확률분포 : 확률 변수가 특정한 값을 가질 확률을 나타내는 함수
- 이산확률분포 : 확률변수 X의 개수를 정확히 셀 수 있을 때 (Ex. 주사위)
- 연속확률분포 : 확률변수 X의 개수를 정확히 셀 수 없을 때 (Ex. 키)
생성 모델
정의 : 실존하지는 않지만 있을 법한 이미지를 생성할 수 있는 모델
목표
- 이미지 데이터의 분포를 근사하는 모델 G를 만드는 것
- 모델 G가 잘 동작한다는 것은 원래 이미지들의 분포를 잘 모델링할 수 있다는 것 -> 원래 데이터의 분포를 근사할 수 있도록 학습함
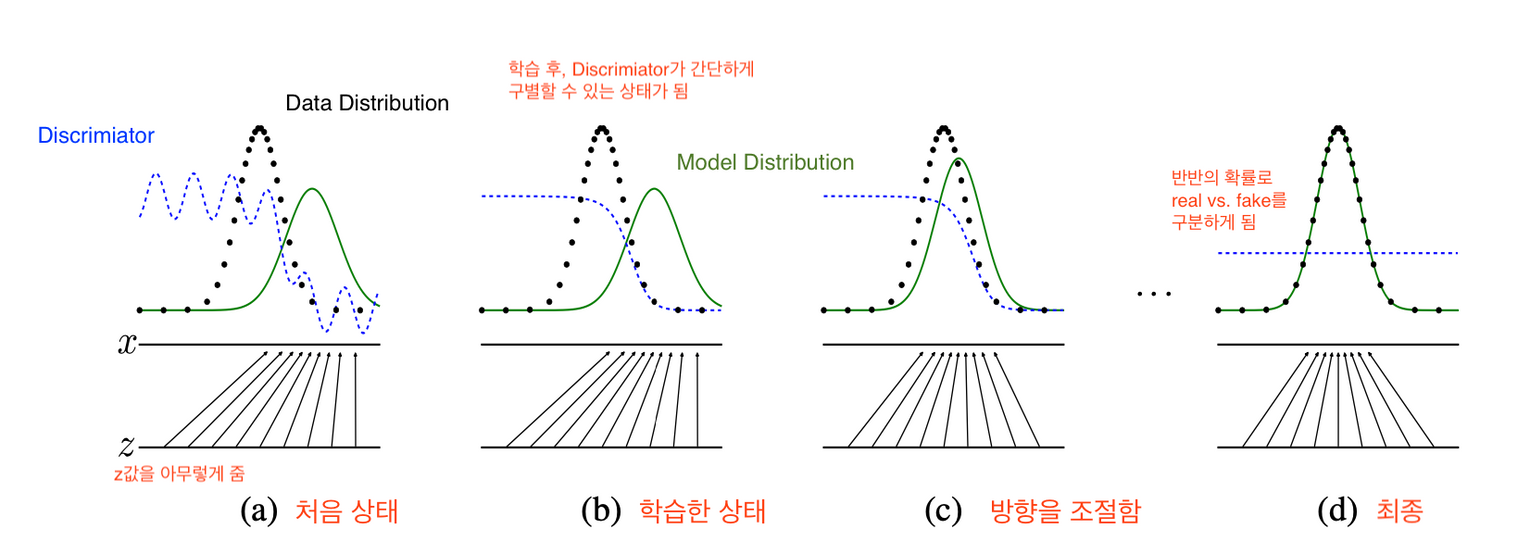
파란 점선 : discriminator distribution (분류 분포) > 학습을 반복하다보면 가장 구분하기 어려운 구별 확률인 1/2 상태가 됨
녹색 선 : generative distribution (가짜 데이터 분포)
검은색 점선 : data generating distribution (실제 데이터 분포)- a에서 G는 sample data의 분포와는 차이가 크다.
- b에서 D가 학습된다.
- C에서 G의 학습된다.
- d는 몇 번의 과정을 거쳐 만들어진 것으로 z로부터 mapping된 G(z)는 sample데이터의 분포와 유사하며 D모델의 판별력은 1/2로 진짜와 가짜를 구별하지 못하고 찍는 이상적인 상태이다.]
