성능 개선 : 기존의 StyleGAN보다 더 높은 품질의 이미지를 생성하고, 이미지를 부드럽게 변경할 수 있다.
- 기존 아키텍처의 blob-like artifact와 phase artifact 문제 해결
- inversion(=역함수, 반대로 이미지를 넣어서 latent vector를 찾아내는 것)이 더 잘 동작함
generated image(생성된 가짜이미지)에 대해서는 거의 완벽한 inversion을 수행할 수 있음 → inversion을 기반으로 가짜 이미지와 진짜 이미지를 판별하는 목적으로 활용될 수 있음을 전망
- 이전과 마찬가지로 z → w 매핑 네트워크를 사용한다.
- 기존 아키텍처의 문제점 지적
- AdaIN style transfer → blob-like artifact 발생
- Progressive growing → 얼굴의 특정 부분이 fixed position을 갖는 문제 발생(phase artifact)
이미지를 서서히 변화시킨다고 했을 때 머리카락이나 얼굴모양과 같이 전반적인 얼굴의 스타일이 변해야 하는데 치아나 눈동자 위치 같은 일부 요소의 위치가 변경되지 않고 고정되는 문제 발생
- 성능을 개선하기 위한 방법 제안
- Path length regularization
- w space에서 고정된 만큼 latent vector를 이동시키면 그것이 이미지 space에서도 고정된 만큼의 변화를 일으킬 수 있도록 함
- 결과적으로 latent interpolation에 따라서 이미지가 부드러운(smooth) 변화를 보이게 된다.
- 이미지를 latent vector로 inversion하는 새로운 알고리즘을 제안한다.
(latent vector를 조금씩 바꾸면서 그 이미지의 성별을 바꾸는 등의 작업을 할 수 있다)
- Path length regularization
StyleGAN의 문제 상황
-
Blob-like(Droplet) Artifiacts : 물방울 형태의 인공물
AdaIN의 원인으로 추정됨
생성자에서 대략 64X64에서부터 이런 artifact가 보이기 시작Feature map 상에서
- Droplet artifact가 있는 경우 - 정상적인 이미지 생성, 대부분(99.9%) 결과가 정상
- Droplet artifact가 없는 경우 - Corrupted 이미지 생성, 약 0.1% 확률로 발생
- 해결 : Removing Normalization Artifacts
AdaIn은 각 feature map의 평균/표준편차를 개별적으로 정규화해서 서로 연관된 feature들의 정보가 손실될 수 있음
본 논문에서는 standard deviation만 변경해도 충분하다는 것을 알아냄 standard deviation(표준편차)만 변경하면서, 최대한 style 블락의 외부에서 feature map들의 값을 변경하고자 함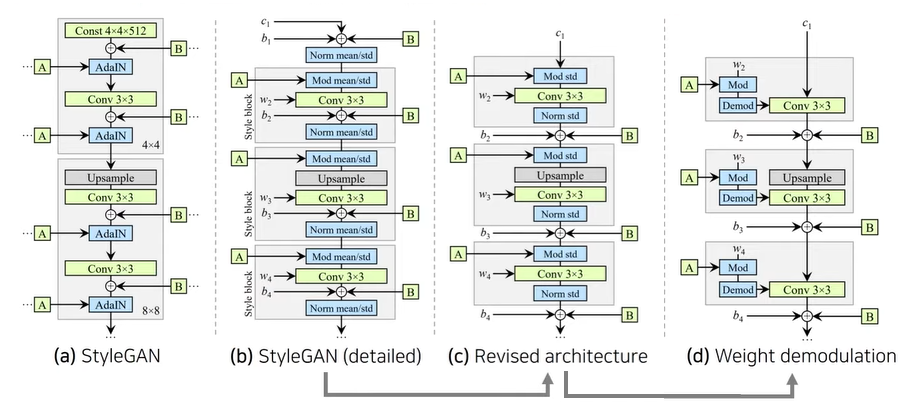
(c) 표준편차만 변경하면서 최대한 style 외부에서 feature map을 변경하기 위해 noise도 블록 밖에서 적용함
(d) 여전히 conv연산의 결과로 나온 feature map의 통계를 직접적으로 변경하기 때문에 바로 modulation하지 않고 weight 값에 대해서 modulation 진행 → 서로 연관된 feature들의 정보를 손상시키는 것을 방지
이렇게 하더라도 여전히 conv연산의 결과로 나온 feature map에서도 직접적으로 statistic을 변경하기 때문에 서로 연관된 feature들의 정보를 손상시킬 수 있음
convolution연산을 거친 feature map에 대해 바로 modulation을 적용하지 않고 weight값에 대하여 modulation을 진행
핵심 아이디어 : 직접적으로 정규화를 하지 않고 feature map의 statistics를 예측하여 정규화를 적용
(Modulation시에 convolution weight를 대신 scaling하는 방법을 사용할 수 있다.)
