machine learning
1.[Linear Regression] 단순 선형회귀 with python

회귀 분석은 지도학습(supervised learning)중 하나인데 지도학습이란 y=f(x)에 대하여 입력변수(x)와 출력변수(y)의 관계에 대해 모델링을 하는것이다. 지도학습은 회귀(regression) 와 분류(classification)으로 나뉘게 된다.회귀:
2.[Decision Tree] with Scikit-Learning

분류, 회귀, 다중출력 작업에 활용가능한 머신러닝 알고리즘강력한 머신러닝 알고리즘 중 하나인 랜덤포레스트의 기본 구성 요소데이터 전처리가 거의 필요하지 않다.매우 직관적이고 결정 방식을 이해하기 쉬운 화이트 박스(white box) 모델이다.사이킷런은 이진트리만 만드는
3.[Decision Tree] 이론

계층적 구조로 인해 중간에 에러가 발생하면 다음 단계로 에러가 계속 전파학습 데이터의 미세한 변동에도 최종 결과에 크게 영향적은 개수의 노이즈에도 크게 영향나무의 최종노드 개수를 늘리면 과적합 위험
4.교차 검증(Cross Validation)

머신러닝 모델을 구축할때 사용할 label 데이터가 있고 이 데이터를 test와 train data로 나누어서 사용한다면 고정된 test set을 가지고 모델의 성능을 확인하고 파라미터를 수정하는 과정을 반복하면 결국 고정된 test data에 overfitting이
5.[KNN: K-Nearest Neighbor] 이론