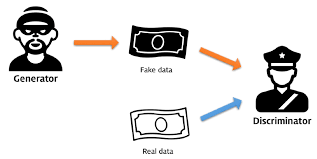
Discriminator 모델은 Supervised Learning이며, Generator 모델은 Unsupervised Learning
Discriminator 모델은 어떠한 input 데이터가 들어갔을 때, 해당 input 값이 어떤 것인지 Classify 하고, Generator 모델은 어떤 latent code(잠재적인 코드)를 가지고 해당 데이터를 가지고 training 데이터가 되도록 학습
즉, Discriminator 은 위조지폐와 진짜 지폐가 input으로 들어갔을 때 이게 진짜(1)인지 가짜(0) 인지를 output으로 주면서 즉 카테고리를 classifying 한다. Generator 모델은 데이터가 흩뿌려져있는 걸 보고 이 데이터가 특정 Training 데이터가 되도록 스스로 변화하며 학습하는 과정
GAN에서는 먼저 Discriminator 모델이 진짜 이미지와, 가짜 이미지를 가지고 진짜 가짜 여부를 구분하도록 학습시킨다.
따라서 들어가는 input은 G(z) 와 x의 차원은 이미지의 경우(64 x 64 x 3) 과 같은 고차원 vetor가 들어가더라도 나오는 값은 0과 1의 값을 가지게 된다.
여기서 0과 1의 값으로 분류할 때는 sigmoid 함수를 써서 0.5를 기준으로 0과 1을 구분하게 된다.
Generator는 Discriminator 가 진짜 이미지를 잘 맞추는지 못 맞추는지에 대해서 관심이 없다. 그냥 본인이 만든 이미지가 얼마나 Discriminator를 속일 수 있냐가 중요하다. Generator 목적은 D(G(z)) 가 1이 되도록 하는 것뿐!
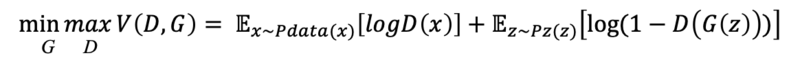
왼쪽에서 G는 V(D, G) 가 최소(min) 가 되려 하고, D는 V(D, G) 최대(max) 가 되려고 함. (log(1) = 0, log(0) = -infinity)
V(D, G) 은 GAN의 Loss 함수, Objective 함수
- Discriminator
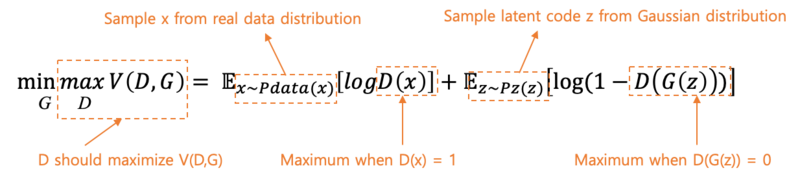 D의 목적은 V(D, G) 가 최대가 되도록 하는 것
D의 목적은 V(D, G) 가 최대가 되도록 하는 것 - D는 경찰이다. 가짜 데이터에는 0을 출력하고, 진짜 데이터에는 1을 출력해야 한다.
- x는 진짜 데이터고, G(z)는 G가 z를 가지고 만든 가짜 데이터이다.
- 따라서 D는 오른쪽 수식 중, D(x) = 1이 되어야 하며, D(G(z))는 0 이 되도록 하는 것이 최대 목표이다.
D가 가장 원하는 상황
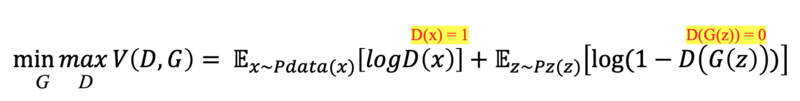
D(x)가 1이 되는 게 D의 목표인데 logD(1)을 하면 0 이다.