→ 기존의 AdaIN 기능을 대체하는 것이 가능!
💡 ⇒ 결과적으로 normalizaiton을 demodulation으로 대체하여 blob-like artifact가 제거된 것을 확인할 수 있다. Full controllablity : 아키텍처가 변경되었지만, 여전히 기존과 동일하게 controllability가 있는 네트워크
- weight demodulation이 있는 경우
: 각 스타일이 generator에서 적절히 localized 된다. coarse-grained한 스타일이 고정된 상태로 fine-resolution 스타일이 효과적으로 변경 된다.
- weight demodulation이 없는 경우
: scale-specific하지 않으며, 스타일이 누적된다. high-level과 low-level feature를 적절히 섞기 어렵다. overshooting(급격한 변동) : 특정한 style combination이 artifacts를 생성 leaking : 특정한 feature들이 여러 개의 스타일(배경,인종 등)으로부터 영향을 받음
-
Phase Artifact : Latent manipulation 과정에서 특정 요소(치아 등)가 고정됨
Progressive growing(해상도가 낮은 것부터 학습시키면서 점차 해상도를 높혀가는 것)이 원인으로 추정됨
→ 각 resolution이 output resolution에 즉시 영향을 미침
→ 최대한 높은 frequency detail을 생성하고자 함(frequency가 높다=인접한 픽셀간의 값의 변화가 크다)
(저해상도 파트(4x4)에서 frequency detail이 높은 이미지를 만들었다면, 후반부 레이어에서는 추가적으로 이미지의 디테일을 살리는 방식으로 이미지가 만들어짐 )→치아와 같은 형태를 저해상도에서 완전히 미리 잡아버린다면 형태가 고정되어서 쉽게 변경되지 않을 수 있음
본 논문에서는 progressive growing을 제거해서 phase artifact를 제거함- 원인
PGGAN은 각 resolution마다 충분히 학습을 마치고 다음 resolution을 학습하는데 이때 각 resolution은 output resolution에 대해 최선의 결과를 만들고자 함.
결과적으로 intermediate layer에서 과도한 high frequency detail을 유발함
- 해결 : 단순한 feedforward 네트워크를 사용하는 방식
Progressive growing을 사용하지 않는 본 논문의 3개 아키텍처는 high-resolution 레이어에 의해 크게 영향을 받지 않는 low resolution 이미지를 생성함
점진적으로 레이어를 붙혀나가면서 학습하는 것이 아니라 처음부터 완전한 형태의 아키텍처를 구성한 형태에서 end-to-end로!
