutional Layer를 통하여 Feature extraction이 끝나면 해당 Feature Map들을 Flatten 한후 Fully Connected Layer를 통해 학습하게 된다

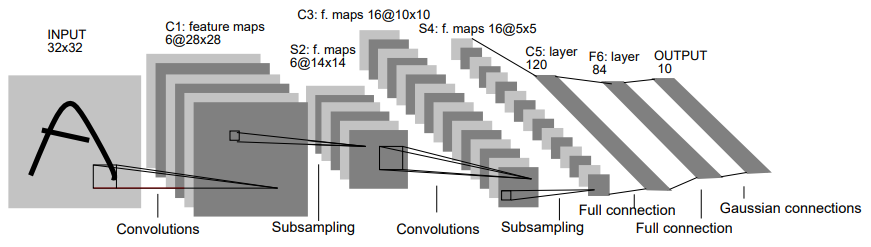
위는 구글에서 개발한 cnn 초창기 모델인 LeNet-5이다.
첫번째 Full connection 부분을 보면 총 (5,5)사이즈의 16개의 Feature Map을 Flatten해서 개의 input node와 120개의 output node를 가지는것을 확인할 수 있다.
LeNet-5를 통해 CNN학습 확인하기
-
: 6개의 feature map이 있는것으로 총 6개의 filter를 사용한것을 알 수 있다. 이때 한개의 filter의 channel수는 input이미지의 channel수인 3이다.
-
: 6개의 feature map이 있는것으로 총 6개의 filter를 사용한것을 알 수 있다. 이때 한개의 filter의 channel수는 input으로 받은 의 channel수인 6이다.
-
: 16개의 feature map이 있는것으로 총 16개의 filter를 사용한것을 알 수 있다. 이때 한개의 filter의 channel 수는 input으로 받은 의 channel수인 6이다.
-
: 16개의 feature map이 있는것으로 총 16개의 filter를 사용한것을 알 수 있다. 이때 한개의 filter의 channel 수는 input으로 받은 의 channel수인 16이다.
-
: 120개의 노드를 가지는 fully connected layer
-
: 84개의 노드를 가지는 fully connected layer
-
output: output노드가 10개인것은 이 모델이 10개의 분류를 위한 모델이였다는것을 알 수 있다.
keras 로 간단한 CNN 알아보기
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D
from tensorflow.keras.models import Modelinput_tensor = Input(shape=(28, 28, 3), name="input")
x = Conv2D(filters=32, kernel_size=3, strides=1, padding="same", activation="relu", name="Conv1")(input_tensor)
x = Conv2D(filters=64, kernel_size=3, activation="relu", name="Conv2")(x)
x = MaxPooling2D(2, name="Max_Pooling")(x)
model = Model(inputs=input_tensor, outputs=x)
model.summary()Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, 28, 28, 3)] 0
Conv1 (Conv2D) (None, 28, 28, 32) 896
Conv2 (Conv2D) (None, 26, 26, 64) 18496
Max_Pooling (MaxPooling2D) (None, 13, 13, 64) 0
=================================================================
Total params: 19,392
Trainable params: 19,392
Non-trainable params: 0
_________________________________________________________________None은 배치 사이즈이므로 None은 제외하고 model의 summary를 보자
- input:
28x28 사이즈의 3channel(r,g,b) 이미지가 입력으로 들어간다. - Conv1:
filters=32로 지정하고 padding="same"으로 지정하였으므로 똑같은 28x28 크기의 32개의 feature map이 생성 - Conv2:
filters=64로 지정하고 padding은 지정하지 않아서 26x26 크기의 64개의 feature map이 생성 - Max_Pooling:
pooling size를 2x2로 지정
CNN은 최적의 Feature추출을 위한 최적의 weight값을 계산하는 것인데 이 최적의 weight는 바로 필터의 weight값이다.
위에 model.sumarry()의 결과에서 param이 weight의 개수이다 Conv1, Conv2의 weight를 자세히 살펴보면 다음과 같다.
Conv1을 보게되면 (3x3)커널의 3채널(input이 3개의 채널로 이루어 져있으므로)로 이루어져있는 32개의 filter 이므로 총 param의 개수는
Conv2를 보게되면 Conv1의 output으로 생성된 Feature Map은 28x28x32 의 형태로 총 32개의 채널을 가지고 있어 Conv2에서의 1개의 filter는 3x3x32의 형태를 가지게 되고 이로 인해 총 param의 개수는
출처:
- http://incredible.ai/artificial-intelligence/2016/06/12/Convolutional-Neural-Networks-Part1/
- https://medium.com/@draj0718/zero-padding-in-convolutional-neural-networks-bf1410438e99
- http://incredible.ai/artificial-intelligence/2016/06/12/Convolutional-Neural-Networks-Part1/'
- http://taewan.kim/post/cnn/
- https://ctkim.tistory.com/95
- https://sonsnotation.blogspot.com/2020/11/7-convolutional-neural-networkcnn.html