⇒ log(1) = 0 이 나오는 게 해당 logD(x) 가 뽑아낼 수 있는 그나마 가장 큰 값!
z = Gaussian Distribution
z는 주로 두 가지 분포에 따른 랜덤 값을 가진다. 위 그림처럼 Gaussian Distribution 또는 Uniform Distribution 을 따른다.
D(G(z))의 경우에도 마찬가지로 0이 되려고 하고, log(1-0), 즉 0이 되는 값이 되려고 한다.
따라서 전체적으로 본다면 그냥 0+0 같은 값이 되지만, 이는 상대적으로 볼 때 D가 V(D, G)를 최대화하기 위해 노력한 값을 말한다.
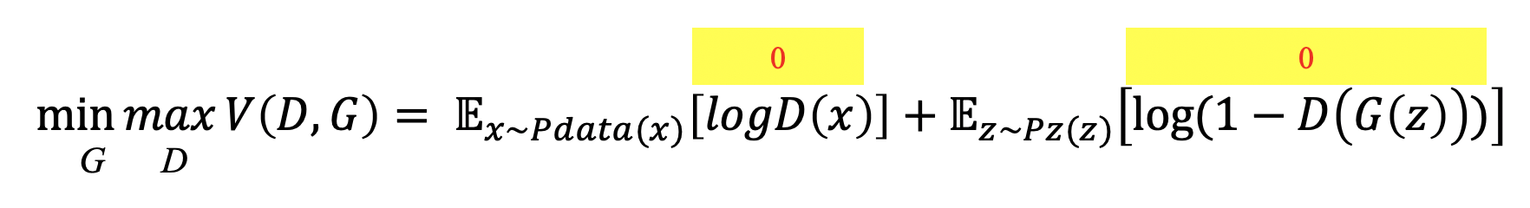
⇒ D가 원하는 최적의 상황은 전부 0이 되는 것!(0보다 작은 수보다는 낫기 때문)
- Generator

G의 목적은 V(D, G) 가 최소가 되도록 하는 것
- G는 위조지폐범이다. 경찰과 반대로 G는 D가 가짜 데이터에 대해 1을 출력하게 해야 한다. D가 진짜 데이터를 제대로 구별하는지 아닌지는 별로 상관이 없다.
- x는 진짜 데이터고, G(z)는 G가 z를 가지고 만든 가짜 데이터이다.
- 따라서 오른쪽 수식 중, D(x) = 0이 되어야 하며, D(G(z))는 1 이 되도록 해야 한다.
G가 원하는 상황은 다음과 같다. 앞에서 D가 어떻게 하는지는 상관이 없다. 다만 뒤에서 D(G(z))가 1이 되게 해야 한다.

log(1-1)으로 인해 log 0 이 된다면 해당 값은 -infinity를 향하게 된다. 이는 0보다 매우 작은 무한대의 음수로, 결국 G의 목표는 엄청 엄청 작은 0 보다 작은 음의 무한대를 향하는 것이 목적
⇒ 따라서 G가 원하는 최적의 상황은 매우 매우 작은 음의 무한대가 방향이 되는 것이다.
장점
Markov chains이 필요없고 역전파만 있으면 된다. G는 data로 부터 직접 업데이트되지 않고 D로 업데이트된다.(input이 직접적으로 G의 파라미터로 copy되지 않는다. 아마 기억에 의한 이미지 생성이 아니라는 의미 같음) 이전의 Markov모델들 보다 sharp한 특징을 잡아낼 수 있다.
한계점
- Mode collapse
분포의 형태를 전반적으로 맵핑하기보다, 단순히 오류를 최소화하기 위해서 최빈값(mode)에만 집중하여 학습해서 실제 값(이미지 등) 중 특정한 형태만 생성
→ mini batch discrimination, feature matching 등 도입 - 어떻게 평가?!
생성된 결과가 잘 생성된 것인지 판단할 지표가 없음 → 학습을 얼마나 진행해야 하는지 명확한 기준이 부족 → inception score(생성된 이미지의 다양성을 측정하는 지표) 사용 - Unstable training
서로 이기려고 하는 minmax 게임을 통해 학습하므로, G와 D간의 힘의 균형이 깨지기 쉬움