별도의 모델 생성 없이 인접 데이터를 분류/예측에 사용하는 기법, 새로운 데이터가 들어왔을때 해당 데이터에 근접 한 K개의 데이터를 통해 예측한다.Instance-based Learning: 각각의 관측치(instance)만을 이용하여 새로운 데이터에 대한 예측을 진행
6.PCA (Principle Component Analysis), 주성분 분석
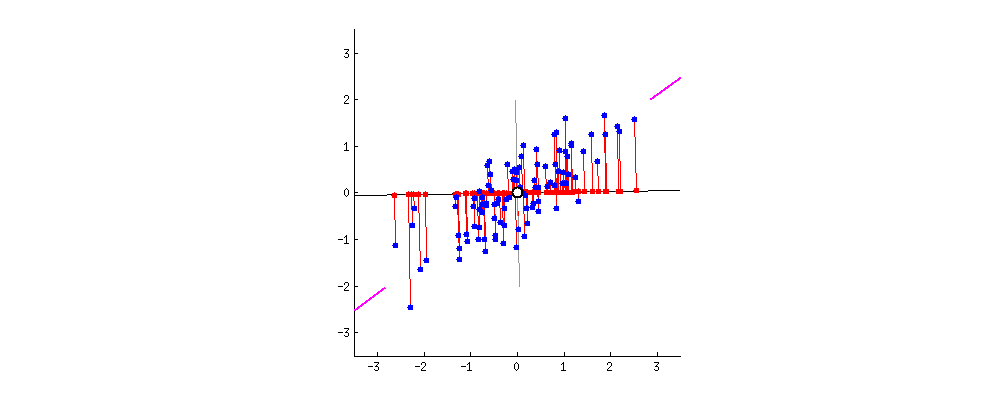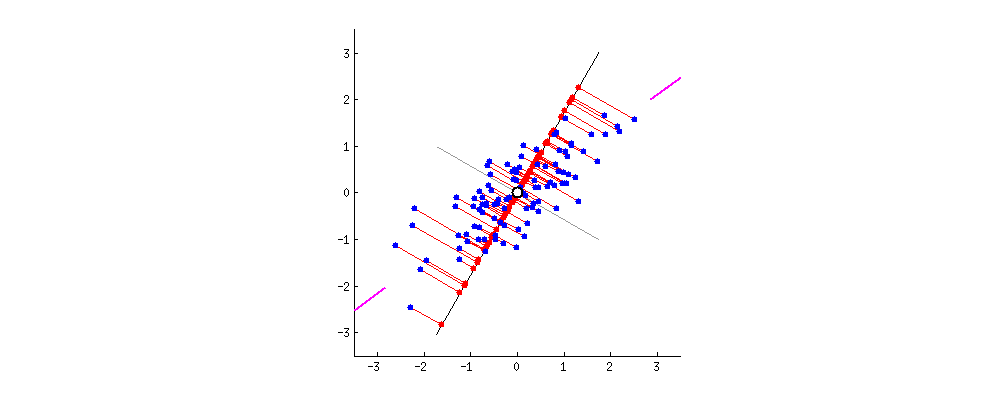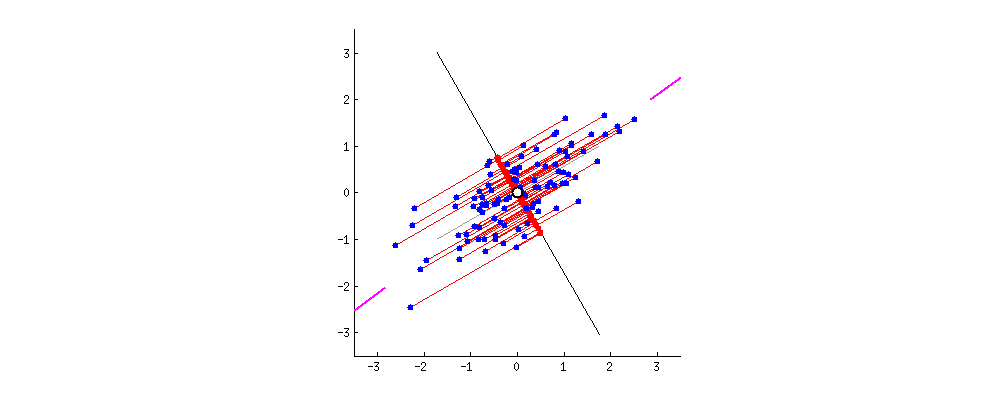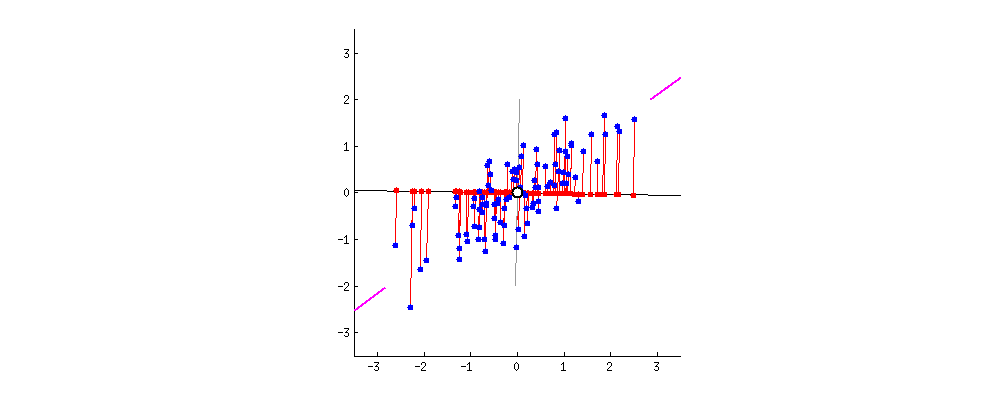
PCA란 차원축소기법중 하나로 말 그대로 "주"성분을 분석하는 것이다.2차원의 데이터가 있을때 이를 하나의 1차원 으로 축소한다고 하였을때 이를 축소할수 있는 방법은 다음과 같다. 출처:https://butter-shower.tistory.com/210이때 P
7.PCA(주성분 분석)

💡차원축소 PCA 설명에 앞서 차원축소의 개념을 먼저 설명하고 가도록하겠다. 아래의 데이터 프레임을 보게되면 총 13개의 열로 13차원의 벡터로 표현된다. 이와 같은 고차원의 데이터는 계산과 시각화가 어려워 분석하기가 쉽지 않다. 따라서 원 데이터의 분포를 가능