(end-to-end : 입력에서 출력까지 '파이프라인 네트워크' 없이 한 번에 처리한다는 뜻이다. (파이프라인 네트워크 : 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태))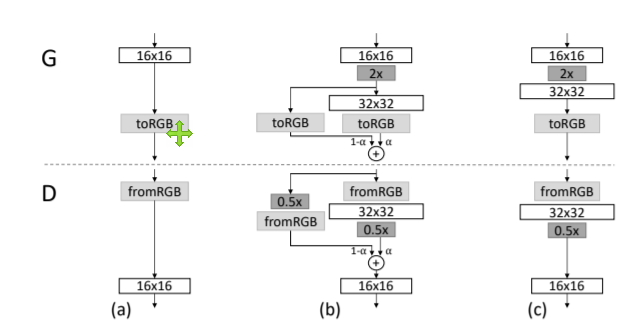
PGGAN
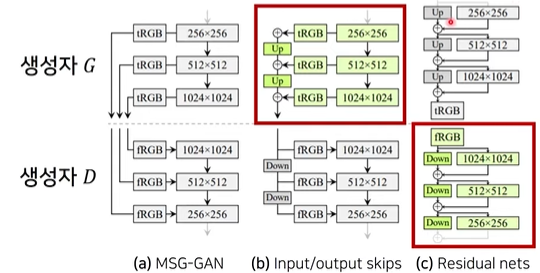
tRGB : 현재 갖고 있는 output tensor에서 채널의 크기를 3으로 바꾸어서 인간이 쉽게 확인할 수 있는 이미지 형태로 바꿔주는 것
fRGB : 이미지 3채널 텐서로부터 입력을 받게 해주는 레이어
- 원인
Image Quality and Generator Smoothness
FID 혹은 Precision & Recall score가 같더라도 PPL에 따라서 image quality가 달라질 수 있다.
PPL이 낮을수록 더 좋은 결과 이미지를 보임
FID나 P&R은 Inception V3나 VGG에서 온 high-level feature에 기반한다. 반면에 인간은 texture보다 shape에 더 큰 영향을 받는다. (예를 들어 인간은 펜으로 단순히 그린 그림도 쉽게 사물로 인식할 수 있다.)
→ PPL이 낮은 방향으로 네트워크를 학습시켜야 결과적으로 더 좋은 퀄리티의 이미지를 만들 수 있다.
PPL을 어떻게 줄일까? ⇒ 단순히 PPL을 줄이기 어려우므로, path length regularizer를 사용
- Lazy Regularization
: 매번 정규화를 진행하는게 아니라 가끔 한번씩 정규화를 진행하자
이렇게 하면 computational resource를 아낄 수 있다.
mini batch마다 한번씩 R1 regularization과 path length regularization을 적용해도 충분! - Path Length Regularization
네트워크가 신뢰할 수 있는 방향으로 동작하도록 만듬
방향과 상관없이 w가 일정하게 움직이는 만큼 G(w)도 일정하게(특정한 length만큼) 움직이게 됨.
→이렇게 생성된 smoother generator가 더욱 inversion이 잘됨
Resolution Usage
: 각 tRGB 레이어가 만드는 output pixel value들의 standard deviation을 비교한다. (standard deviation이 큰 것 = 이미지에 영향을 크게 미침)
높은 해상도로 갈수록 이미지에 미치는 영향이 커야함
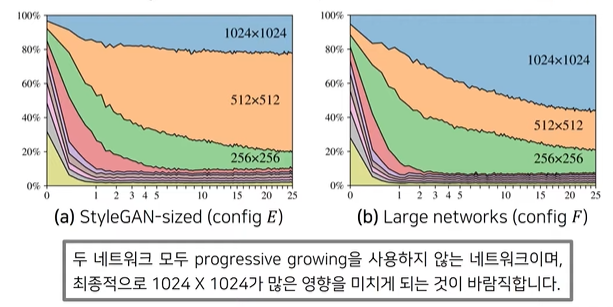
512x512에 비해 1024x1024의 contribution이 낮게 나오는 것은 합리적이지 않음 → 논문의 저자들은 네트워크의 capacity가 부족한 것이 원인이라고 판단!
→ 결과적으로 큰 네트워크(highest-resolution layer의 feature map개수 2배)를 사용해 성능을 끌어올릴 수 있었음! = Highest-resolution layer의 contribution이 증가함!
참고자료 : 나동빈님 강의
